[CVPR 2023] TryOnDiffusion: A Tale of Two UNets
1. Problem Definition
Task Description
Virtual Try-On (VTON), which involves putting a garment on a particular individual, holds crucial significance in contemporary e-commerce and the prospective metaverse. The key challenge lies in preserving intricate clothes texture details along with the target person’s distinctive features. Adapting a garment to different body shapes without modifying patterns is particularly challenging, especially when the body appearance varies significantly.
General related works
In general, when approaching this task, there are often two stages of processing: cloth warping and warped-cloth blending. At the beginning, depending on the types of clothes, the corresponding changeable regions of the person image will be removed. Specifically, this mechanism is that if the garment is upper types, the upper regions of the body are omitted, which works the same as the lower types and dresses – the full body types.
In terms of warping phases, the garment information and body appearance are pushed into several algorithms to learn the relative to predict a transformation matrix supporting to generate the most suitable body-fit warped garment. Subsequently, the warped garment is directly added to the person image which has already been removed from the changeable region, then the final output is generated after the calculation - warped-cloth blending phases.
This type of process is quite common in recent VTON:
[1] : Fele, Benjamin, et al. “C-vton: Context-driven image-based virtual try-on network.” Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2022. Link
[2] : Lee, Sangyun, et al. “High-resolution virtual try-on with misalignment and occlusion-handled conditions.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022. Link
[3] : Choi, Seunghwan, et al. “Viton-hd: High-resolution virtual try-on via misalignment-aware normalization.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021. Link
[4] : Xie, Zhenyu, et al. “Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. Link
2. Motivation
Almost all the recent previous studies use explicit wapring pharse - mentioned aboved.
In my opinion, this is a limitation of the whole process because during the training phase of the warping module the targets, which are used for losses calculation and backpropagation, are extracted from another segmenation model. It means that the explicit warping model performance is always underbound the segmentation model used for human parsing.
In addition, all the mentioned aboved work with GAN-based or flow-based model.
Meanwhile, in general task recent diffusion-based approaches are proven to be the current state-of-the-art methods in both quantitative and qualitative assessment.
“whether or not exist an approach using Diffusion model?” - just to guide the reader
Take advantages of generative ability of Diffusion model, this paper focus on the task of garment detail preservation without effective pose and shape variation, or allow try-on with the desired shape and pose but lack garment details in a single network.
3. Method
In this paper, the author propose a diffusion-based architecture that unifies two UNets (referred to as Parallel-UNet), which allows us to preserve garment details and warp the garment for significant pose and body change in a single network.
The key ideas behind Parallel-UNet include: 1) garment is warped implicitly via a cross attention mechanism, 2) garment warp and person blend happen as part of a unified process as opposed to a sequence of two separate tasks.
To find out the idea behind the implicity warping mechanism, we need to focus on the warping argorithm which known as the Thin Plate Spline. This algorithm could easily explain as a scale and transition opertation. In previous study, the warping model will try to predict an tranformation matrix to operate this argorithm on picture space or in RGB space. Meanwhile, to unified two model, this process also could also be operated under latent space by adding condition information supporting the implicit warp phase. Latent space is more rubust than RGB space
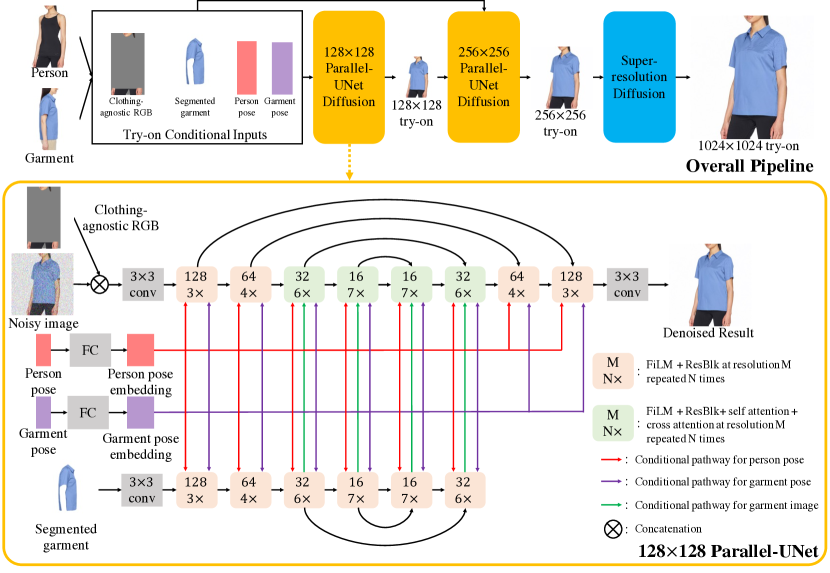
Figure 1: Overall pipeline (top): During preprocessing step, the target person is segmented out of the person image creating “clothing agnostic RGB” image, the target garment is segmented out of the garment image, and pose is computed for both person and garment images. These inputs are taken into 128x128 Parallel-UNet (key contribution) to create the 128x128 try-on image which is further sent as input to the 256x256 Parallel-UNet together with the try-on conditional inputs. Output from 256x256 Parallel-UNet is sent to standard super resolution diffusion to create the 1024x1024 image. The architecture of 128x128 Parallel-UNet is visualized at the bottom, see text for details. The 256x256 Parallel-UNet is similar to the 128 one.
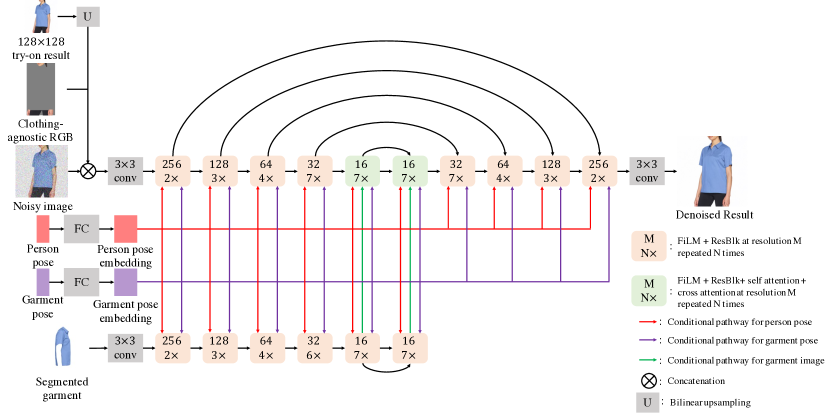
Figure 2: Architecture of 256x256 Parallel-UNet
Preprocessing of inputs
Note that clothing-agnostic RGB described in VITON-HD [6] leaks information of the original garment for challenging human poses and loose garments. The authors thus adopt a more aggressive way to remove the garment information. Specifically, they first mask out the whole bounding box area of the foreground person, and then copy-paste the head, hands and lower body part on top of it.
They use Human Parsing Map and 2D keypoints to extract the non-garment body parts. They also normalize pose keypoints to the range of [0, 1] before inputting them to networks.
Cascaded Diffusion Models for Try-On
Their cascaded diffusion models consist of one base diffusion model and two super-resolution (SR) diffusion models.
The base diffusion model is parameterized as a 128×128 Parallel-UNet. It predicts the 128×128 try-on result, taking in the try-on conditional inputs. The 128×128→256×256 SR diffusion model is parameterized as a 256×256 Parallel-UNet. It generates the 256×256 try-on result by conditioning on both the 128×128 try-on result and the try-on conditional inputs at 256×256 resolution. The 256×256→1024×1024 SR diffusion model is parameterized as Efficient-UNet introduced by Imagen. This stage is a pure super-resolution model, with no try-on conditioning.
Parallel-UNet
The 128×128 Parallel-UNet can be represented as:
$\epsilon_t = \epsilon_\theta(z_t,t,c_{tryon},t_{na})$
where $t$ is the diffusion timestep, $𝐳_t$ is the noisy image corrupted from the ground-truth at timestep $t$, $𝐜_{tryon}$ is the try-on conditional inputs, $𝐭_na$ is the set of noise augmentation levels for different conditional images, and $\epsilon_t$ is predicted noise that can be used to recover the ground-truth from $𝐳_t$.
Implicit warping
“how can we implement implicit warping in the neural network?” One natural solution is to use a traditional UNet and concatenate the segmented garment $I_c$ and the noisy image $z_t$ along the channel dimension. However, channel-wise concatenation can not handle complex transformations such as garment warping. This is because the computational primitives of the traditional UNet are spatial convolutions and spatial self attention, and these primitives have strong pixel-wise structural bias.
Implicit warping using cross attention mechanism between streams of information:
$Attention(Q,K,V) = softmax(\frac{QK^\top}{d})V$
where $Q \in \mathbb{R}^{M \times d}, K \in \mathbb{R}^{N \times d}, V \in \mathbb{R}^{N \times d}$ are stacked vectors of query, key and value, $M$ is the number of query vectors, $N$ is the number of key and value vectors and $d$ is the dimension of the vector. In this case, the query and key-value pairs come from different inputs. Specifically, $Q$ is the flattened features of $z_t$ and $K$, $V$ are the flattened features of $I_c$.
The attention map $\frac{QK^\top}{d_k}$ computed through dot-product tells us the similarity between the target person and the source garment, providing a learnable way to represent correspondence for the try-on task.
Combining warp and blend in a single pass
Instead of warping the garment to the target body and then blending with the target person as done by prior works, we combine the two operations into a single pass. As shown in Figure 1, they achieve it via two UNets that handle the garment and the person respectively.
The person and garment poses are necessary for guiding the warp and blend process. They are first fed into the linear layers to compute pose embeddings separately. The pose embeddings are then fused to the person-UNet through the attention mechanism, which is implemented by concatenating pose embeddings to the key-value pairs of each self attention layer. Besides, pose embeddings are reduced along the keypoints dimension using CLIP-style 1D attention pooling, and summed with the positional encoding of diffusion timestep $t$ and noise augmentation levels $t_{na}$. The resulting 1D embedding is used to modulate features for both UNets using FiLM across all scales.
In my opinion, the application of FiLM is the operation that the most similar to warping mechanism (Scale and transition operation in the latent space) and can be applied in all latent resolution. Meanwhile, Cross Attention is really parameter consuming that why it is only applied at low resolution latent space to save the parameter. Combine both of them, we can get a realy powerful way of injecting or combining feature from other models.
4. Experiment
Experiment setup
Dataset
The authors collect a paired training dataset of 4 Million samples. Each sample consists of two images of the same person wearing the same garment in two different poses. For test, they collect 6K unpaired samples that are never seen during training. Each test sample includes two images of different people wearing different garments under different poses. Both training and test images are cropped and resized to 1024x1024 based on detected 2D human poses. Our dataset includes both men and women captured in different poses, with different body shapes, skin tones, and wearing a wide variety of garments with diverse texture patterns. In addition, we also provide results on the VITON-HD dataset.
Evaluation Metric
They compute Frechet Inception Distance (FID) and Kernel Inception Distance (KID) as evaluation metrics.
Comparison with other methods.
They compare their approach to three methods: TryOnGAN, SDAFN and HR-VITON. For fair comparison, they re-train all three methods on our 4 Million samples until convergence. Without re-training, the results of these methods are worse. Released checkpoints of SDAFN and HR-VITON also require layflat garment as input, which is not applicable to our setting. The resolutions of the related methods vary, and they present each method’s results in their native resolution: SDAFN’s at 256x256, TryOnGAN’s at 512x512 and HR-VITON at 1024x1024.
Result
The proposed models surpassed all the previous methods quantitatively.
Quantitative Result



5. Conclusion
The proposed method that allows to synthesize try-on given an image of a person and an image of a garment, are overwhelmingly better than state-of-the-art, both in the quality of the warp to new body shapes and poses, and in the preservation of the garment.
A novel architecture Parallel-UNet, where two UNets are trained in parallel and one UNet sends information to the other via cross attentions
This project only focus on upper clothes.
In my opinion, the key idea lies on cross-attention and FiLM - Feature-wise transformations, an parameter-efficient method to injecting the embeding information to the model. The used of implicited warping removed the underbound of previous methods.
6. Limitation
The limitation of this paper is identity preservation problem. The tryon model can not retain the identity feature of the reference person (tattoos, muscle structure, accessories). Examples are showcased below.

Author Information
- (Hoang) Phuong Dam
- AutoID LAB, School of Computing
- Image Generation, Virtual TryOn
6. Reference & Additional materials
Please write the reference. If paper provides the public code or other materials, refer them.
-
Github Implementation of Tryon Diffusion: here (No official code is released, a group of people try to reproduce that.)
-
Reference:
[1] : Fele, Benjamin, et al. “C-vton: Context-driven image-based virtual try-on network.” Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2022. Link
[2] : Lee, Sangyun, et al. “High-resolution virtual try-on with misalignment and occlusion-handled conditions.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022. Link
[3] : Choi, Seunghwan, et al. “Viton-hd: High-resolution virtual try-on via misalignment-aware normalization.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021. Link
[4] : Xie, Zhenyu, et al. “Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. Link
[5] : Bai, Shuai, et al. “Single stage virtual try-on via deformable attention flows.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022. Link
[6] : Lewis, Kathleen M., Srivatsan Varadharajan, and Ira Kemelmacher-Shlizerman. “Tryongan: Body-aware try-on via layered interpolation.” ACM Transactions on Graphics (TOG) 40.4 (2021): 1-10. Link
[7] : Dumoulin, Vincent, et al. “Feature-wise transformations.” Distill 3.7 (2018): e11. Link