[ICDE 2022] Inhomogeneous Social Recommendation with Hypergraph Convolutional Networks
Inhomogeneous Social Recommendation with Hypergraph Convolutional Networks
ICDE 2022
https://arxiv.org/abs/2111.03344
Motivation
본 논문은 2022년 ICDE 에서 소개된 논문으로 칭화대 소속 Zirui Zhu, Chen Gao 등이 저자로 참여하였습니다. 복잡성을 지닌 소셜 네트워크를 하이퍼그래프 방식으로 해석하여 추천 성능을 높이는 연구로 최근 instagram 등의 소셜네트워크에 다양한 컨텐츠와 상품이 판매되고 있는 상황에 적합한 방법입니다. GNN 기반의 추천시스템에 이미지, 텍스트 등의 다양한 정보가 활용되고 있고, 더불에 유저들간의 소셜 정보를 통해 공통적인 취향과 차별화된 취향을 구분하여 학습 할 수 있다면 시너지를 낼 수 있을것이라 생각하여 이 논문을 리뷰하게 되었습니다.
What is Hypergraph?
본격적으로 논문을 소개하기에 앞서 하이퍼그래프에 대해서 알아보겠습니다. 일반적인 그래프에서는 한쌍의 노드를 엣지로 연결하게됩니다. 반면에 하이퍼그래프에서는 하나의 엣지가 여러 노드를 연결할 수 있는데, 이러한 엣지를 하이퍼엣지(hyperedge)라고 지칭합니다. 예를 들면 사용자 그룹의 경우, 2명 이상의 사람이 하나의 그룹에 속할 수 있습니다. 이때 각각의 사용자들은 노드, 그룹은 하이퍼엣지로 표현될수 있습니다. 하이퍼그래프에서 특히 모든 하이퍼엣지에 속한 노드의 수(cardinality)가 k개로 같은 경우를 k-균일 하이퍼그래프(k-uniform hypergraph)라고 합니다. 즉, 3-균일 하이퍼그래프는 모든 하이퍼엣지에 노드가 3개인 경우입니다.
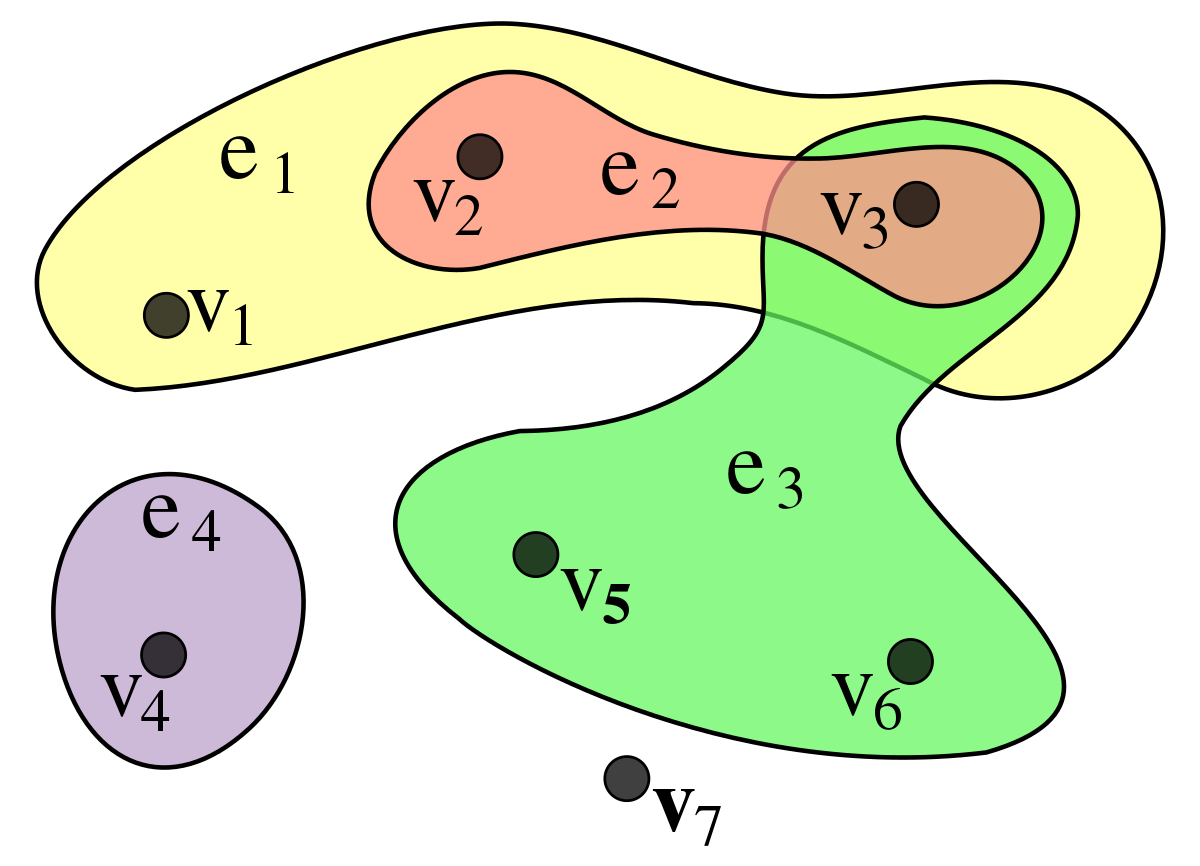
대표적인 하이퍼그래프 논문은 Hypergraph Neural Networks, HyperGCN 등이 있습니다. 하이퍼 그래프는 주로 co-citation, co-authorship 등의 테스크에 활용 되었으며 이러한 데이터의 특징은 단일 로그에서 여러 개체가 연결된다는 점입니다. 보다 자세한 내용을 보고자 하시는 분들은 다음 레포를 참고하셔도 좋을것같습니다. Hypergraph and Graph Neural Network (HGNN & GNN)
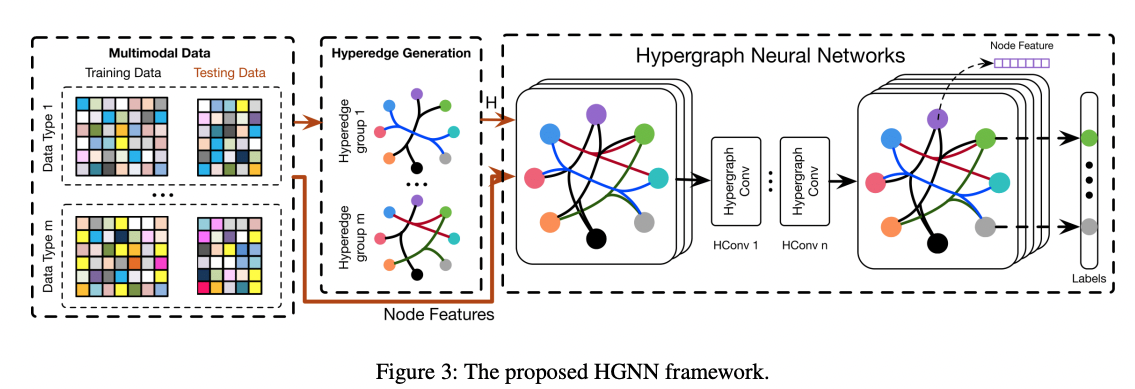
현재 리뷰가 작성되는 시점(2022.11) 기준으로 DGL, PyG 등의 그래프 신경망 구현을 위한 라이브러리에서는 하이퍼그래프, 하이퍼엣지의 구현을 지원하지는 않는것으로 확인됩니다. 다만 본 논문에서는 하이퍼엣지를 가상의 노드로 변환하는 모델을 제안하고 있고, 간단한 구현을 통해 기존 라이브러리로 구현이 가능할것으로 보입니다. 사실상 원래 하이퍼엣지에 담겨야할 피쳐를 가상의 노드가 대신하여 보관하고, massage passing 시에는 가상의 노드와 원래 노드를 연결하는 각각의 엣지를 통해 연산이 수행되게 됩니다.
Abstract
사용자간의 관계를 추천시스템에 활용하는 연구들이 있었으나 다음과 같은 한계가 있었습니다.
- 기존의 연구에서는 관계가있는 사용자들이 모든 아이템에 대해서 동일한 선호도를 가진다고 가정하였습니다.
- 이러한 방법은 소셜네트워크로 연결된 사용자의 다양한 선호도를 표현하지 못합니다.
본 논문에서 소셜네트워크를 활용할때, 연결된 사용자간의 선호도 차이를 고려해야함을 주장하였습니다. 연결된 두 사용자가 특정 아이템에 대해서는 동일한 선호도를 가지지만 다른 제품에 대해서는 선호도가 다른 경우가 존재 할 수 있습니다. 이러한 가정을 바탕으로 기존의 사용자-사용자 관계를 사용자-아이템-사용자 트리플렛으로 표현한 추천 모델인 Social HyperGraph Convolutional Network(SHGCN)가 제안되었습니다. SHGCN은 다음과 같은 두가지 특징을 가지고 있습니다.
- 고차원의 관계를 처리하기 위해 하이퍼그래프를 활용
- 각 하이퍼엣지는 사용자-아이템-사용자를 연결하여 두 사용자의 연결된 선호도를 표현
이 논문의 컨트리뷰션은 다음과 같습니다.
- 하이퍼그래프 합성곱 신경망을 사용하여 소셜관계에 포함된 디테일한 선호도를 모델링
- 사용자의 선호도를 보다 정확하게 표현하여 추천성능 향상
- 두개의 데이터셋에 대해 실험하여 모델의 효과 확인
- sparsity, hyper-parameter 에 대한 robustness 검증
Introduction
추천시스템에 대한 중요도가 높아지면서 사용자 간의 소셜 관계를 활용하는 방법이 등장하였습니다. 소셜관계를 학습하는 방법은 다음과 같은 두가지 방식이 많이 이용됩니다.
- 연결된 사용자간의 유사도가 높아지도록 모델링
- 사용자 관계에 잠재된 정보를 통해 임베딩을 생성
하지만 이러한 방식은 연결된 사용자 간의 선호도 차이를 고려하지 못했다는 한계가 있었고, 사용자간의 연결의 강도를 모델링하고자 하는 시도가 있었습니다. 그러나 이것 역시 친밀도 정도를 나타낼뿐 성향의 차이를 모델링하지는 못하였습니다.
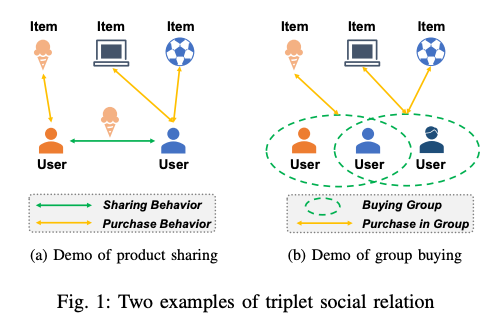
논문에서는 두 이웃간에 공통관심사와 차이가 있는 관심사가 함께 존재하는 현상을 inhomogeneous 라고 표현하고 있습니다. 이러한 불균일성(inhomogeneous)을 포착하는 것은 중요하지만 two-tuple 에서는 어려움이 있었습니다.
Figure 1a 와 같이 친구와 아이템 공유가 가능한 소셜 이커머스 플랫폼이 등장하였습니다. 이러한 데이터셋에서는 공유된 제품을 통해 두 사용자의 공통관심사를 반영 할 수 있습니다.
Figure 1b 와 같이 두명 이상의 사용자가 특정 물품을 함께 구매하는 구매그룹을 형성하는 경우에서도 불균일 효과를 포착하는것이 중요한 역할을 할 수 있습니다. 같은 구매그룹에 속한 사용자들간에도 다른 제품에 대해서는 성향 차이가 있을 수 있기 때문입니다.
앞서 언급한 정보를 포착하기 위해 사용자-아이템-사용자 트리플렛을 구성하는 것은 어렵지 않으나, 이러한 연구는 찾아보기 어렵습니다. 또한 불균일한 관계학습은 기존의 방법으로는 어려움이 있습니다.
여기에는 두가지 챌린지가 있습니다.
-
트리플렛 관계를 표현
두 유저와 공유 아이템으로 구성되는 트리플렛은 일반적인 노드 쌍의 관계를 표현하듯이 스칼라값 만으로는 표현이 어렵습니다. -
사용자 선호도 학습에 트리플렛 활용
트리플렛은 두 사용자간의 공통 관심사를 반영하고 있고, 이를 사용자-아이템 선호도 학습에 활용하는것은 어려움이 있습니다.
저자들은 최근 그래프 학습에서 영감을 얻어 두개 이상의 노드를 연결하는 하이퍼엣지 (사용자-아이템-사용자) 를 통해 하이퍼그래프를 구성하는 것을 제안하여 앞선 문제들을 해결하고자 하였습니다. 논문에서는 복합적인 소셜관계를 통해 사용자 선호도 학습을 하는 하이퍼그래프 컨볼루션 네트워크 모델 Social HyperGraph Convolutional Network(SHGCN) 을 제안하였습니다. SHGCN은 embedding-propagation 레이어를 통해 사용자의 잠재적 선호도를 학습하게 됩니다. 논문의 주요 컨트리뷰션은 아래와 같습니다.
- 소셜기반 추천시스템에 inhomogeneous 관점을 추가
- 소셜 플랫폼의 트리플렛들을 하이퍼그래프로 구성 —> 트리플렛을 하이퍼엣지로 표현
- 두개의 실제 데이터셋에 대해 실험을 수행하였으며, 희소 데이터셋에서의 효과 확인, 매개변수에 대해 민감하지 않음을 확인
추가적으로 논문 후반부에는 제안하는 모델의 연산량, 시간복잡도 등에 대한 분석이 이루어 집니다. 기존의 모델들과의 비교를 통해 적은연산량으로 높은 효과를 낼 수 있음을 보여주었다는 점에서 모델의 장점에 대해 잘 어필 하고 있습니다.
Problem Formulation
저자들은 Inhomogeneous social recommendation 문제를 아래와 같이 사용자-아이템 트리플렛을 활용한 구매 확률 예측 으로 정의 하였습니다.

사용자 아이템 인터렉션 집합
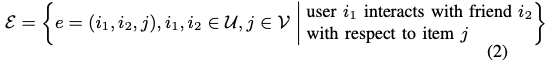
트리플렛 집합
사용자, 아이템 집합은 각각 U, V 로 표현됩니다. Input : Y (사용자 아이템 인터렉션 집합) , E (사용자-아이템-사용자 로 구성된 트리플렛 집합) output : 사용자 i가 아이템 j 와 인터렉션하거나 구매할 확률
3. Methodology
Social HyperGraph Convolutional Network (SHGCN) 는 4가지 파트로 구성됩니다.
- Hypergraph Construction 트리플렛에 포함된 사용자간의 관계를 모델링하기 위해 하이퍼그래프 구성
- Embedding Layer 하이퍼그래프의 각 노드를 벡터로 변환 사용자, 아이템을 동일한 잠재 공간에 함께 표현
- Hypergraph Convolutional Layer 트리플렛의 inhomogemeous한 관계를 학습하기 위해 하이퍼그래프 컨볼루션 레이어를 사용 노드와 엣지의 이웃 정보를 통합 (하이퍼엣지도 임베딩 벡터로 표현)
- Prediction and Optimization 사용자, 아이템 노드 임베딩의 inner product 를 통해 구매 확률을 예측 Bayesian Personalized Ranking (BPR) loss 를 사용
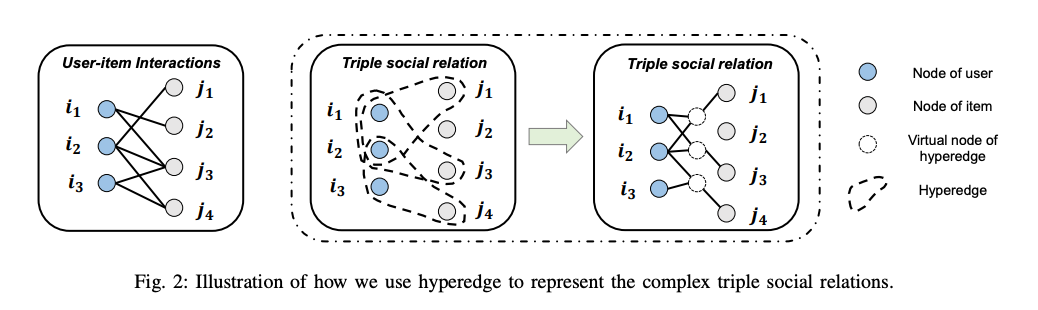

3.1 Hypergraph Construction
3.1.1 Hyperedge and Hypergraph
Hypergraph 에서는 edge 들을 hyperedge 로 대체하여 노드쌍 간의 관계만 모델링하는 기존의 그래프를 확장합니다. 기존에 두쌍만을 연결하는 엣지와는 별개로, 단일 하이퍼엣지는 여러 노드를 연결할 수 있습니다. Figure 2 는 하이퍼 엣지의 개념을 보여줍니다.
3.1.2 Hypergraph-structured data
기존의 소셜 추천시스템은 트리플렛을 활용하는데 한계가 있었고, 이러한 한계를 넘어 inhomogeneous social recommendation 을 구현하기 위해 hypergraph를 활용하였습니다.
사용자, 아이템을 노드로 변환하고, 사용자-아이템-사용자 트리플렛 관계를 하이퍼엣지로 구축 합니다.
본 연구에서는 두 사용자와 하나의 아이템을 하나의 트리플렛으로 연결하였으나, 더 많은 사용자, 아이템 연결도 가능합니다.
3.2 Embedding Layer
노드의 피쳐로 사용하기 위한 벡터를 얻기 위해 사용자와 아이템을 d dim의 벡터로 표현합니다. 임베딩 메트릭스 E 는 모든 사용자, 아이템 벡터를 포함하여 생성합니다.
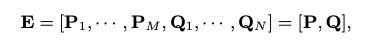
기존의 그래프기반 방식들에서는 노드에만 벡터를 할당했었습니다. 하이퍼엣지는 불균일한 관계를 포함하기 때문에 이 역시도 벡터로 표현될 필요성이 있었습니다. 그러나 각각의 하이퍼엣지를 벡터로 표현하는것은 높은 메모리 비용이 필요하고, 하이퍼엣지로 연결된 꼭지점에서 대표벡터 \(C_e\)를 생성하는 절충안을 활용하였습니다. (하이퍼엣지는 사실상 여러 엣지의 집합인데 이를 모두 모델링하기보다는 꼭지점에 노드를 추가하여 해당 노드에 벡터를 부여하는 방식으로 해결)
3.3 Hypergraph convolutional layer
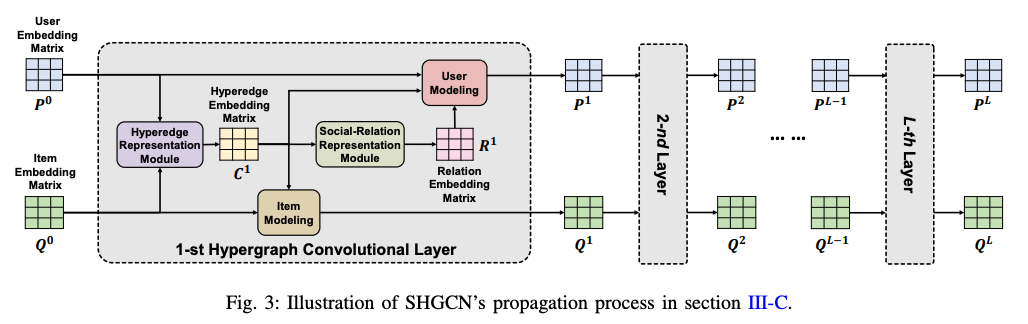
이번 단계는 하이퍼엣지의 불균일한 영향을 포착하기 위해 하이퍼엣지 표현을 생성하는 단계입니다. 하이퍼엣지의 표현은 사용자간의 관계, 사용자-아이템 관계를 모델링하기 위해 사용됩니다.
3.3.1 Hyperedge Representation
Figure 2 와 같이 하이퍼엣지는 가상의 노드로 표현됩니다. 아래 수식 (4,5) 는 노드 임베딩으로 부터 하이퍼엣지 임베딩을 얻는 과정을 보여줍니다. 하이퍼엣지 e 에 대한 임베딩인 \(C_e\) 를 얻기 위해서 그래프컨볼루션 레이어를 사용하고 이때 \(K(e)\) 는 하이퍼엣지 \(e\) 로 연결된 노드 집합을 의미합니다. \(E^{k-1}_w\) 는 \(k-1\) 번째 레이어에서의 임베딩 메트릭스(사용자, 아이템 벡터 집합) 를 의미하고, 모든 이웃노드 임베딩을 concat 해서 MLP 레이어를 통해 aggregation을 하여 하이퍼엣지의 임베딩으로 할당하게 됩니다. 실험에서 오버피팅되는 이슈가 있어 수식 (5) 와 같은 전통적인 그래프 컨볼루션 네트워크를 사용하였다고 합니다. 인코딩된 하이퍼엣지 임베딩을 통해서 사용자간의 불균일한 영향을 전달할수 있다고 저자들은 주장하고 있습니다. 두 사용자가 복수에 하이퍼엣지에 연결될 수 있습니다.
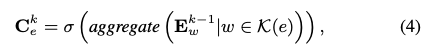
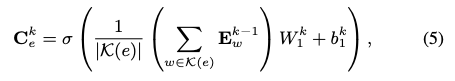
3.3.2 Social Relation Representation Module
기존 연구에서는 노드간의 복잡한 관계를 모델링하기 위해서 노드셋을 학습하고 노드간의 관계를 출력하는 함수 \(f\)를 제안하였습니다. 그러나 이러한 방식은 그래프 구조를 무시한다는 단점이 있습니다. 이를 해결하기위해 연결된 두 사용자의 사회적 관계를 표현하는 벡터 \(R_t\) 를 생성하고, 아래와 같은 컨볼루션 레이어를 설계하여 \(R_t\) 를 얻습니다. \(N(i_1,i_2)\) 는 두 사용자에 모두 연결된 하이퍼엣지목록, \(η(i1, i2)\) 는 \(R\)에서 타겟 사용자의 값만을 얻기위한 인덱스를 얻는 맵핑함수 입니다. 이러한 소셜관계 모델링의 장점은 트리플렛 관계들의 영향을 다르게 반영할 수 있다는 것입니다.
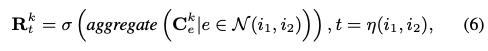
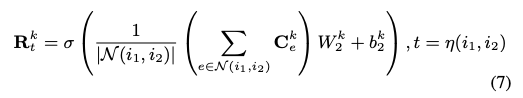
3.3.3 User Modeling Module
소셜추천에서 사용자의 특성의 일부는 친구의 특성으로부터 오게됩니다. 기존에는 스칼라 가중치만을 사용하였으나 본 연구에서는 소셜관계에 대한 벡터를 얻었기 때문에 보다 디테일한 모델링이 가능합니다. 핵심 아이디어는 수식 (6) 에서 계산된 소셜관계 표현을 모델링하는것입니다.
이를 위해 수식 (8) 과 같은 message passing 기반의 과정을 진행합니다. Z(i)는 사용자 i에 연결된 하이퍼엣지 집합을 의미합니다. 이전 레이어 임베딩을 더해줌으로써 gradient vanishing, exploding을 예방하게 됩니다.
하이퍼엣지의 메시지는 불균일 신호를 포착하고, 소셜 네트워크 메시지는 동질성을 모델링하는데 집중하게 됩니다. 하이퍼엣지 메시지는 아이템에 따른 차이를, 소셜네트워크 메시지는 사용자의 유사성을 반영합니다. 그래프 컨볼루션을 사용하여 수식 (8)을 구현하였고 사용자간의 가중치 계산을 위해 MLP 레이어 사용하였습니다. 추후 실험을 통해 성능이 MLP구조에는 민감하지 않음을 확인합니다.
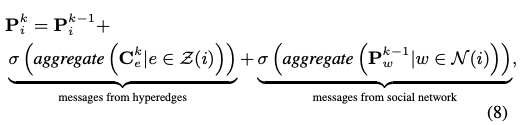
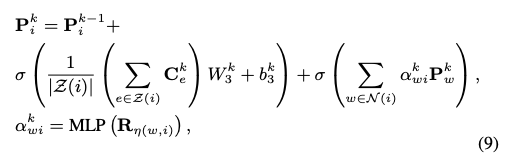
3.3.4 Item Modeling Module
아이템의 피쳐를 캡쳐하기 위해 하이퍼엣지 표현을 활용합니다. Z(j) 는 아이템 j에 연결된 하이퍼엣지 셋으로 이전과 마찬가지로 GCN 을 통해 병합합니다.
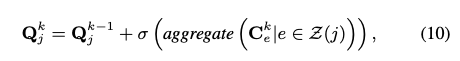
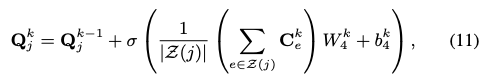
3.4 Prediction and Optimization
L개의 레이어를 거친뒤, 유저/아이템 에 대해서 L개의 각기 다른 임베딩을 얻습니다. L개의 임베딩을 concat 하여 사용자, 아이템 메트릭스 P, Q 를 얻게되고 타겟 유저, 아이템 벡터를 내적하여 rating 을 예측하게 됩니다. Loss 는 BPR loss 를 사용하였습니다.
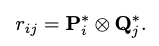
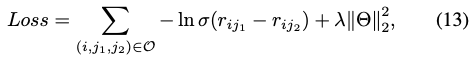
3.5 Model Size and Time Complexity
Model Size SHGCN은 경량 모델입니다. 4가지 임베딩 메트릭스들을 매 하이퍼그래프 컨볼루션 레이어마다 생성합니다. 학습가능한 파라미터는 3가지 부분으로 나누어 집니다.
- 유저/아이템 임베딩 메트릭스 - \((M+N)*d\)
- MLP 파라미터 \(2L*d^2\)
- 각각의 레이어에서의 4가지 선형변환 파라미터 \(4L*d(d+1)\)
\(min(M,N) >> max(L,d)\) 임을 고려할때, SHGCN 은 MF 만큼이나 경량 모델 이라는 것을 알 수 있습니다. 실제로 MF 에 비해서 추가적인 파라미터를 3% 만 활용합니다.
Time Complexity
가장 시간이 오래걸리는 부분은 하이퍼 컨볼루션레이어에서 4가지 집계 파트입니다.
하이퍼엣지 표현, 소셜관계 표현, 사용자/아이템 표현 모듈 이고, 각각의 시간복잡도는 \(O(|E|d), O(|T|d), O((|T| + |E|)d), O(|E|d)\) 입니다. \(E\)는 하이퍼엣지, \(T\)는 소셜관계를 의미합니다.
데이터 규모에 대해서 선형 시간 복잡도를 가지고 있고, 실제 실험에서는 하이퍼엣지 숫자가 많지 않아 훈련시간이 길지 않았습니다. Tesla V100 GPU 에서 훈련시, MF와 SHGCN는 각각 에폭당 14초 20초가 걸려 큰 차이가 없었습니다. 반면에 다른 하이퍼그래프 컨볼루션 기반의 방법인 MHCN은 60초가 걸리며 제안 모델보다 2배 이상의 시간이 소모되었습니다.
3.6 Open Discussions
제안하는 모델은 하이퍼엣지의 장점을 살린 모델로 다음과 같은 장점들을 가지게 됩니다.
- 하이퍼엣지의 장점을 살리는 모델로 다양한 응용이 가능함.
- 상품리스트 추천과 같은 1대n문제에도 도움이 될 수 있음.
- 하이퍼엣지, 소셜관계 임베딩 을 얻을 수 있는데 이를 다양한 다운스트림 테스크에 활용할 수 있다.
4. Experiments
저자들은 다음과 같은 리서치 퀘스쳔을 기반으로 실험을 설계하였습니다.
- RQ1 하이퍼엣지를 활용하는 트리플렛 기반의 소셜 추천방법이 기존모델 대비 높은 성능을 달성할 수 있을 것인가
- RQ2 제안하는 모델이 데이터 희소성 이슈를 해결할 수 있을건인가? 적은 인터렉션에도 성능향상이 유효할 것인가?
- RQ3 하이퍼파라미터들이 모델 성능에 어떠한 영향을 미칠 것인가?
4.1 Experimental Settings
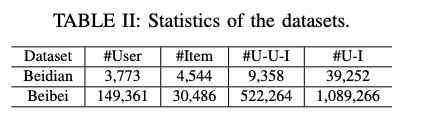
4.1.1 Dataset
- Beidian 소셜네트워크에 제품의 URL을 공유 할 수 있는 e-commerce 플랫폼에서 수집된 데이터. 사용자 구매기록, 아이템 공유기록 두가지 유형의 데이터가 있음. 트리플렛은 아이템을 공유한 유저, 공유한 아이템, 아이템을 공유 받은 유저 로 구성
- Beibei e-commerce 플랫폼에서 수집된 데이터로, 그룹단위 구매 데이터 사용자는 구매그룹을 만들고 다른 사용자를 초대할 수 있음 두 사용자가 함게 하나의 물건을 구매한 데이터를 사용 (두명이 함께 구매하는경우가 가장 많았음)
4.1.2 Evaluation Protocols
Leave-one-out 평가 프로토콜을 적용, trian/valid/test 세트로 분할하였고 Recall, NDCG 두가지 평가지표를 사용하였습니다.
- Recall@K 정답인 항목이 상위 K개 추천 목록에 존재할 확률입니다.
- NDCG@K NDCG(Normalized Discounted Cumulative Gain) - 순위에서의 위치를 고려하여 계산합니다.
4.1.3 Baselines
협업필터링 기반의 방법
- MF : 전통적으로 추천에 활용된 행렬분해기법
- SocialMF : MF기반 소셜추천모델. 사용자, 친구의 가중합 거리로 계산되는 사회 관계를 모델링하기 위해 사회 관계 정규화 항을 도입함
- GraphSAGE-BG : GraphSAGE 는 유저 아이템 bipartite graph 에 활용
- NGCF-BG: 유저 아이템 그래프에서 높은 차원의 연결을 모델링하고 협력 신호를 활용하는 GCN 모델
소셜 네트워크 기반의 사용자 선호도 추론
- GraphSAGE-EG : 소셜 네트워크를 유저-아이템 bipartite graph에 병합하여 GraphSAGE에서 활용
- NGCF-EG : NGCF 에 소셜네트워크를 반영한 확장그래프를 적용
- Diffnet : GCN기반 소셜 추천 방법. 소셜그래프에 GCN을 적용하여 재귀적인 소셜확산 프로세스 구현
- MHCN: multi-channel hyper-GCN 방법으로 multiple motif-induced hypergraphs 에서 동작한다.
- GraphSage-CG: 하이퍼엣지를 무방향 complete graph로 변환하고 graphSAGE에서 활용. 각 하이퍼 엣지에 대해 모든 노드쌍을 일반적인 엣지로 연결함
- NGCF-CG: GraphSage-CG와 동일한 방법으로 구성한 그래프를 NGCF에서 활용
4.1.4 Hyper-parameter setting
베이스라인을 포함하여 모든 모델은 BPR loss 로 학습됩니다. 네거티브 케이스를 학습하기 위해 학습데이터셋에서는 하나의 아이템에 대해 8개의 아이템을 무작위로 선택합니다. 테스트 데이터셋에서는 하나의 아이템당 100개의 아이템을 무작위 선택합니다.
나머지 하이퍼 파라미터는 아래와 같습니다. Adam Optimizer, 4096 사이즈의 미니배치 사용, 임베딩 디멘션 d=32 사용 learning rate = {3e-4, 1e-3, 3e-3} L2 regularization = {1e-8, 1e-7, 1e6, 1e-5, 1e-4, 1e-3} 과적합 방지가 주요 목적이 아니기때문에 메시지, 노드 drop out 0 사용 기존 연구에 따라 GCN 레이어 수는 3 사용
4.2 Overall Performance (RQ1)
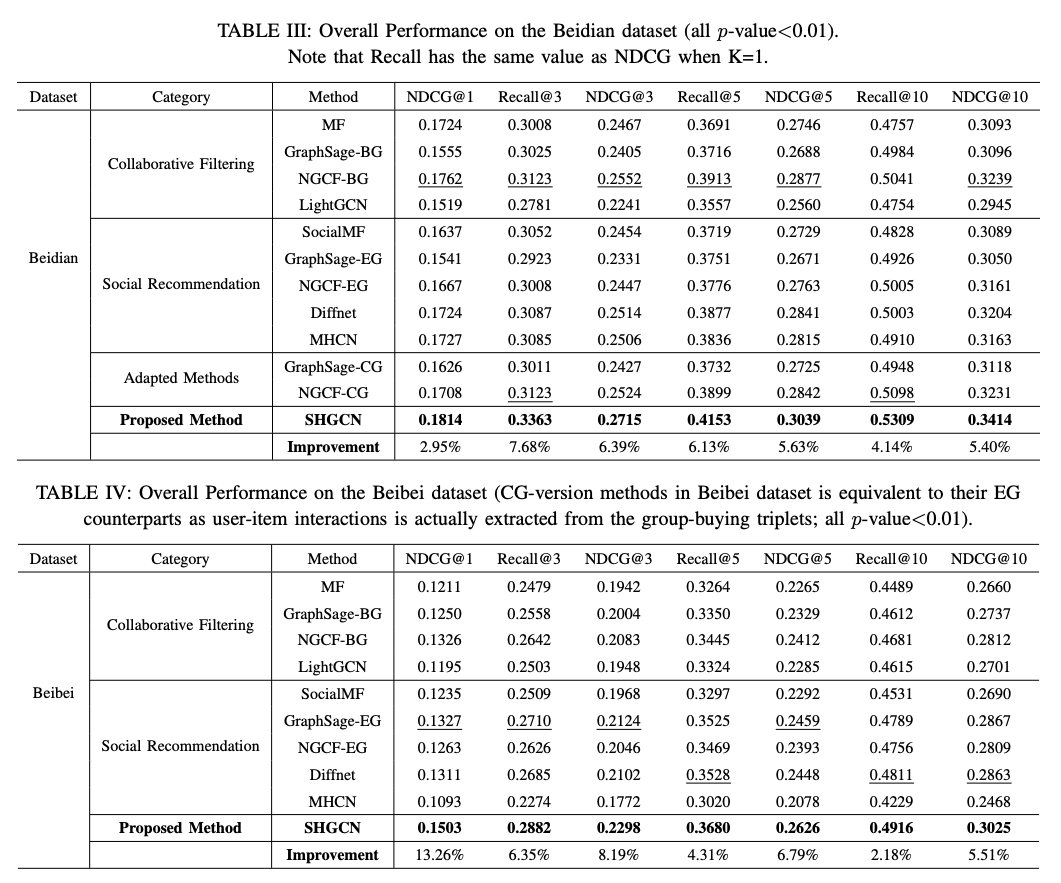
table 3 는 베이스라인과 비교한 전반적인 성능이 표시되어있습니다. top-K 에서 k 를 {1, 3, 5, 10} 으로 설정 하였습니다.
실험결과는 아래와 같습니다
- SHGCN은 모든 메트릭에서 베이스라인보다 높은 성능을 달성했습니다. 임의의 5개 시드로 실험하고 평균값을 사용하였습니다. 2-표본, t-test p-value가 0.01 보다 작아서 효과가 검증되었습니다.
- 기존 그래프기반 모델들은 고차원의 소셜관계 모델링에 실패하였습니다. 소셜관계를 그래프에 활용하더라도 성능이 개선되지 않았습니다. ( GraphSAGE vs GraphSAGE-EG 등) 반면에 제안한 모델은 트리플렛을 효율적으로 활용함을 확인하였습니다.
- 기존의 소셜네트워크 기반의 추천 모델은 트리플렛 관계를 활용하지 못했습니다. 기본의 모델들은 연결된 사용자들 간의 거리를 최소화 하는 방식을 사용합니다. GCN기반의 방식은 그래프 전파를 통해 소셜관계를 활용하였습니다. MHCN은 매뉴얼하게 생성한 모티프, 채널에 의존하기 때문에 새로운 데이터셋에 대한 일반화 능력이 부족합니다. (Beibei 데이터셋에서 훨씬 낮은 성능을 보임) SHGCN 은 메시지 전달을 하이퍼그래프 컨볼루션을 통해 자동으로 학습하기 때문에 다른 데이터셋에서도 우수한 성능을 보였습니다.
4.3 Data Saprsity Issue (RQ2)
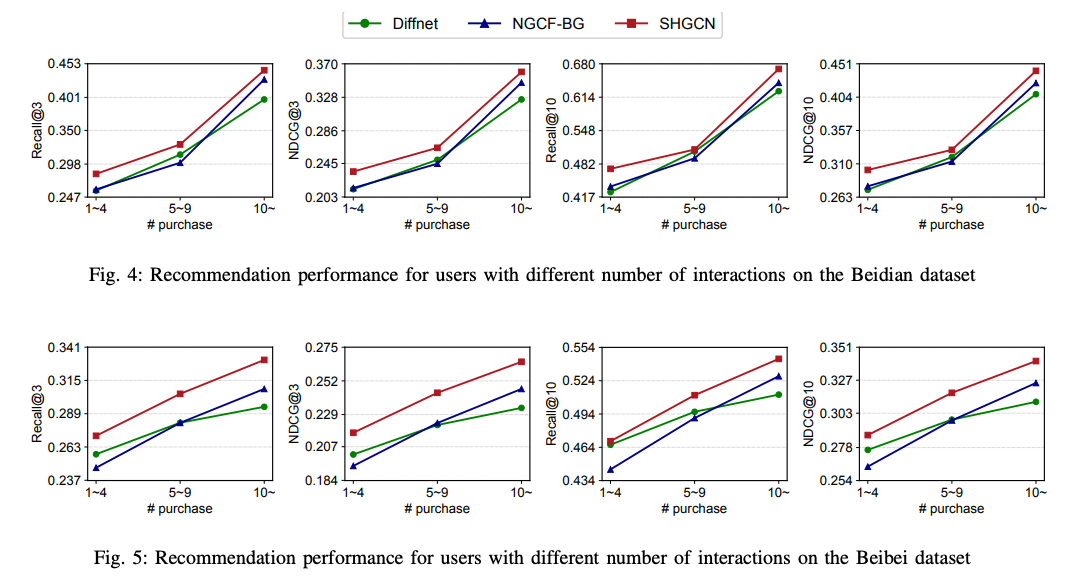
일반적으로 사용자-아이템 인터렉션이 줄어들면 추천 성능이 저하됩니다. sparse 한 데이터셋에서의 모델의 성능을 확인하기위해, 구매 행동 수에 따라 사용자를 여러 그룹으로 분할하여 모델을 평가하였습니다. Figure 4, 5 를 보면 SHGCN은 희소성이 높은 데이터셋에서도 가장높은 성능을 달성하였습니다.
4.4 Hyper-parameter Study (RQ3)
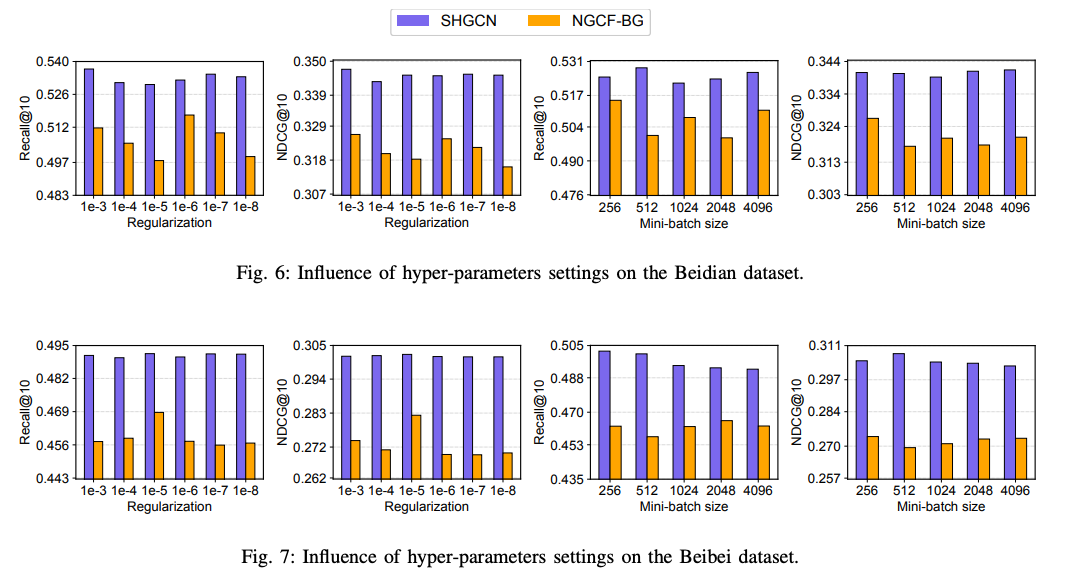
제안한 모델은 하이퍼파라미터 변화에 강건한 특성을 가지고 있습니다. 이러한 특성을 통해 튜닝에 필요한 리소스를 절약할 수 있습니다. Figure 6, 7 은 하이퍼파라미터에 따른 실험결과를 보여줍니다. 이를 토해 모델이 하이퍼파라미터에 민감하지 않음을 알 수 있습니다.
- NDCG@10 기준 변동률은 L2 정규화 텀에 따라서 1.16%, 2.07% 이내
- 미니배치 크기에 따른 변동도 2% 미만 이처럼 하이퍼파라미터에 민감하지 않은 특성은 산업에서 활용될 경우 장점이 됩니다.
5. Related Works
소셜기반 추천 과 그래프/하이퍼그래프 기반의 추천 두가지 관점에서 관련 연구들을 정리하였습니다.
Social Recommendation 소셜 추천은 소셜네트워크를 활용하여 추천성능을 높이고자 합니다. 소셜 정규화를 통해 친구와의 거리를 제한하게 됩니다. 목적함수에 소셜 관련 정규화항을 만들거나 소셜관계 예측에 대한 멀티테스킹 학습을 활용합니다. —> 여기서는 가까운 친구는 유사한 선호도를 가지고 있다는 가정이 있습니다.
최근 연구들에서는 보다 복잡한 소셜관계를 연구하게 되었습니다. 다른 관심사를 가지고 있는 친구를 식별하기 위한 적대적 네트워크, 소셜관계의 다양한 강점을 어텐션 모델로 모델링 하는 등의 시도가 있었습니다. —> 이러한 연구는 주로 스칼라 가중치만을 사용하기 때문에 복잡한 사회적 관계를 모델링 하기 어렵습니다.
본 연구에서는 이러한 한계들을 극복하기 위해 사용자-아이템-사용자 트리플렛을 통해 세분화된 사회적 추천을 연구하였습니다.
Graph-based and Hypergraph-based Recommendation 추천시스템은 일종의 link prediction 으로 볼 수 있습니다. 데이터 구조의 유사성으로 그래프 기반의 방식이 메인스트림으로 떠올랐습니다. 초기 연구에서는 랜덤워크 기반의 방식으로 방문한 노드를 추천하였으나 잠재표현 학습이 어려워 결과가 좋지 못했습니다. 이후에 그래프 임베딩 방식을 통해 유저, 아이템의 임베딩을 학습하는 방법들이 제안되었습니다.
GCN은 노드임베딩과 그래프구조를 함께 학습하고 추천에 널리 사용됩니다. GCN은 협업필터링 외에 다른 추천 테스크에서도 효과적입니다. ( 세션기반, 번들 추천, 지식기반 추천, 소셜추천 등)
최근에는 하이퍼그래프 기반의 추천시스템 등장하였습니다. 엣지들을 하이퍼엣지로 일반화하여 기존 그래프 대비 복잡한 관계를 활용하게됩니다. 하이퍼그래프 임베딩으로 사용자의 유사도를 계산하고 소셜네트워크 정보를 통합한 추천방법이 제안되었습니다. dual-channel hypergraph collaborative filtering(DHCF) 을 통해 사용자 아이템 상관관계 명시적으로 모델링하게 됩니다.
본 연구에서는 트리플렛 관계를 하이퍼엣지로 표현하고 하이퍼 그래프를 활용하는 모델 제안하였고 이를 통해 불균일한 사회적인 영향을 학습하게 됩니다.
6. Conclusion and Future Work
이 논문에서는 소셜관계가 있는 사용자 사이의 세분화된 비균질 소셜 추천 문제를 다뤘습니다.
트리플렛 기반의 소셜 관계와 사용자-항목 상호작용 데이터를 모두 잘 표현할 수 있도록 하이퍼그래프를 구성하고 하이퍼그래프 합성곱 네트워크 모델을 제안하였습니다.
두 개의 데이터셋에서의 실험을 통해 모델이 유의미한 성능향상이 있음을 보였고, 데이터 희소성 문제를 해결하는데도 도움이 될 수 있음을 확인하였습니다. 또한 모델의 성능이 하이퍼파라미터 설정에 민감하지 않음을 확인하였습니다.
추후 연구로 두 명 이상의 친구가 하나의 아이템을 공유하는 소셜 네트워크에서의 그룹 구매와 같이 다양한 시나리오에서 모델의 성능연구를 제안합니다. 다중 관계 정보 또는 이러한 복잡한 상호 작용에 대한 더 많은 추가 데이터를 활용하는것을 연구해 볼수 있습니다. 또한 더 복잡한 응용 프로그램에서 추천 성능을 향상시키기 위해 시간 정보를 활용해 볼 수 있습니다.
본 논문은 소셜기반의 추천을 트리플렛기반의 하이퍼그래프, 하이퍼엣지 구성과 하이퍼엣지의 임베딩을 생성하는 GCN 레이어를 통해 해결하고자 하였습니다. 최근 하이퍼엣지를 활용하는 연구가 많은데 적합한 유즈케이스로 소셜 기반의 추천을 제안하였다는 점에서 기여도가 있습니다. 모델의 성능뿐만 아니라 파라피터 수, 학습 시간, 하이퍼파라미터 민감도 등 실제 어플리케이션을 개발할때 고려해야하는 다양한 요소들에 분석한 것이 장점입니다. 다만 아쉬운 부분은, 여기에서 제안된 모델은 새로운 유저, 아이템이 계속해서 추가되는 환경에서는 일반화가 어렵다는 점입니다. 또한, 앞서 언급한 복잡한 소셜관계에 대해 강점을 보이는것을 케이스 스터디를 통해 확인하였다면 좋았을 것입니다. 소셜관계를 GNN 을 통해 task 에 반영하는 것은 앞으로도 다양한 어플리케이션으로 활용될 가능성이 있습니다. 추후 연구에서 유저, 아이템간의 관계에 대한 설명력을 지니는 모델을 개발하는데 활용해 볼 수 있을 것 같습니다.
Author Information
- Han, Donghee
- Graduate School of Data Science, KAIST, Daejeon, Korea
- Knowledge Innovation Research Center
- GNN, Recsys, Deep-learning, NLP