[ICLR 2023] HiVT: Hierarchical Vector Transformer for Multi-Agent Motion Prediction
해당 논문은 2022년도 CVPR에 나온 논문으로, Trajectory Prediction 분야의 연구입니다. Trajectory Prediction 분야에 생소할 수 있는 분들을 위해서, 논문 요약에 앞서 우선 자율주행과 Trajectory Prediction 분야에 대한 배경 설명을 드리겠습니다.
혹시 최근 유튜브 쇼츠에서 테슬라 차량의 자율주행 능력과 관련된 영상을 보신 적이 있으신가요? 차량에서 손을 떼어도 아주 부드럽게 운전해 주는 모습을 볼 수 있습니다. 이처럼 자율주행 자동차 기술은 현재도 매우 높은 성능을 보입니다. 하지만 이러한 높은 성능에도 불구하고, 갑작스러운 보행자의 등장이나, 옆 차량의 차선 변경 등, 잠재적인 위협에 대한 대응 미숙은 여전히 큰 이슈입니다. 따라서 자율주행 분야는 여전히 각광받고 있는 연구 분야입니다.
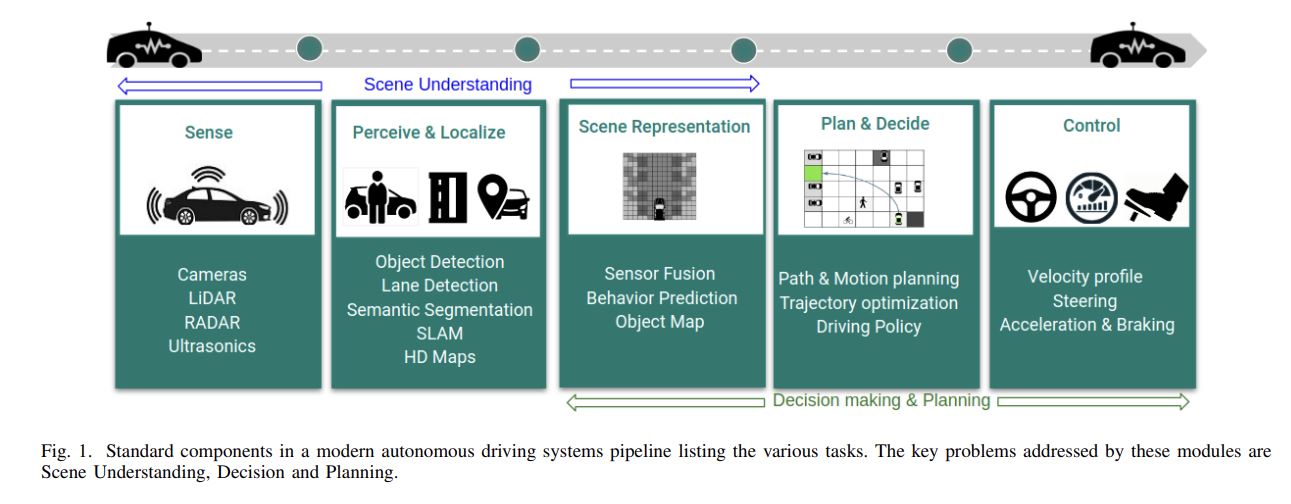
B Ravi Kiran(2020, pp.4909-4910)에 의하면, 자율주행 연구의 파이프라인은 크게 Scene Understanding, Decision making & Planning, 그리고 Control 단계로 나눌 수 있습니다. 이 중에서 Decision making & Planning은 다른 운전자의 행동을 예측하고 이를 기반으로 어떻게 주행할 것인지 계획하는 단계로, 머신러닝이 가장 깊게 관여하는 단계라고 볼 수 있습니다. 차량의 행동을 예측하는 것은 이후 차량의 경로 계획과 실제 주행의 성능에도 큰 영향을 미칩니다. 따라서 자율주행 파이프라인에서 차량의 행동을 정확히 예측하는 것은 가장 중요한 과정이고, 이를 위해서 등장한 연구 분야가 바로 Trajectory Prediction입니다.
이제 HIVT 논문에 대한 요약을 시작해 보도록 하겠습니다. Introduction 파트를 통해서 간단히 TP의 역사를 살펴볼 수 있을 것 같습니다. 논문과 함께 제 글을 보시는 경우, 논문의 내용과 더불어 저의 배경지식을 함께 담아서 작성하였으니, 이 점 유의해주시길 바랍니다.
1. Introduction
얼핏 보기에 차량의 행동을 예측하기는 쉬워 보입니다. 한 대의 차량이 도로에 있으면 보통 달리던 방향으로 계속 갈 것이고, 차선을 변경하는 경우 차선 중앙에서 조금씩 옆으로 움직일 테니까요. 이처럼 과거 Trajectory prediction 연구는 물리적 수식을 기반으로 차량의 행동을 예측해 왔습니다. 하지만 다양한 차들이 있는 도로 상황에서는 물리적 수식뿐만 아니라, 차량과 차량의 상호작용 또한 고려해야만 합니다. 각 차량의 움직임은 서로의 행동에 실시간으로 영향을 미치고, 이러한 서로 간의 상호작용을 모두 학습에 고려한다는 것은 어려운 일입니다. 따라서 최근 Trajectory Prediction 연구는 운전자 간의 상호작용을 최대한 고려하는 방향으로 모델을 설계하도록 발전해 왔고, HIVT 또한 같은 연구 방향성을 가집니다.
여러 차량을 함께 고려하는 multi agent traffic scenarios에서 차량의 행동을 예측하기 위한 다양한 선행 연구가 이루어졌습니다. 초기 연구에서는 도로 상황에 대한 정보를 운전자의 관점에서 보는 것이 아닌, 공중에서 보는 Bird-Eye-View(BEV)를 활용하여 도로 상황을 마치 이미지 정보처럼 만든 후, 이를 CNN 모델에 넣어서 차량의 다음 행동을 예측하는 연구가 있었습니다. 하지만 이 방식은 CNN 모델을 채택함으로써 생기는 limited receptive fields 문제가 있고, 모델을 학습하기에 계산량이 많다는 문제점이 있었습니다. 따라서 이 문제점을 극복하고자 Vectorized approach가 등장하였습니다. Vectorized approach는 map에서 차량, 보행자, 차선, 외부 환경 등 각종 element들을 점과 벡터로 추출합니다. 그다음 graph neural net, transformer, 혹은 point cloud model 등을 활용하여 vectorized 된 element들 사이의 상호 연관성을 파악하고, 이를 기반으로 차량의 행동을 예측합니다. 하지만 Vectorized approach는 벡터 정보들을 표현할 때, x, y좌표의 기준 축이 되는 reference frame의 translation과 rotation에 강인하지 못하다는 단점이 있습니다. 따라서 이를 극복하고자 예측의 대상인 target agent가 frame의 중심이고, 차량의 head 방향으로 scene이 정렬되도록 전처리하는 접근법이 등장하였습니다. 그러나 이러한 전처리 방식은 예측 대상이 될 target agent가 많은 경우 각 차량마다의 전처리를 모두 해줘야 하므로 계산량이 너무 많아진다는 문제점이 있었습니다. HIVT는 이 문제점을 극복하고자 나온 논문입니다.
앞서 설명한 단어인 “target agent”에 대해서 조금 더 자세히 설명하겠습니다. 앞서 trajectory prediction은 자율주행을 위한 중간 과정이라고 언급하였습니다. 자율주행 차량을 중심으로 주변 차량의 위치를 prediction하고, 이 정보를 기반으로, 앞으로의 행동을 planning 하는 것이 일반적인 과정입니다. 이때 prediction의 대상이 되는 주변 차들을 target agent, planning을 하는 자신의 차량을 Ego Agent라고 부릅니다.
Introduction에서 HIVT 모델에 대해 간략한 설명을 하는데, method 파트에서 바로 자세하게 설명해 보도록 하겠습니다. 본 논문의 contribution은 아래와 같습니다. (contribution도 related work와 method를 읽고 보시는 것을 추천해 드립니다.)
i) local 영역과 global 영역을 나눠서 interaction을 고려하기 때문에 scene 전체에서 interaction을 고려하는 것보다 더 효율적입니다.
ii) translation-invariant scene representation과 rotation-invariant spatial learning module을 통해서 scene의 translation과 rotation에 모델이 강인하도록 설계하였습니다.
ii) 기존의 SOTA모델보다 적은 파라미터를 사용하지만, 더 빠르고 정확한 prediction을 합니다.
2. Related work
2.1. Traffic Scene을 표현하는 방법?
Trajectory prediction을 위해서는 Traffic Scene을 학습을 위한 데이터로 변환하여야 합니다. 이를 위한 방법으로는 Rasterized approach와 Vectorized approach로 크게 2가지가 있습니다. 2가지 방법에 각각 해당하는 연구 사례를 introduction 파트에서 소개해 드렸습니다. 다소 중복되는 설명일 수 있겠지만, 한 번 더 정리해 보도록 하겠습니다.
i) Rasterized approach
Rasterized approach는 우선 map의 element들을 다른 색깔의 이미지로 추출합니다. 예를 들어서 횡단보도는 파란색, 신호등은 빨간색, 보행자는 초록색으로 표시되도록 합니다. 그다음 이 정보들을 공중에서 바라보는 Bird-eye-view로 표현하여 마치 하나의 이미지처럼 만듭니다. Trajectory prediction의 경우 과거부터 현재까지의 경로 정보를 활용하여 미래의 경로를 예측 하므로, 여러 시간의 정보가 담긴 데이터 셋을 활용해야 합니다. 따라서 앞서 element를 추출하여 이미지를 만들 때, 현재와 과거 시점의 정보를 모두 담아주기 위해서, 이미지 데이터를 여러 채널로 표현함으로써 각 채널이 곧 각 시점의 도로 상황이 되도록 데이터 셋을 만들어줍니다. 이처럼 이미지의 채널을 늘려서 여러 시간의 정보를 담는 것 이외에도 RNN을 활용하여 과거와 현재의 정보들을 담아주기도 합니다.
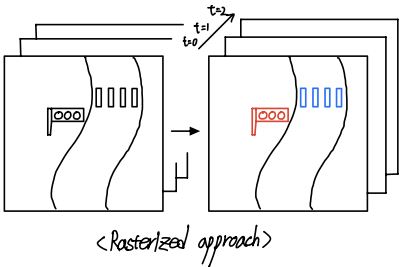
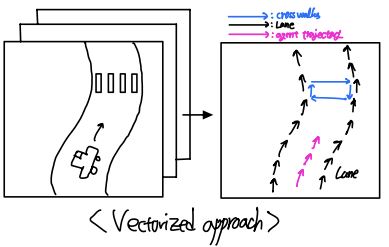
ii) Vectorized approach
Vectorized approach는 scene의 정보들을 점과 벡터로 추출하고 이들 사이의 relationship을 학습하는 방식입니다. Rasterized approach는 전체 scene을 한 번에 다룬다는 느낌이라면, Vectorized approach는 scene을 마치 entries의 집합으로 보고, 이들 사이의 relationship을 구하려고 하는 것입니다. 이 방식은 여러 복잡한 구조물들에 대한 정보를 잘 인식할 수 있다는 장점이 있으며, sparse encoding이 효율적입니다. 관련된 대표적인 논문으로는 VectorNet, LaneGCN, TPCN등이 있습니다. HIVT또한 Rasterized approach보다 Vectorized approach에 속합니다. HIVT는 기존의 Vectorized approach에서 각 entities 사이의 정보가 상대적으로 표현된다는 문제점을 해결한 모델로, 기존보다 한 단계 더 성장한 방식입니다. 이와 관련된 내용은 method 파트에서 좀 더 자세히 설명하겠습니다.
2.2. Motion prediction
차량의 행동을 예측하기 위해서는 차량과 주변 환경 사이의 social interaction을 고려하여야 합니다. 이를 위한 선행연구에서는 social pooling, graph neural networks, attention mechanism, transformer 등을 사용하여 interaction을 학습하고 이를 기반으로 경로를 예측하였습니다. 이 중에서도 최근 논문에서는 주로 transformer를 많이 사용하는데, HIVT 논문 또한 transformer를 기반으로 interaction을 학습합니다. 다만, 이전 연구와의 차별점은 HIVT model은 local representation과 global representaion을 hierarchically하게 학습합니다. 이는 traffic scene에서 전체 entities를 그대로 transformer 모델에 넣어 서로 간의 interaction을 한 번에 고려하는 것보다 효율적이며 성능 면에서도 더 효과적입니다.
3. Approach
3.1. Overall Framework
HIVT의 전체 framework는 아래 그림과 같습니다. Vectorized approach에 따라서 우선 traffic scene으로부터 vectorized entities를 추출해 줍니다. 그다음 각 agent에 대해서 local context features를 encoding 해줍니다. 다음으로 global interaction module이 local context feature들을 모아서 각 agent의 global relationship을 추출합니다. Hierarchically 하게 local 및 global relationship 정보를 얻어내는 것이 이 논문의 주요 contribution이었습니다.

3.2. Scene Representation
Vectorized approach로 vectorized entities를 어떻게 추출하는 것인지 자세히 설명하겠습니다. 우선 scene으로부터 vector를 추출하려면 기본적으로 relative position을 활용하는 수밖에 없습니다. 왜냐하면 벡터는 기본적으로 출발 지점과 도착 지점에 대한 정보가 있어야만 대상의 정보를 벡터로 표현할 수 있기 때문입니다. 따라서 HIVT 논문에서는 특정 i 번째 agent의 trajectory를 아래와 같이 표현합니다.
$Agent \ i’s \ trajectory \ = \ {\lbrace P_ {i}^{t} - P_ {i}^{t-1} \rbrace}_ {t=1}^{t=T}$
$P_i^t$는 t 시점에서 agent i의 위치를 의미합니다. 따라서 시간에 따라서 얼마나 location이 변화하였는지가 벡터 정보로 담기게 됩니다. 이러한 표현 방식은 scene이 바뀌더라도 벡터 정보는 변화가 없다는 장점이 있습니다. Agent 하나에 대한 정보 이외에도 차선의 정보와 차량과 차량 사이의 정보도 벡터로 추출합니다. 추출한 모습은 아래와 같습니다.
$Lane \ vector \ = \ p^{1}_ {\xi} - p^0_ {\xi}$
$Relative \ position \ vector \ = \ p^{t}_ {j} - p^{t}_ {i}$
차선에서 $p^{0}_ {\xi}$는 차선의 시작 지점을 의미하며, $p^{1}_ {\xi}$은 차선의 끝 지점을 의미합니다. 그리고 차량과 차량 사이의 relative position 또한 vector 정보로 추출되는데, 이 경우 특정 t 시점에서의 정보로 추출합니다. i 번째 agent의 trajectory는 과거와 현재 시점 사이의 위치 차이로 벡터가 나타났던 점과 비교되는 표현 방식입니다.
3.3.1 Local Encoder
다음으로 local relationship을 어떻게 추출하는 것인지 살펴보겠습니다. Local encoder는 특정 agent를 중심으로 local 영역에서의 relationship을 추출하는 역할을 합니다. 그렇다면 각 agent를 중심으로 entities 사이의 relationship을 어떻게 추출할 수 있을까요?
우선 하나의 agent를 중심으로 각 entities의 relationship을 추출하려면 기준이 되는 중심 벡터가 필요합니다. 앞서 벡터는 relative position으로 결정해야 한다고 하였습니다. 따라서 기준이 되는 벡터는 agent i의 T 시점과 T-1 시점 사이에서의 위치변화로 표현됩니다. 앞으로 이 벡터를 Local Region Reference Vector (LRRV)라고 표현하겠습니다.
$Local \ Region \ Reference \ Vector(LRRV) \ = \ P_ {i}^{T} - P_ {i}^{T-1}$
이제 이 LRRV가 scene에서 기준이 되었으므로, local 영역에서의 relationship을 고려하려면 주변 entities 벡터들도 이 기준에 맞춰서 다시 표현해야 합니다. 따라서 LRRV의 head 방향이 scene을 표현하는 frame으로부터 돌아간 각도만큼 local scene 상의 모든 벡터를 회전시켜 줍니다. 이 과정을 거치면 local encoder를 위한 데이터의 전처리는 끝났습니다.
이제 중심 벡터와 회전된 벡터들을 MLP에 넣어서 embedding을 추출합니다. $\phi_{center}(.)$와 $\phi_{nbr}(.)$은 각각 중심 agent와 주위 entities가 거치는 MLP block을 의미합니다. 최종 추출된 embedding은 아래와 같습니다.
$z_ {i}^{t} = \phi_ {center}([R_ {i}^{T}(p_ {i}^t - p_ {i}^{t-1}), a_ {i}])$
$z_ {ij}^{t} = \phi_ {nbr}([R_ {i}^T(p_ {j}^t - p_ {j}^{t-1}), R_ {i}^T(p_ {j}^{t} - p_ {i}^{t}) , a_ {j}])$
위의 $z_ {i}^{t}$는 central agent i 의 embedding을 의미하며, 아래의 $z_ {ij}^{t}$는 neighboring agent j 들의 embedding을 의미합니다. 이때 central agent의 embedding은 query vector로 변환되며, neighboring agent의 embedding은 key와 value vector로 변환됩니다. 변환을 위해 사용한 $W^{Q^{space}}, \ W^{K^{space}}, \ W^{V^{space}}$는 학습할 수 있는 linear projection matrix입니다. 변환된 모습은 아래와 같습니다.
$q_ {i}^{t} = W^{Q^{space}}z_ {i}^{t},\ k_ {ij}^t = W^{K^{space}}z_ {ij}^{t}, \ v_ {ij}^{t} = W^{V^{space}}z_ {ij}^{t}$
이 query, key, value를 기반으로 scaled dot-product attention을 계산합니다. 이때 HIVT에서는 기존의 연구들과 다르게 gating function을 활용해서 environmental features인 $m_ {i}^{t}$와 central agent의 feature인 $z_ {i}^{t}$의 정보를 합칩니다.
$\alpha_ {i}^{t} = softmax(\frac{q_ {i}^{t^{T}}}{\sqrt{d_ {k}}}\cdot[{\lbrace k^{t}_ {ij} \rbrace}_ {j\in N_ {i}}])$
$m_ {i}^{t} = \sum_ {j \in N_ {i}}\alpha_ {ij}^{t} v_ {ij}^{t}$
$g_ {i}^{t} = sigmoid(W^{gate}[z_ {i}^{t}, m_ {i}^{t}])$
$\hat{z}_ {i}^{t} = g_ {i}^{t} \odot W^{self}z_ {i}^{t} + (1-g_ {i}^{t}) \odot m_ {i}^{t}$
Multi-head attention block의 output은 MLP block에 들어가고, 최종적으로 time step t에서 agent i의 spatial embedding인 $S_i^t$를 추출하게 됩니다.
지금까지의 과정을 담당하는 모듈을 agent-agent interaction module이라고 합니다. 이 모듈로부터 추출된 정보인 $S_ {i}^{t} \in \mathbb{R}^{d_ {h}}$는 오직 spatial information만을 포함하고 있습니다. 따라서 temporal information 또한 포함하여야 적절히 local region에서 entities 사이의 relationship을 고려하였다고 할 수 있을 것입니다. 본 논문에서는 feature에 temporal 정보를 담기 위해서 agent-agent interaction module 위에 transformer encoder를 하나 추가합니다.
앞서 agent-agent interaction module은 time step t에서 agent i의 spatial embedding인 $S_i^t$를 추출한다고 하였습니다. 그러므로 다른 time step t-1, t-2 … 1 에서의 spatial embedding인 ${ \lbrace S_ {i}^{t} \rbrace }_ {t=1}^T$ 또한 추출할 수 있을 것입니다. 이제 BERT와 비슷하게 extra learnable token인 $S^{T+1} \in \mathbb{R}^{d_ {h}}$을 추출된 데이터에 추가해 줍니다. 추가된 데이터의 최종 모습은 아래와 같습니다.
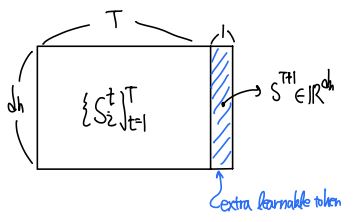
이제 여기에 learnable positional embedding을 모든 token에 추가하고, 이를 새로운 matrix에 token을 stack 합니다. 그다음 최종 출력 결과인 $S_ {i} \in \mathbb{R}^{(T+1) \times d_ {h}}$를 temporal attention block에 넣어줍니다. 앞서 agent-agent interaction module에서는 center agent i로부터 query를 뽑고, 주변 agent j로부터 key와 value를 뽑았었습니다. 그와는 다르게, 이번에는 $S_ {i}$만을 써서 query, key, value 값을 뽑아줍니다. 이로부터 scaled dot-product attention을 계산하고 MLP block에 넣어서 최종 결과인 $\hat{S_ {i}}$ 뽑아냅니다. 이 결과는 local region에서의 spatial 정보와 temporal 정보를 모두 포함하고 있습니다. $\hat{S_ {i}}$를 앞으로 spatial-temporal feature라고 하겠습니다.
$Q_ {i} = S_ {i} W^{Q^{time}},\ K_ {i} = S_ {i} W^{K^{time}},\ V_ {i} = S_ {i} W^{V^{time}}$
$\hat{S_ {i}} = softmax(\frac{Q_ {} K_ {i}^{T}}{\sqrt{d_ {k}}} + M)V_ {i}$
지금까지 local region에서 spatial 정보와 temporal 정보가 포함된 feature 값을 얻어냈습니다. 하지만 이는 agent 사이의 관계만을 고려한 정보로, 차선과의 관계는 아직 고려되지 않은 feature입니다. 따라서 agent-lane interaction으로 고려해 주기 위해서 spatial-temporal feature인 $\hat{S_ {i}}$를 query로 쓰고, 기준 agent에 맞게 회전된 lane 정보를 key와 value 값으로 사용하여 최종 local embedding인 $h_ {i} \in \mathbb{R}^{d_ {h}}$를 뽑습니다. Local encoder의 최종 출력값인 $h_ {i}$는 spatial, temporal, lane 등의 정보가 함축된 feature입니다.
Local Encoder의 모델이 꽤 복잡하므로, embedding 추출 과정을 그림으로 요약해 보았습니다. 큰 틀에서 요약된 과정을 담았으므로, 글과 함께 보시는 것을 추천해 드립니다.
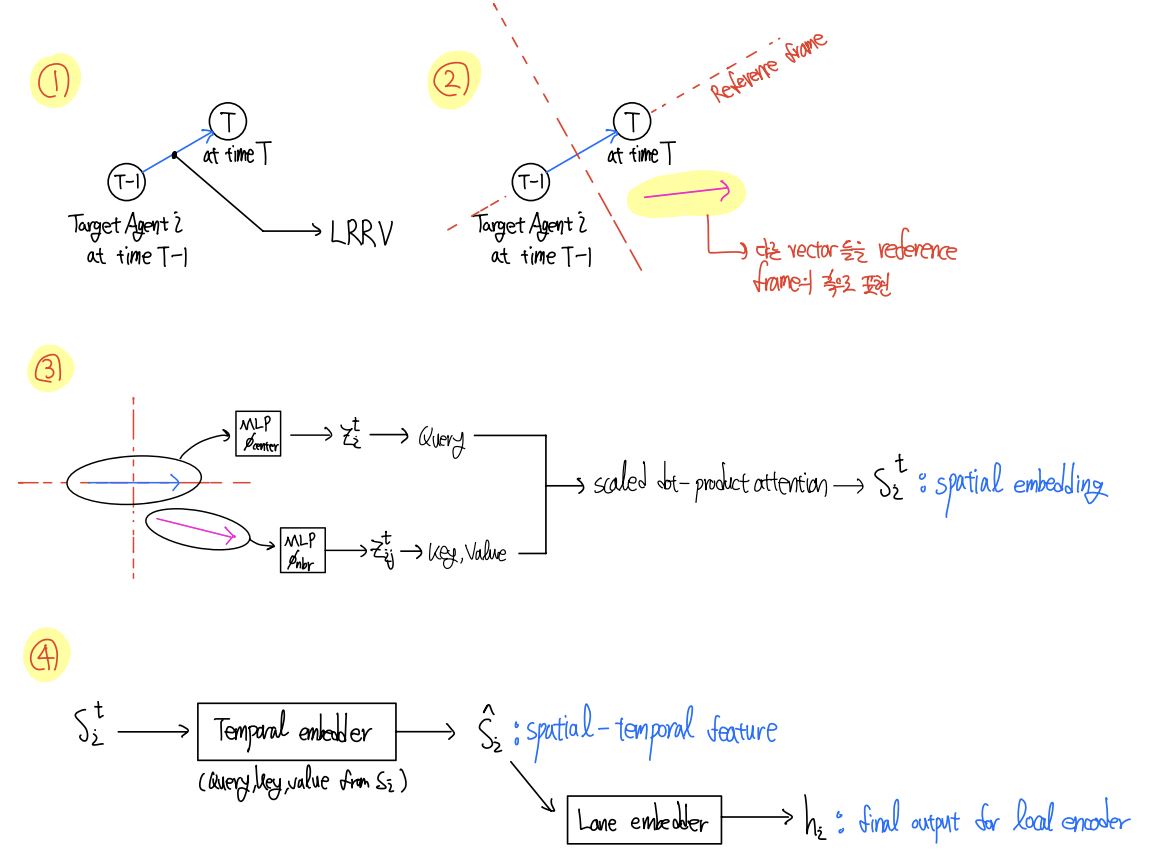
3.3.2. Global Interaction Module
지금까지 local encoder의 동작 과정을 살펴보았습니다. agent-agent interaction module을 통해서 agent 사이의 spatial 정보를 feature에 담았고, temporal attention block으로 temporal 정보를 feature에 담았습니다. 마지막으로 agent-lane interaction을 고려해 주기 위해서 spatial-temporal feature와 lane 사이의 attention을 계산하여 agent와 agent 사이의 spatial과 temporal 정보, 그리고 agent와 lane 사이의 정보를 feature에 담아주었습니다.
하지만 local feature만으로는 scene에서 vector entities 사이의 relationship을 모두 표현했다고 보기 어렵습니다. 왜냐하면 지금까지 추출한 local feature는 agent를 중심으로 하는 좌표계로부터 정보를 추출하였기 때문입니다. 따라서 global interaction module에서는 각 agent의 좌표계(frame) 사이의 정보를 포함하고 있어야 합니다. 그래서 global interaction module은 transformer encoder를 써서 이 정보를 feature에 담아줍니다. 이때 i agent와 j agent의 좌표계 차이에 대한 정보를 $e_ {ij}$에 담고, 이를 기반으로 query, key, value를 만든 후, attention block과 MLP block을 거쳐서 최종 global representation인 $\hat{h_ {i}}$를 추출합니다.
3.3.3. Multimodal Future Decoder
지금까지 Encoder의 설계를 마쳤습니다. 이제 출력 부분을 담당하는 Decoder 부분을 살펴봅시다. 일반적으로 trajectory prediction에서는 agent가 할 미래의 행동을 단순히 하나로 결정할 수는 없습니다. 왜냐하면 agent가 특정 상황에 놓였을 때, agent의 의도에 따라서 좌회전할 수도 있고, 직진을 할 수도 있기 때문입니다. 따라서 우선 가능성이 있는 미래의 경로를 여러 개 생성해 두고, 각 경로로 갈 확률이 얼마인지 출력하는 것이 합리적입니다. 이를 multi modal prediction이라고 부르는데, 본 논문 또한 이 방식을 채택합니다. HIVT에서는 multi modal prediction을 위해서 mixture model을 활용합니다. 각 mixture component가 Laplace distribution을 따르는 mixture model의 parameter를 decoder에서 출력하고, each timestep마다 single shot으로 한 번에 각 agent의 미래 경로와 associated uncertainty(이 경로가 얼마나 타당한지를 판별해 주는 값)를 추출합니다. 정확한 output의 형태는 아래 그림과 같이 [F, N, H, 4]의 크기를 가지며, mixing coefficient를 담는 matrix는 [N, F] 크기를 가집니다.

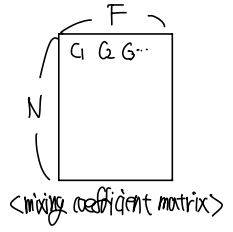
3.4. Training
모델을 학습하기 위해서는 loss를 어떻게 설정하는지가 중요합니다. Loss를 파악하기 위해서는 model의 output에 대한 이해가 필요합니다. 모델에서 예측한 결과와, ground truth 사이의 차이가 곧 loss가 될 테니까요. 쉽게 이해하실 수 있도록 직접 그림을 그려보았습니다. 우선 기존 decoder의 output이 [F, N, H, 4] 형태였습니다. 이때 그림에서 파란색 직사각형 블록은 N개의 agent 중 하나에서 F개의 mixture component 중 하나를 기반으로 각 timestep에서의 위치와 associated uncertainty를 추출한 것입니다. 따라서 이 예측된 경로와 ground truth와의 error를 각 timestep에서 계산한 후, 이들을 합쳐서 [F, N] 크기의 최종 error matrix를 생성합니다.

다음으로 error matrix에서 각 column 상에서 가장 error 값이 작은 것을 선택합니다. 그다음 이들을 더해서 최종 $loss_ {reg}$를 구합니다. 가장 error 값이 작은 것을 선택하는 이유는 가장 잘 예측한 경로를 기반으로 loss를 계산하려고 하기 때문입니다.
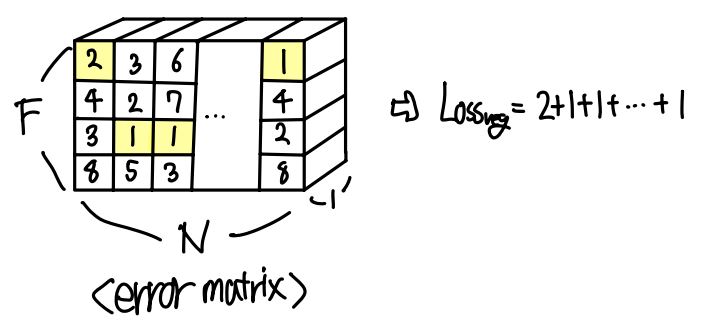
추가로 [N, F] 크기의 mixing coefficient matrix를 최적화하기 위해 cross-entropy loss를 써서 $loss_ {cls}$를 구합니다. 최종 loss는 추가 weight 없이 $loss = loss_ {reg} + loss_ {cls}$ 로 주어집니다.
4. Experiments
4.1. Experimental Setup
Dataset은 argoverse motion forecasting dataset을 사용합니다. 모델의 성능을 측정하기 위한 metric으로는 minimum Average Displacement Error(minADE), minimum Final Displacement Error(minFDE), Miss Rate(MR)를 사용합니다. minADE는 가장 잘 예측한 trajectory와 ground-truth trajectory 사이의 l2 distance를 모든 timesteps에서 계산해 줍니다. 반면 minFDE는 모든 timesteps가 아닌 마지막 timestep에서 l2 distance를 계산합니다. MR은 ground-truth 데이터의 endpoint와 가장 잘 예측한 경로의 endpoint 사이의 거리를 2.0 meter로 나눈 값입니다. 이때 “가장 잘 예측했다”를 판단하는 기준으로는, 예측한 trajectory의 마지막 지점인 endpoint가 얼마나 ground-truth의 endpoint와 가까운가로 두었습니다.
4.2. Ablation studies
HIVT에서는 다양한 모듈을 활용하여 모델을 설계하였습니다. Agent-agent interaction module, temporal module, agent-lane interaction module, Global Interaction Module로 총 4가지 모듈을 사용하였습니다. 본 논문에서는 각 모듈이 가지는 중요성을 검증하기 위해서 모듈을 하나씩 제거했을 때 성능에 어떤 변화가 있는지 확인하였습니다. 아래의 Table 1이 실험 결과입니다.
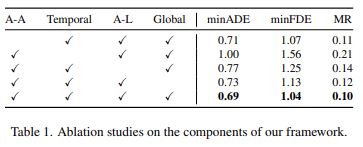
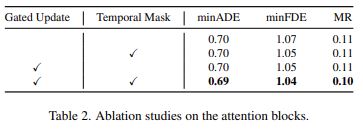
또한 앞서 설명하였듯이, spatial attention block에서는 다른 논문들과 다르게 gated update function을 썼고, temporal attention block에서는 temporal mask를 사용하였습니다. 이 방식이 모델의 성능 향상에 영향을 주었는지 확인하기 위해서 위의 방식과 동일하게 하나씩 제거해 가며 성능 변화를 확인하였습니다. 아래의 Table 2가 실험 결과입니다.
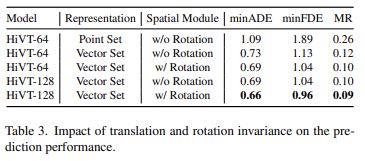
앞서 중심 벡터를 기준으로 scene을 정렬함으로써 translation과 rotation에 대한 강인함을 지닌다고 하였습니다. 이 강인함이 가져다주는 모델의 성능 향상을 확인하기 위해서 scene에 대한 정보를 단순히 point로 추출해서 학습에 넣어준 것(translation과 rotation에 민감)과 본 모델의 성능을 비교하였습니다. 아래의 Table 3가 실험 결과입니다.
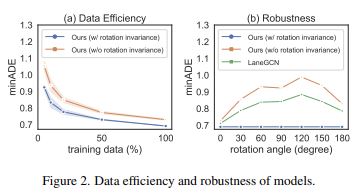
Rotation에 강인한 HIVT의 경우 training data를 더 적게 사용하여도 높은 성능에 도달하였으며, rotation이 생겼을 때 이전 연구의 모델인 LaneGCN보다 minADE가 더 작음을 확인할 수 있었습니다. 아래의 Figure 2가 실험 결과입니다.
4.3. Results
HIVT의 성능이 기존 모델의 성능보다 얼마나 좋은지 점검하였습니다. 앞서 설명한 metric(minADE, minFDE, MR)을 기반으로 모델의 성능을 평가하였고, 추가로 model의 inference speed도 같이 평가하였습니다. 아래의 Table 5가 실험 결과입니다. Table에서 r 값은 local region의 반경을 의미하며, local region을 50미터 반경으로 설정할 때 가장 성능이 높게 나옴을 확인하였습니다.

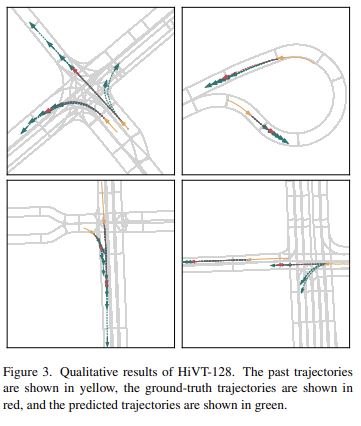
최종 모델인 HiVT-128의 Qualitative results는 아래의 Figure 3과 같습니다. 한 scene에서 2개의 agent만 visualize 한 모습이며, 적절한 prediction을 하는 것을 확인할 수 있습니다. 놀라운 점은 데이터 셋이 신호등의 상태에 대한 정보를 포함하고 있지 않음에도 불구하고, 왼쪽 위 그림의 교차로 상황에서 차량이 급가속할 것을 정확히 예측하였습니다.
5. Conclusion
본 논문은 local interaction과 global interaction을 hierarchically 하게 학습한 최초의 framework를 개발하였습니다. 또한 translation에 강인한 scene representation 방식과 rotation에 강인하게 만드는 transformer architecture를 설계하여 모델의 성능을 향상했습니다. HIVT는 기존의 trajectory prediction model보다 정확도와 속도 측면에서 더 높은 성능을 보였습니다.
해당 논문은 2022년도 CVPR의 논문으로, 2023년도 CVPR의 QCNet에서 prediction 성능을 더욱 향상했습니다. 본 논문 리뷰를 재밌게 보셨다면 QCNet논문도 추천해 드립니다. 제 설명에서 이해가 안 가시거나 궁금한 점 있으시다면 언제든지 연락 부탁드립니다. 긴 글 읽어주셔서 감사드립니다.
paper-reviewer: 20243565 이기원
Reference
[1] Kiran, B. R., Sobh, I., Talpaert, V., Mannion, P., Al Sallab, A. A., Yogamani, S., & Pérez, P. (2021). Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems. 23(6), 4909-4926