[ACL 2022] M-SENA: An Integrated Platform for Multimodal Sentiment Analysis
0. About Multimodal Sentiment Analysis
감성 분석(Sentiment Analysis)이란, 텍스트에서 감정이나 의견을 식별하고 분류하는 과정을 말한다. 주로 자연어 처리(NLP) 기술을 활용하여 텍스트가 긍정적, 부정적, 또는 중립적인 감정을 담고 있는 지 파악하는 것이 목표이다. 하지만 언어 매체와 전달의 다양성 (예를 들어, 텍스트 상으로는 긍정적이나 표정과 목소리는 부정적 - 반어법, 문화에 따라 같은 언어의 의미 전달이 달라짐) 때문에 텍스트만으로 다소 부정확한 경우가 많았기에 영상 매체 등을 함께 활용하여 의미를 해석하려는 시도가 이루어졌다. 이처럼 텍스트 뿐만 아니라 사람으로부터 발생하는 다양한 비언어적 정보를 활용하여 감정이나 의견을 식별하는 것이 Multimodal Sentiment Analysis(이하 MSA)이다.
감성 분석 세 가지 주요 방식
- 극성 감성 분석 (Polarity-based Sentiment Analysis): 해당 데이터가 긍정적인지, 부정적인지 분류
- 감성 스코어링 (Sentiment Scoring): 데이터에 대한 감성을 수치적 점수로 표현 ex.행복 : 0.4, 기쁨 : 0.2…
- 감정 분석 (Emotion Analysis): 단순한 긍정/부정 이상의 감정, 예를 들어 행복, 슬픔 등을 감지
해당 플랫폼의 경우, 모델 간의 성능 비교를 위해 긍정 혹은 부정으로 예측하는 방식을 사용하였으며 행복, 기쁨 등은 긍정, 슬픔, 분노 등은 부정으로 분류하였다.
감성 분석 모델 학습 방식
- 데이터 수집 : 사람들에게서 수집된 문장, 영상, 오디오 정보와 감성 라벨 수집.
- 데이터 전처리 : 각 모달리티(텍스트, 오디오, 비디오)에 대해 필요한 전처리 작업을 수행. 예를 들어, 텍스트는 토큰화와 정제 과정을 거치고, 오디오는 특성 추출을 위해 샘플링 레이트를 조정하며, 비디오에서는 얼굴 인식을 통해 필요한 프레임을 추출.
- 특성 추출
- 텍스트: TF-IDF, 워드 임베딩(Word2Vec, GloVe, BERT) 등 자연어 처리 기술을 사용하여 텍스트에서 언어적 특성을 추출.
- 오디오: 오디오 신호에서 음성의 피치, 에너지, 멜 주파수 켑스트럴 계수(MFCC)와 같은 오디오 특성을 추출.
- 비디오 : 컴퓨터 비전 기술과 이미지 처리 알고리즘 등을 활용하여 얼굴 표정, 몸짓, 시선 등의 비주얼 특성을 추출
- 모델 학습 : 머신러닝, 딥러닝 알고리즘을 활용하여 특성 정보를 학습하고 감성 예측 및 모델 최적화.
- 성능 평가 : 정확도, 재현율, F1 스코어 등을 활용하여 성능 평가.
추가로 모델이 학습하거나 예측할 때, 추출한 여러 특성 정보들을 통합(Fusion)하는 과정이 필요한데 Fusion 방식에는 크게 3가지가 있다.
- Early Fusion : 모든 모달리티의 데이터를 하나의 대표적인 특성 벡터로 통합한 후, 단일 모델로 학습.
- Late Fusion : 각 모달리티를 독립적으로 분석하고, 각 모델의 출력을 결합하여 최종 예측을 수행.
- Hybrid Fusion : Early Fusion과 Late Fusion을 혼합하여 사용.
- Ex. 일부 특성 정보(관련성이 높거나 함께 고려해야 의미가 있는 정보 등)는 Early Fusion을 통해 학습한 뒤 다른 정보와 Late Fusion을 수행.
감성 분석 응용 분야
- 마케팅 및 브랜드 관리: 제품 리뷰, 소셜 미디어 글, 고객 피드백 등에서 브랜드에 대한 소비자의 감정을 분석
- 금융 시장 분석: 뉴스 기사, 유튜브 등에 게시된 투자자의 의견에서 시장의 감성을 분석
- 정치적 분석: 선거 기간 동안 후보자에 대한 여론이나 감성의 변화를 추적
- 고객 서비스: 고객의 문의나 불만 사항에 대한 감성을 분석
1. Introduction
최근 통신 매체와 영상 관련 플랫폼의 발달로 user-generated 온라인 콘텐츠(예 : 인스타그램, 유튜브 등)의 수가 폭발적으로 증가하였다. 이에 따라 사용자 수도 꾸준히 증가하고 있으며 해당 플랫폼에 업로드되는 영상들의 파급력 또한 커지게 되었다. 이 영상들의 정보와 반응을 학술적 혹은 상업적으로 활용하기 위해 영상에 포함된 다양한 정보들을 추출 및 조합하여 감성을 분석하는 Multimodal Sentiment Analysis (이하 MSA) 연구가 활발하게 진행되고 있다. 그러나 연구를 통해 MSA 성능에 많은 향상이 있었지만 여전히 보완해야할 부분이 많이 남아있다.
본 논문에서는 크게 두 가지 challenge에 대해서 소개하고 있다.
1. 효과적인 음향 및 시각 정보 추출과 모델 간의 공정한 비교
이전에는 멀티모달 분석을 위해 카네기멜론 대학교 연구자들이 개발한 CMU-MultimodalSDK 키트로 연구를 시도하였다. 하지만 영상의 실제 정보와 완전히 일치하는 음향 및 시각 정보를 추출하는 것은 feature selection과 backbone selection의 모호함 때문에 거의 불가능에 가깝다. 게다가 최근 감성 분류 연구에서는 음향, 시각 정보보다 텍스트 정보가 압도적인 영향력을 가지고 있어 음향 및 시각 정보를 효과적으로 추출하고 활용하기 위한 연구가 주목 받게 되었다. 이에 따라 연구자들은 음향 및 시각에 대해서 주어진 정보가 아닌 Customized modality를 활용하여 모델을 구축하는 것을 시도하고 있다. 하지만 각자 다른 modality feature들을 활용한 모델들의 성능과 fusion method를 비교하는 것은 공정하지 못하기 때문에 이를 공정하게 비교할 수 있는 방법이 필요하다.
2. 기존 MSA 모델을 실제 시나리오에 적용할 때 종합적인 모델 평가 및 분석 접근법의 부재
주어진 test dataset에 대해 뛰어난 성능을 보인 모델도 실제 시나리오에서는 distribution discrepancy나 random modality perturbations로 인해 제대로된 성능을 내지 못하게 된다. 또한, 연구자들이 개선 사항을 설명하고 모델을 수정하는 데에는 다양한 상황을 포함한 효과적인 모델 분석 방법이 필요하다.
이 두 가지를 해결하기 위해 본 논문에서는 The Multimodal SENtiment Analysis platform(이하 M-SENA)를 제시한다. M-SENA는 다음과 같은 기능을 제공한다.
- 음향 및 시각 정보 추출을 위해 Librosa, OpenSmile, OpenFace, MediaPipe을 통합하였고 맞춤화된 특성 추출 제공.
- 모듈화된 MSA 파이프라인을 통해, 다양한 모달리티와 fusion method를 포함한 모델 간의 공정한 비교 가능.
- 연구자들이 MSA 모델들을 평가하고 분석할 수 있도록 중간 결과 시각화, 실시간 시연, 일반화 성능 분석 툴 제공
2. Platform Architecture
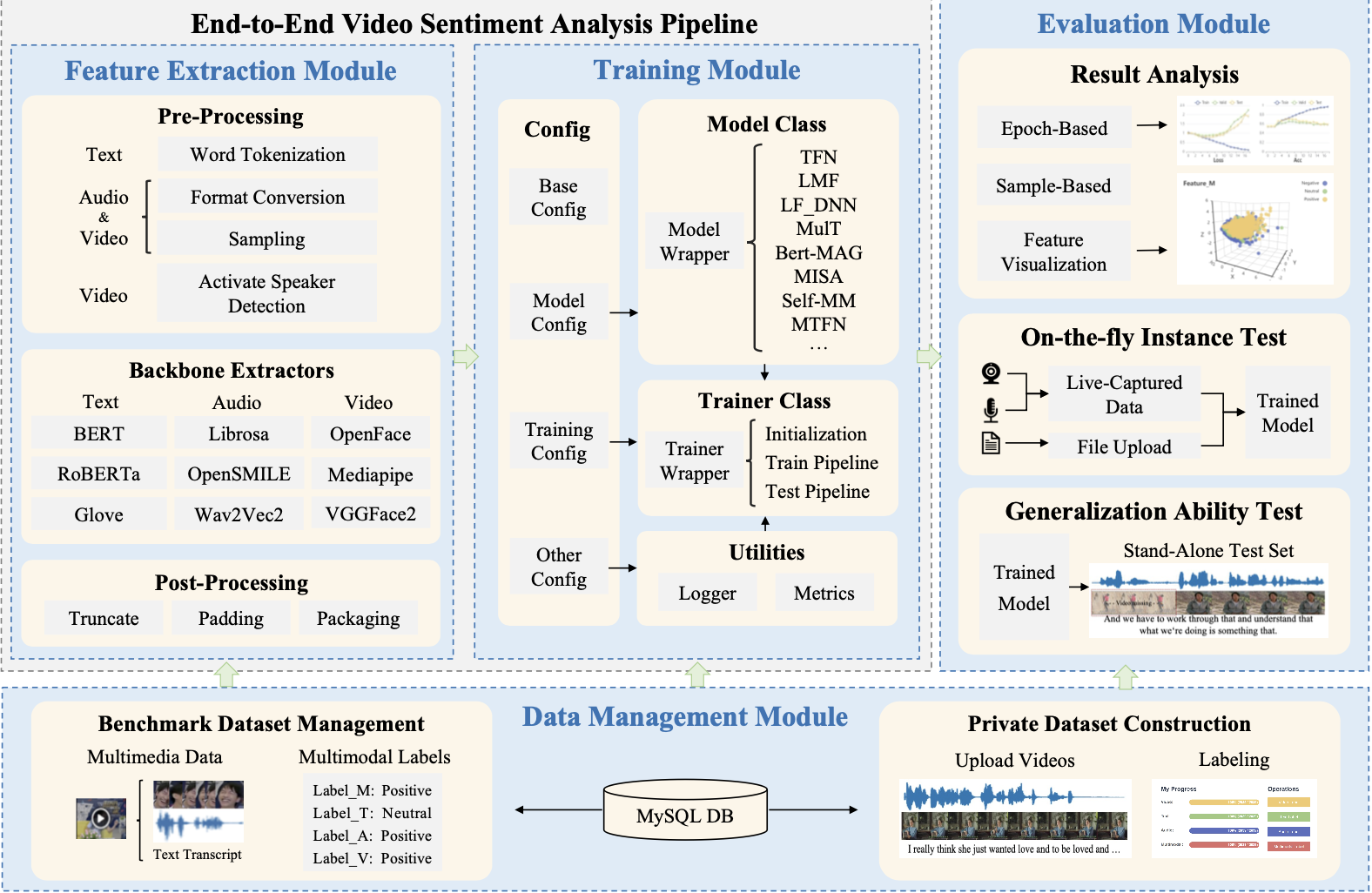
M-SENA 플랫폼은 데이터 관리, 특성 추출, 모델 학습 그리고 결과 분석, 총 4개의 모듈을 제공한다.
2.1 데이터 관리 모듈
잘 알려진 MSA 벤치마크 데이터셋(CMU-MOSI, CMU-MOSEI, CH-SIMS)에 대해 로컬 환경에 다운로드하지 않고도 raw video 파일들을 볼 수 있도록 하였다. 또한 연구자들이 자신만의 데이터셋을 구축할 수 있는 그래픽 인터페이스를 제공하였다.
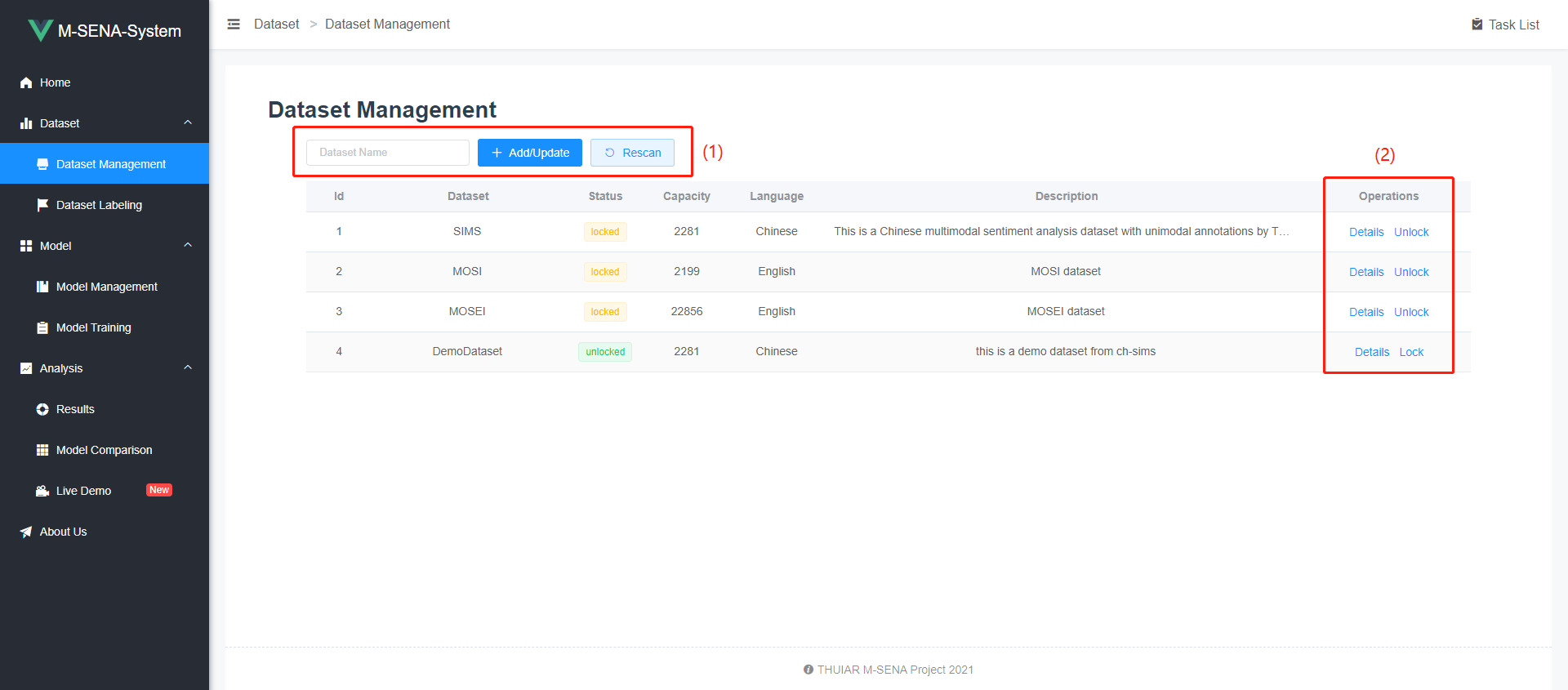
-
CMU-MOSI : YouTube에서 수집된 93개의 비디오 클립에서 2199개의 문장 단위 발화가 포함되어 있는 데이터셋. 감성과 의견의 강도를 분석하기 위한 멀티모달 데이터셋이며 각 발화에 대해 긍정, 부정, 중립의 감성 라벨을 제공하고 감성의 강도(예를 들어, 매우 긍정적, 약간 긍정적 등)를 -3부터 +3의 범위로 평가.
-
CMU-MOSEI : CMU-MOSI의 확장 버전으로, 23,500개의 문장과 250명의 YouTube 동영상 스피커로부터 수집된 데이터를 포함. 각 문장은 여섯 가지 기본 감정(행복, 슬픔, 놀람, 분노, 혐오, 공포)과 감성(긍정, 부정, 중립)에 대해 라벨링되어 있다.
-
CH-SIMS : 중국어 멀티모달 감성 분석 데이터셋으로, 자연스럽게 발생하는 대화에서 수집된 오디오와 비디오 데이터를 포함. 300명의 중국어를 모국어로 사용하는 사람으로부터 수집되었으며, 9가지 감정 상태(행복, 슬픔, 놀람, 분노, 공포, 혐오, 중립, 공포, 긴장)를 포함하고 있다.
2.2 특성 추출 모듈
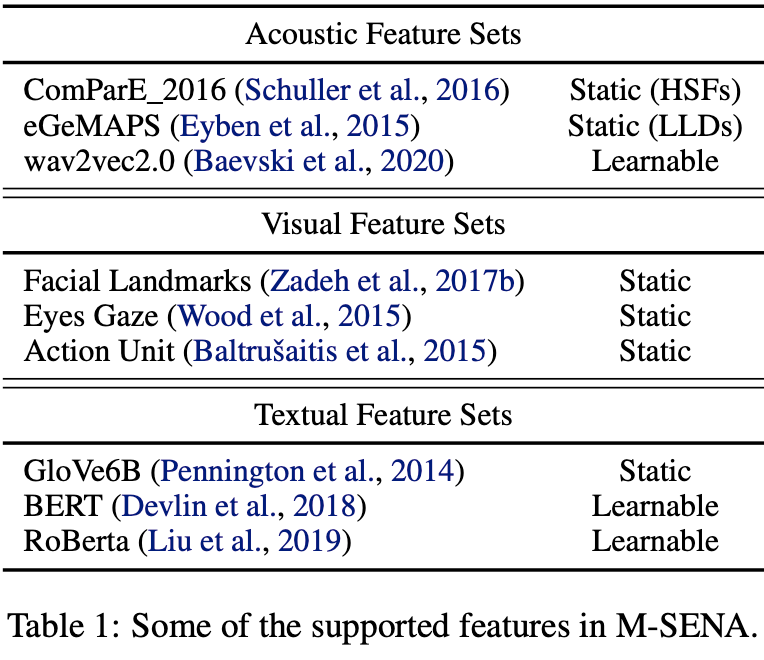
음향(acoutstic), 시각(visual), 문자(text)의 특성 추출을 용이하게 하기 위해 여러 특성 추출 툴을 통합하여 API를 제공한다. 각 특성에 대해서 다음과 같은 툴을 지원한다.
아래 코드는 해당 논문에서 제시하는 MMSA Python API를 활용해 MOSI 데이터셋에서 librosa 툴로 음향 특성을 추출하고 pickle 파일에 저장하는 예시이다.

2.3 모델 학습 모듈
M-SENA 플랫폼에서는 여러 연구자들을 통해 제안된 총 18개의 학습 모델(본 논문에서는 14개였으나 업데이트를 통해 추가되었음.)을 API 형식으로 제공한다. 또한 모델 학습도 특성 추출과 마찬가지로 다음과 같이 간단한 코드로 학습을 진행할 수 있다.
모델 리스트 : TFN, EF_LSTM, LF_DNN, LMF, MFN, Graph-MFN, MulT, MFM, MLF_DNN, MTFN, MLMF, SELF_MM, BERT-MAG, MISA, MMIM, BBFN(Work in Progress), CENET, TETFN.

- TFN (Tensor Fusion Network) : 텍스트, 오디오, 비디오 데이터를 Early Fusion하는 방식으로, 각 모달리티의 모든 가능한 상호작용을 고려. 초기 통합 모델.
- EF_LSTM (Early Fusion Long Short-Term Memory) : LSTM 네트워크에 Early Fusion을 적용한 모델로, 시간적인 데이터(예: 비디오, 오디오) 처리에 유리. 시계열 데이터에서의 감성 패턴을 학습.
- LF_DNN (Late Fusion Deep Neural Network) : 각 모달리티를 독립적으로 처리한 후 결과를 결합하는 Late Fusion 방식의 딥 뉴럴 네트워크. 모달리티 간의 독립성 유지.
- LMF (Low-rank Multimodal Fusion) : 다양한 모달리티를 효율적으로 통합하기 위해 저차원 공간에서의 데이터 표현을 학습. 계산 효율성 개선 모델.
- MFN (Memory Fusion Network) : 각 모달리티의 데이터를 처리할 때 메모리 구조를 사용하여 시간에 따른 정보를 유지. 시간적 동기를 가진 멀티모달 데이터에서 감성의 변화 포착 목적.
- Graph-MFN : MFN에 그래프 이론을 적용하여 모달리티 간의 복잡한 관계와 구조를 모델링. 데이터 간의 비선형 관계와 상호작용 분석 및 적용 목적.
- MulT (Multimodal Transformer) : 트랜스포머 아키텍처를 멀티모달 데이터에 적용하여, 각 모달리티 간의 복잡한 상호작용을 학습.
- MFM (Multimodal Factorization Model) : 다차원 데이터를 저차원 공간에서 분해하여 처리. 모델의 복잡도를 줄이면서도 효율적인 데이터 표현 목적.
- MLF_DNN (Multi-Level Fusion Deep Neural Network) : 다양한 수준(기본적인 정보부터 다른 정보와의 상호작용이 적용된 정보)의 데이터 통합을 통해 각 모달리티의 정보를 최대화.
- MTFN (Multimodal Tensor Fusion Network) : 기존 Fusion 방식이 아닌 텐서 기반의 고차원 데이터 상호작용 통합 모델링.
- MLMF (Multi-Level Multimodal Fusion) : 다양한 수준에서 데이터를 통합하며, 각 레벨에서의 특성을 다르게 처리.
- SELF_MM (Self-Attention Multimodal Model) : Self-Attention 메커니즘을 이용하여 각 모달리티의 중요한 특성을 동적으로 선택.
- BERT-MAG (BERT Multimodal Adaptation Gateway) : BERT를 기반으로 하여 멀티모달 데이터를 처리할 수 있도록 확장한 모델. Adaptation Gateway를 통해 텍스트가 아닌 다른 모달리티 데이터를 Bert 모델 프레임워크에 맞게 조정하고 적응한 뒤, 상호작용 모델링.
- MISA (Modality-Invariant and -Specific Representations) : 특정 감정에 대해 표정, 음성, 언어 표현 등 다양한 모달리티에서 비슷한 방식으로 나타날 수 있는 불변적 표현과 각 모달리티가 고유하게 가지고 있는 고유한 정보를 학습하여 감성 분석을 수행하는 모델.
- MMIM (Multimodal Mutual Information Maximization) : 서로 다른 모달리티에서 제공하는 정보의 중복과 보완적 특성을 이용해 특성 간의 상호 정보를 최대한으로 활용하는 방식으로 학습하여 분석하는 모델.
- BBFN : 현재 개발 중인 미완성 모델.
- CENET (Contextual Emotion Network) : 모달리티 데이터에 대해 감정의 맥락적 요소를 집중적으로 분석하여 감성 분석을 수행하는 모델.
- TETFN (Triple Excitation Transfer Fusion Network) : 오디오, 비주얼, 텍스트 모달리티 간에 정보를 전달하여 이 과정에서 각 모달리티가 서로를 자극하는 Excitation(흥분 전달) 메커니즘을 사용.
2.4 결과 분석 모듈
- 중간 결과 시각화 : M-SENA 플랫폼은 최종 멀티모달 fusion 결과를 기록하고 PCA를 적용한 뒤 각 특성에 대해 출력하여 다른 fusion method들에 관한 평가를 할 수 있도록 한다.
- 실시간 시연 : 실시간 시연을 통해 연구자들이 선택된 모델의 effectiveness와 robustness를 평가할 수 있게 한다.
- 일반화 성능 분석 : 제공되는 벤치마크 MSA 데이터셋이 아닌 실제 시나리오는 더욱 복잡하기 때문에 Noise나 Missing에 대해서 robust해야 한다. 이를 위해 M-SENA 플랫폼에서는 아래 표와 같이 다양한 시나리오와 유형을 포함하는 데이터를 제공하여 robustness를 평가할 수 있게 하였다.
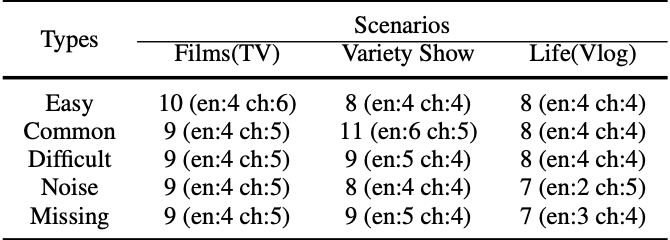
(en : English, ch : Chinese)
3. Experiment
3.1 모달리티 특성 추출 조합에 따른 모델 성능 비교
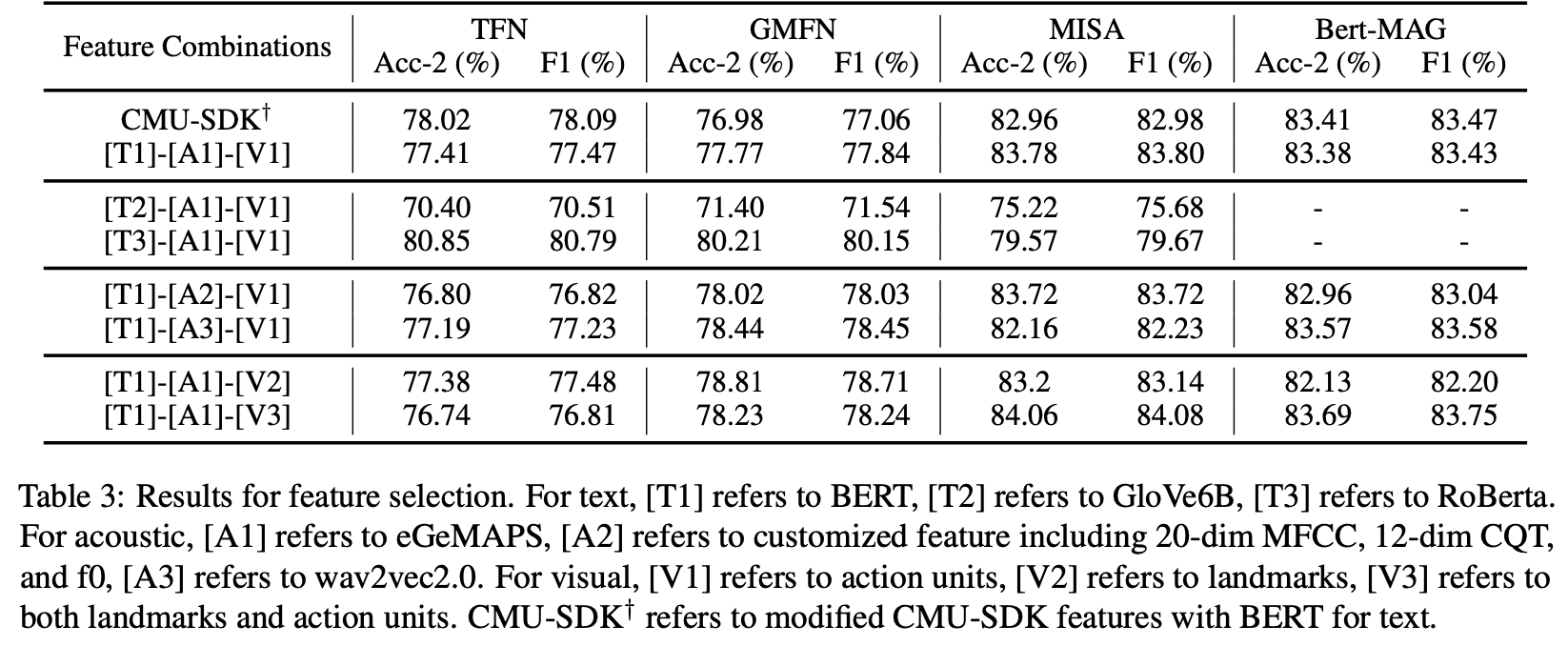
위 표는 플랫폼을 활용하여 다양한 특성 조합에 대해 각 모델별 성능을 나타낸 것이다. 위 결과에 따르면 Bert-MAG 모델의 경우, 문자 특성에 대해 오직 Bert로만 수행되기 때문에 GloVe6B(T2), RoBerta(T3)에 대해서는 성능 측정이 불가했고 T1을 기준으로 eGeMAPS(A1)과 V3를 조합했을 때 성능이 가장 잘 나왔다. TFN과 GMFN 모델에서는 Roberta(T3)를 사용했을 때 성능이 가장 좋았고 MISA 모델은 Bert(T1)를 사용했을 때 성능이 가장 좋았다. 결과적으로 CMU-MultimodalSDK를 그대로 사용했을 때보다는 각 모델에 맞는 특성 조합을 찾아내 사용하는 것이 중요하다고 할 수 있다.
3.2 모델과 데이터셋에 따른 성능 비교
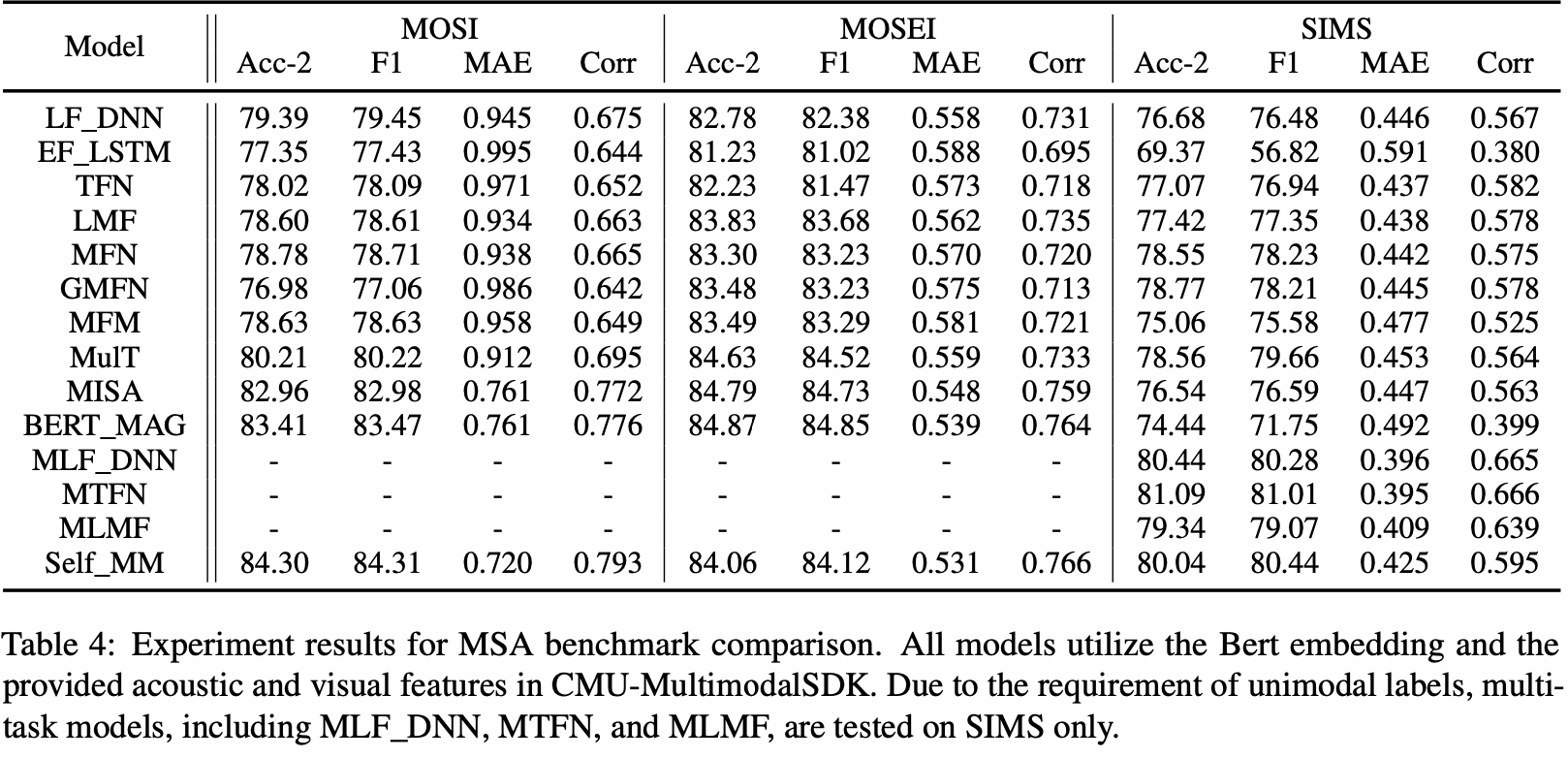
위 표는 동일한 특성 조합(Bert와 CMU-Multimodal SDK)을 활용해 모델과 벤치마크 데이터셋을 기준으로 정확도, F1-Score, MAE, Corr를 나타낸 것이다. MLF_DNN, MTFN, MLMF의 경우 단일 모달에 대해서도 라벨을 필요로 하기 때문에 MOSI와 MOSEI 벤치마크 데이터셋에 대해서는 성능 평가를 하지 못하였다.
MISA와 BERT_MAG 모델이 MOSI와 MOSEI 데이터셋에 대해 전체적으로 좋은 성능을 보였으나 SIMS 데이터셋에는 성능이 다소 떨어지는 모습을 보였다. 또한 SIMS 데이터셋에 대해서는 본 논문의 저자가 과거에 제안한 MLF_DNN, MTFN, MLMF, Self_MM 모델이 좋은 성능을 보였으며 특히 Self_MM 모델의 경우 MOSI, MOSEI에 대해서도 좋은 성능을 보였다.
4. Model Anaysis Demonstration
4.1 중간 결과 분석
중간 결과 분석 모듈은 훈련 과정을 모니터링하고 시각화하기 위해 설계되었다. 아래 그림은 MOSI 데이터셋을 TFN 모델에 학습시키고 중간 결과 분석 모듈을 활용하여 결과를 시각화한 것이다.
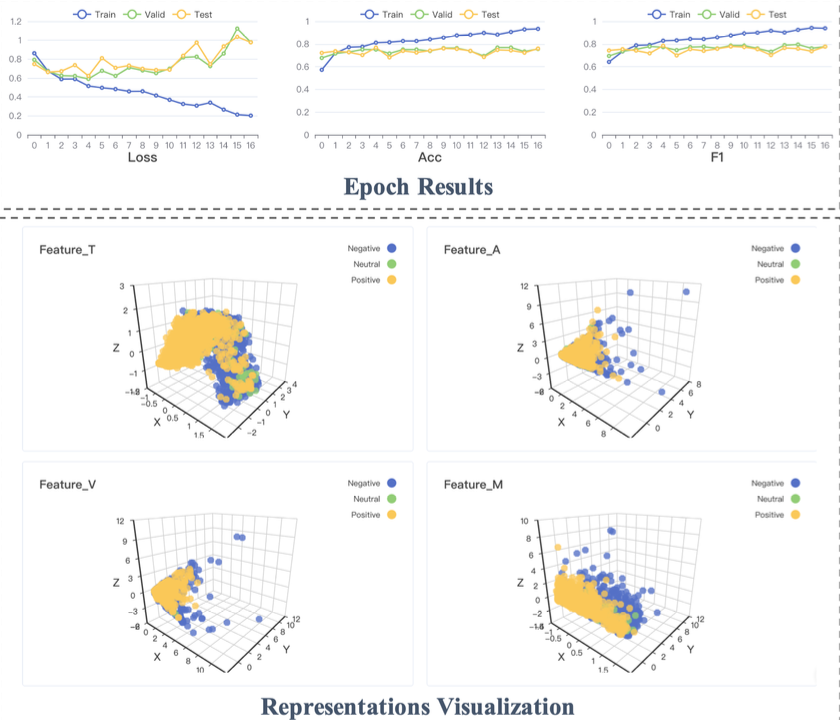
Epoch Result에서는 Epoch마다 Train, Valid, Test 데이터셋에 대해 Loss, 정확도, F1-score를 그려준다. 또한 각 단계에서 학습된 멀티모달 fusion 결과와 단일 모달에 대한 결과를 3D로 표현해주면서 사용자가 멀티모달 특성 표현과 fusion 과정에 대해 직관적으로 파악할 수 있게 하였다.
4.2 실시간 시연
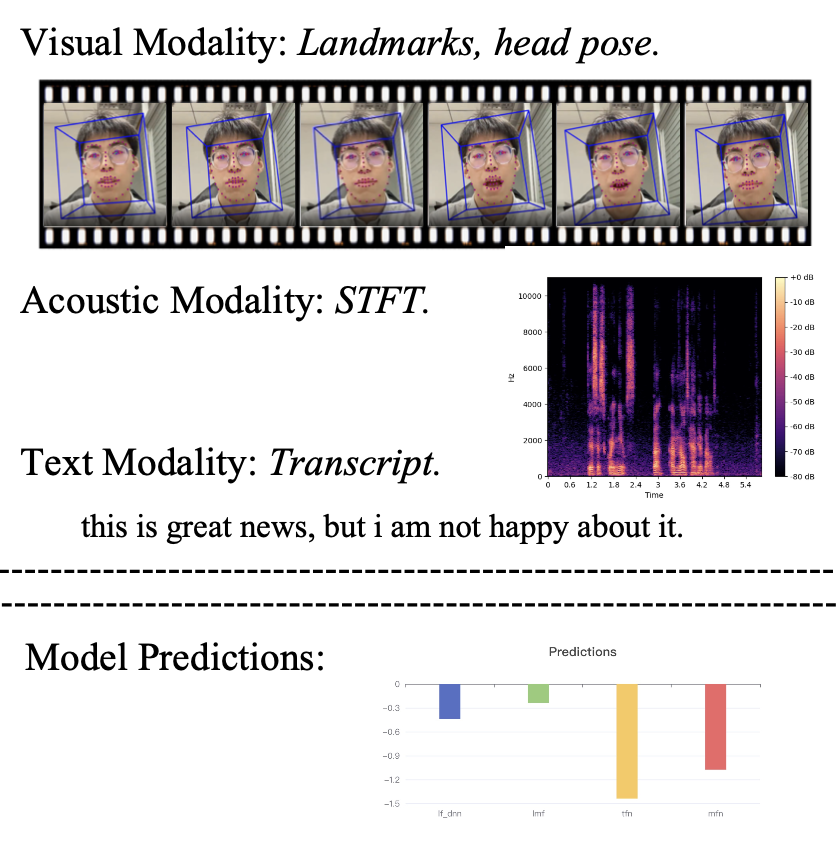
실시간 시연 모듈은 사용자가 원하는 영상 객체를 업로드하면 아래 그림처럼 해당 영상의 시각, 음향, 문자 특성 정보를 시각적으로 제공하고 그에 따른 모델의 예측(감성 점수)을 막대 그래프로 나타내 준다. 이를 통해 사용자는 각 모달의 인식 및 추출과 예측이 잘 이루어지고 있는 지 직관적으로 확인할 수 있다.
4.3 일반화 성능 분석
일반화 성능 분석 모듈에서는 데이터셋 유형에 따른 모델의 성능 차이를 쉽게 파악할 수 있도록 한다. 예를 들어 아래 그림은 MOSI 데이터셋에 대해 T1-A1-V3 특성 조합으로 학습된 4개의 모델들이 있고 이를 5가지 유형의 데이터셋으로 테스트 후 그 결과를 표로 나타낸 것이다.
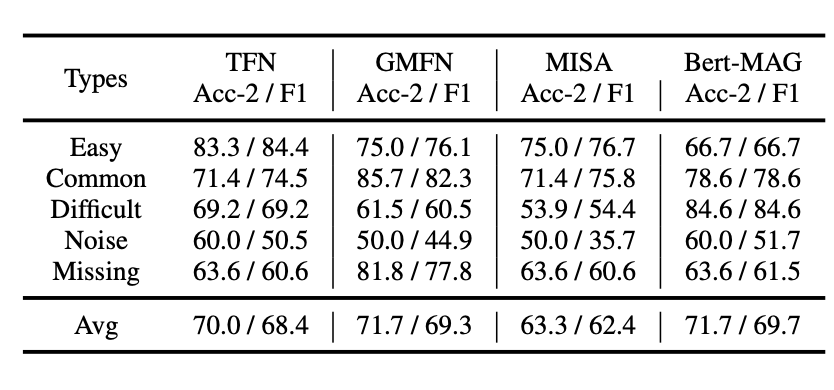
위 표를 보면 Easy와 Common 유형의 데이터셋에 비해 Noise나 Difficult 유형의 데이터셋에서 성능이 현저히 떨어지는 것을 확인할 수 있으며 특히 Noise가 있는 데이터셋의 경우 Missing이 있는 데이터셋보다 전체적으로 더 낮은 수치를 보였으므로 real-world에 적용을 위해서는 실제 시나리오에서 발생하는 Noise에 대해 Robust한 모델을 구축하는 것이 중요하다고 할 수 있다.
5. Conclusion
본 논문에서는 멀티모달 감성 분석 연구자들을 위해 데이터 관리, 특징 추출, 모델 훈련, 그리고 모델 분석에 대한 단계별 모듈을 포함한 통합 플랫폼인 M-SENA를 소개한다. 특히 여러 멀티모달 감성 분석 모델들을 end-to-end 방식으로 평가하고 특성 조합과 데이터셋에 따른 모델 성능의 차이를 제시하면서 향후 연구자들이 특정 모델을 활용할 때 이를 참고할 수 있게 하였다. 그리고 모델 뿐만 아니라 입력을 위한 영상 특성 추출 과정을 단순한 함수 형태로 두어 코딩에 익숙하지 않은 연구자들도 개인 데이터셋을 활용하여 연구를 위한 사람들의 감성/심리를 쉽게 분석할 수 있도록 하였으며 중간 결과 분석, 실시간 시연, 일반화 성능 분석 모듈을 제공하여 개인 데이터셋에 대한 학습 과정 및 성능을 직관적으로 파악할 수 있게 하였다.
6. Reference
Paper : https://aclanthology.org/2022.acl-demo.20.pdf Code : https://github.com/thuiar/M-SENA, https://github.com/thuiar/MMSA-FET