[NeurIPS 2023] EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
1. Introduction
Tasks involving embodied AI, like embodied planning, embodied visual question answering (VQA), and embodied control, aim to equip robots with the capacity to perceive, analyze, and act within their surroundings. This enables them to devise long-term plans and carry out actions independently based on real-time observations. Recent advancements in large language models (LLMs) such as OpenAI GPT-4 and an embodied multimodal language model called PaLM-E have demonstrated significant progress in language comprehension, reasoning, and the ability to maintain a coherent chain of thought. These developments could potentially lead to the creation of robots capable of understanding natural language instructions, engaging in multi-modal chain-of-thought processes, and strategizing actions in physical environments.
2. Problem Definition
The core problem addressed by the paper is the challenge of integrating large language models (LLMs) with embodied AI, specifically aiming to improve robots’ understanding and execution of tasks within physical environments through natural language instructions and multi-modal inputs. The study seeks to address the gap in existing LLM applications, which often struggle with the complex requirements of embodied tasks that require egocentric vision and real-time interactive capabilities.
3. Motivation
The motivation behind this paper is to enhance the ability of robots to understand and execute complex tasks in a physical environment by leveraging advancements in LLMs and multi-modal understanding. The traditional LLMs, while powerful in language processing, are not directly applicable to robotics due to the domain-specific nature and the need for real-time processing, environmental understanding, and task-specific action execution, areas where traditional LLMs falter due to their primary design for text and static image processing tasks.
Current approaches to bridging the gap between language models and robotic execution involve either adapting general-purpose LLMs to specific tasks or developing narrowly focused models that can handle only a subset of interactions. For instance, a universal visual representation for robot manipulation model like R3M focus primarily on learning robust visual representations from video data without integrating language-based planning. Building on this, a bootstrapping language-image pre-training with frozen image encoders and large language models like BLIP-2 introduces improvements by integrating language understanding with visual input, but still lacks a mechanism for planning and executing complex, sequential tasks that involve interactions with multiple objects in dynamic environments.
4. Method
Framework
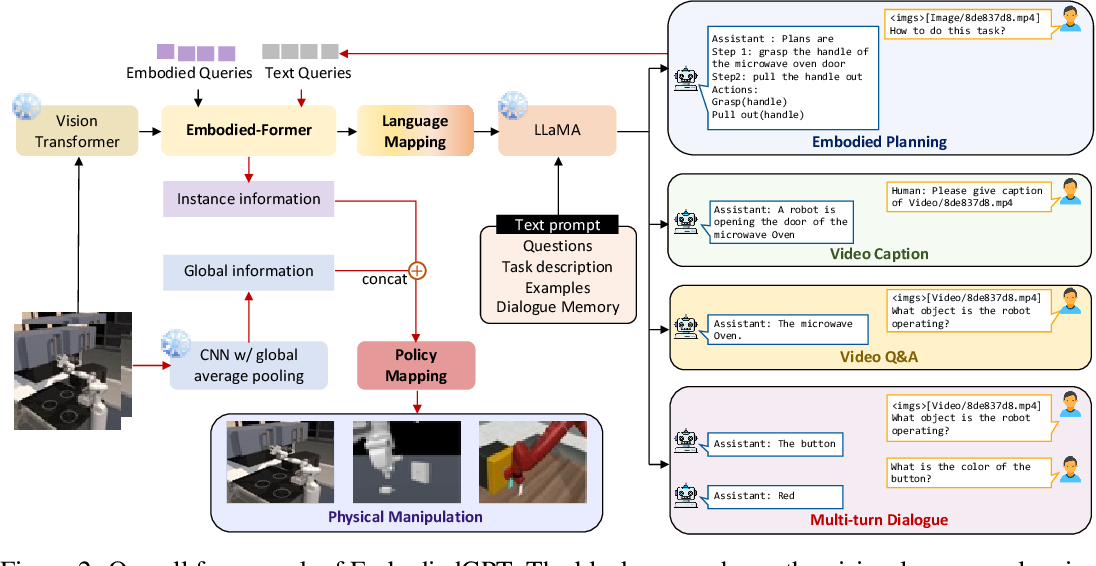
The EmbodiedGPT framework is designed to mimic human interaction with the environment by integrating advanced perception and task planning capabilities. It combines a pre-trained vision transformer with a a collection of foundation language models ranging from 7B to 65B parameters called LLaMa model, facilitated by the embodied-former that serves as a connector between visual and linguistic information. This setup allows for the extraction and linguistic mapping of visual features for applications in visual captioning, visual QA, and embodied planning. The planning outputs are then used to select relevant features from the visual model, which are transformed into actionable control commands via a downstream policy network. A unique aspect of the EmbodiedGPT’s approach is its video-language pre-training method, which employs a cognitive chain of thought process with egocentric video inputs to generate embodied planning. This process is structured similarly to a Visual Question Answering (VQA) task, enhancing the model’s ability to engage with and execute tasks by focusing on task-specific features essential for control. This comprehensive framework, including its innovative pre-training strategy, is depicted in the overall framework figure of EmbodiedGPT, illustrating how it operationalizes visual and linguistic data for embodied task performance.
The training of the EmbodiedGPT model unfolds in three stages:
- The initial stage centers on aligning image-text conversations, focusing on the pre-training of the Embodied-former and language projection while maintaining frozen vision and language model parameters to conserve computational resources.
- The second stage aims to refine the model’s understanding and generation of complex sentences and its reasoning abilities.
- In the final stage, embodied “chain-of-thought” training with EgoCOT is advanced, adapting the vision model for video encoding through a 3D object recognition using Convolutional Neural Networks (CNN) called Conv3D, focusing on spatio-temporal understanding. The pre-trained vision model is transferred to the video encoder using Conv3D with a time offset of 2 and a frame count of 8. The ‘chain-of-thought’ vision language pre-training paradigm is introduced, where 8 keyframes along with a task description, embodied planning elements, and a structured verb-noun pairs summary are used to reason with prompts. To avoid overfitting, prompts with varied instructions but the same meaning are provided. Fine-tuning is performed on the patch embedding, language projection layer, and prefix language adapter to better capture temporal information, enhancing the model’s understanding and analysis of temporal dynamics in video data. An example of such a prompt can be seen below.
Watch this video , identify the actions and devise a plan using chain -of - thought . Extract detailed actions using this schema :
Task : “task description”
Plan : “plan with chain -of - thought”
Actions : “number”: ‘verb’ (‘noun’) .
For example, if the task is to open a door, EmbodiedGPT processes the visual input of the door, generates a language-based plan detailing steps like “approach door”, “grasp handle”, “turn handle”, and then executes these steps through the robotic control systems.
Model Architecture
The Embodied-former, denoted as $\varepsilon(·)$, is used as a bridge between visual input $x_ {vis}$ and the frozen language model, serving as an information bottleneck to deliver the most relevant visual data to the language model. The embodied former consists of two sub-modules:
- extracting input from the image features is denoted as:
$\varepsilon_ {vis}:x_ {vis} \overrightarrow{}y_ {vis}$
- extracting from the text input is denoted as:
$\varepsilon_ {txt}:x_ {txt} \overrightarrow{} y_ {txt}$
where $N$ is the learnable embodied query embeddings $y_{query}$ as the input of $\varepsilon$ to interact with $x_{vis}$ through cross-attention layers and with $x_{txt}$ thorugh self-attention layers. then the output query is denoted as: $z\in R^{N \times D}$ and $D$ is the dimesionality of embeddings.
the output query are then transformed to $z’\in R^{N \times D^{‘}}$ which have the same dimesionality $D^{‘}$ as the the language model’s text embedding in the language modality. This transformation is performed by a mapping function, denoted as $M : z\overrightarrow{} z^{‘}$, via a linear projection through a fully-connected (FC) layer. The projected embeddings, $z^{‘}$, serve as “soft visual prompts” for the language model, decoupling the interaction into visual-query and query-text interactions. The final embodied planning is inferred by the language model using $z^{‘}$ and a text prompt as input. For low-level control, the embodied plan $x_{plan}$ is used as input text for the Embodied-former to query task-relevant instance-level features $z_{instance}=E(x_{vis},x_{plan},y_{query})$.
Subsequently, control commands, such as the turning angle of the servo, are generated by combining both instance-specific information $z_{instance}$ and global context $z_{global}$. The global context is inferred using a pre-trained ResNet50 model, employing global average pooling. The function $g(⋅)$, representing the policy network, is a Multi-Layer Perceptron (MLP) mapping function. The output of the policy network consists of specific executable actions, such as positions and velocities in the Cartesian coordinate system.
5. Experiment
Dataset
-
EgoCOT Dataset: Derived from the Ego4D dataset, a massive-scale egocentric video dataset and benchmark suite that offers 3,670 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 931 unique camera wearers from 74 worldwide locations and 9 different countries, which initially contained 9,645 unedited videos with durations between 5 seconds and 7 hours. After excluding videos with insufficient narrations, unclear labels, and lacking human-object interaction, the refined dataset includes 2,927 hours of video footage with 3.85 million narrations. Each video segment is paired with a relevant caption. A further data refinement step uses the CLIP model to assess the correlation between video content and textual descriptions. The CLIP model encodes the text $T$ and the image $I$, using the cosine similarity function to calculate the ensemble similarity score: $E(V,T)=\frac{1}{n}\sum_{i=1}^{n}S(yT_i,yI_i)$ Here, $E(V,T)$ represents the ensemble similarity score, $S(yT_i, yI_i)$ is the similarity score between text and image for the $i$-th keyframe, and $n$ is the total number of keyframes.
-
EgoVQA: Developed for video question answering tasks involving egocentric human-object interactions to enhance the dataset’s diversity. For each video caption, ChatGPT generates five question-answer pairs. To ensure relevance, ChatGPT is guided to focus on core key verbs and nouns by designing prompts as shown below, utilizing a sampling method consistent with that of EgoCOT.
Please ask some questions accroding to the verbs and nouns in the sentence . For example , in this sentence “ a man is picking up a cup “ , the verb is picking up and the noun is cup , therefor questions can be “ what is the object the man is picking up ?” or “ what operation is performed on the cup ?”. Then You need to give the answer .
input : a man is picking up a cup question : What is the object the man is picking up answer : The cup
Baseline
The baselines for comparison include BLIP-2 and R3M. BLIP-2 is known for its capabilities in multi-modal (language and vision) processing but lacks specific optimizations for embodied tasks. R3M is focused on robust visual representation learning, making it a relevant baseline for evaluating the visual understanding capabilities of EmbodiedGPT.
Evaluation Metrics
Success rates are measured by the percentage of tasks successfully completed by the robots. The qualitative analysis involves human evaluators rating the reasonableness and executability of the plans generated by the models.
Result
Image input
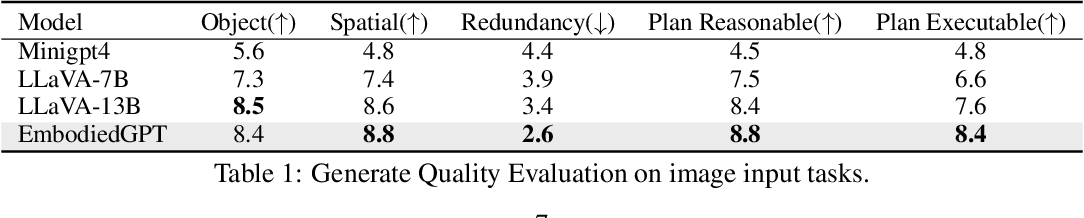
Table 1 shows the average score of image input task for different models. The results indicate that EmbodiedGPT matches the performance of the LLaVA-13B model in terms of object recognition and understanding spatial relationships, even though it operates with a smaller language model that has only 7B parameters.

The above figure is a comparison they did between EmbodiedGPT and Visual ChatGPT, Visual ChatGPT was unable to locate a coat hanger because it depends only on the caption model to derive visual information. This method led to inferior performance compared to the more comprehensive end-to-end approach used by EmbodiedGPT.
Video input
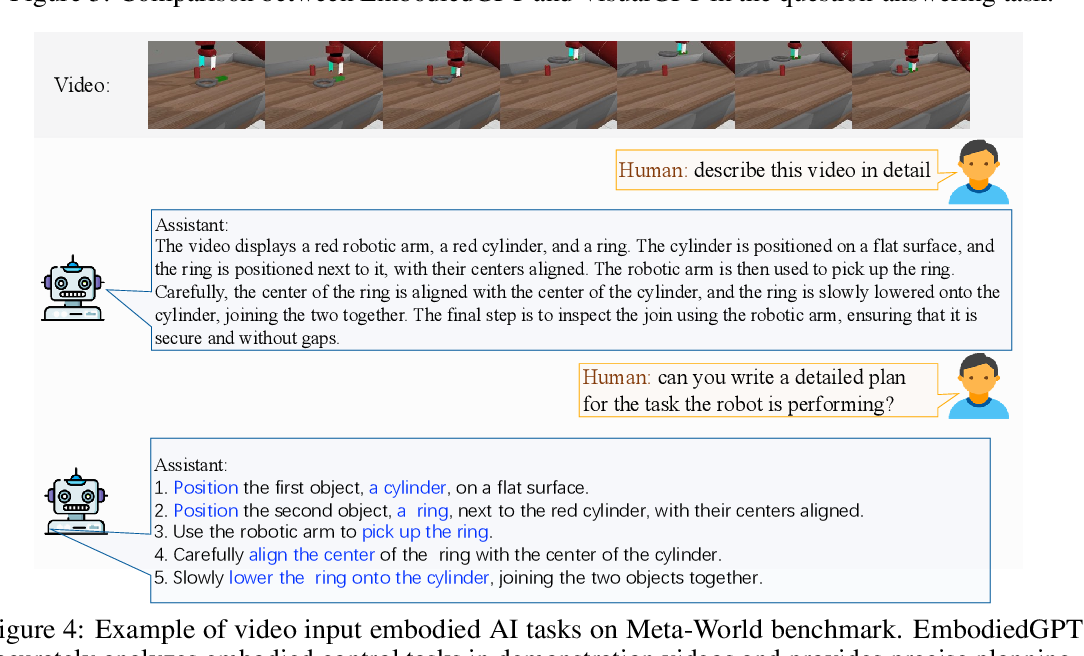
The video recognition and task planning capabilities of EmbodiedGPT are assessed on established embodied AI benchmarks, Franka Kitchen and Meta-World. Meta-World involves complex tasks such as assembling objects and operating machinery, while Franka Kitchen focuses on everyday tasks like opening doors and cabinets, and using kitchen appliances. As demonstrated in the above figure, EmbodiedGPT effectively interprets and plans out steps for these tasks based on demonstration videos.
Embodied control tasks
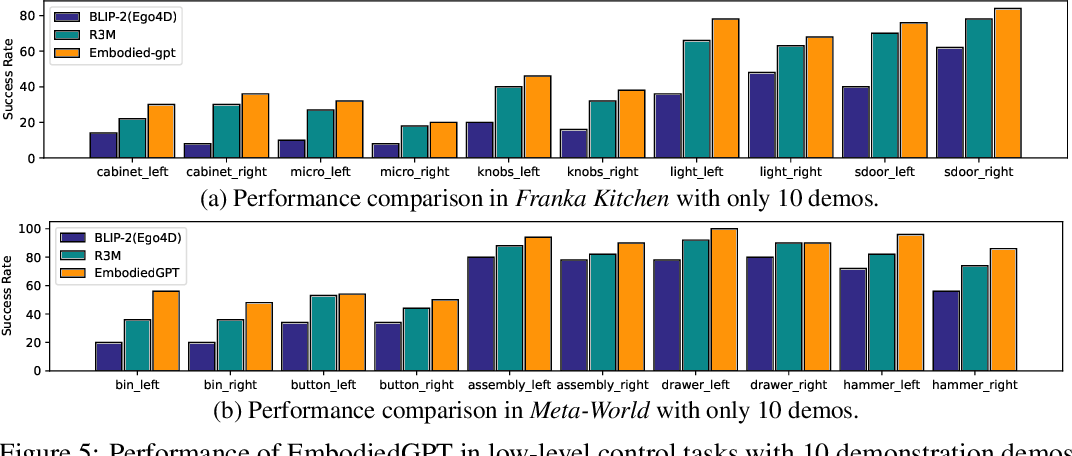
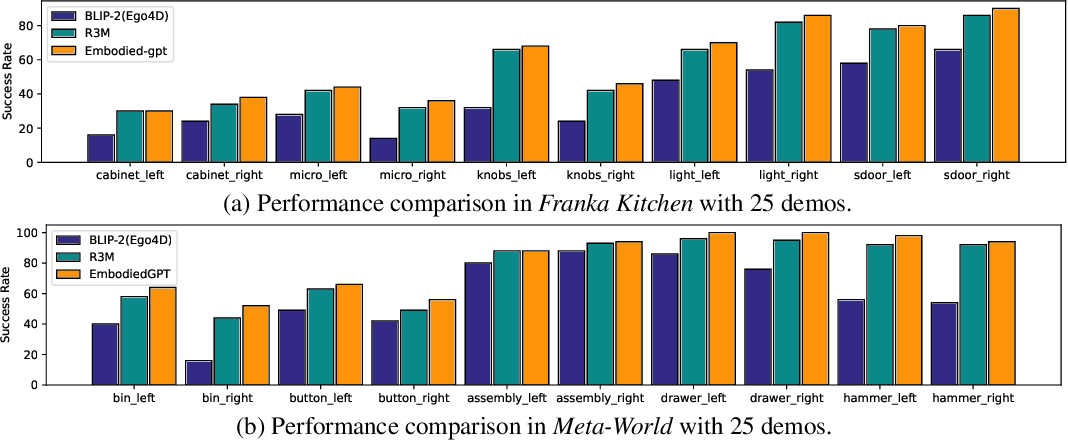
In embodied control tasks, EmbodiedGPT is benchmarked against R3M, the current leading method, and a variant known as ‘BLIP-2[Ego4D]’, which mirrors EmbodiedGPT in structure and parameter count. The evaluations are conducted in two scenarios: one using 10 demonstrations and another using 25. Success rates are calculated based on 100 random trials that focus solely on visual observations, spanning five tasks across each benchmark, with results from five different seeds and two camera angles. The performance of EmbodiedGPT in these setups is depicted in the two figures above.
5. Conclusion
EmbodiedGPT showed a marked improvement in success rates, achieving a 1.6 times increase on the Franka Kitchen benchmark and a 1.3 times increase on the Meta-World benchmark relative to the BLIP-2 model fine-tuned on the same datasets. This significant enhancement highlights EmbodiedGPT as a major advancement in integrating language models with robotic systems, providing a robust framework for executing complex tasks in dynamic environments. The introduction of the EgoCOT dataset and efficient training approaches also offers scalable solutions for embodied AI challenges. Key takeaways include the successful application of ‘chain-of-thought’ processes in embodied AI and the effective loop from high-level planning to actionable control, which significantly enhances the robot’s interactive and execution capabilities in real-world scenarios. However, EmbodiedGPT freezes the parameters of the vision and language model due to limited computational resources, which poses a limitation on its potential performance. Future work could explore joint training with all modules and incorporating other modalities, such as speech, to further enhance its capabilities. Despite these limitations, no obvious undesirable ethical or social impacts are foreseen at this moment. Exploring these avenues, along with integrating more diverse data types and reducing the computational demands of training such complex models, could provide significant advancements in the field.
6. Reference & Additional materials
Please write the reference. If paper provides the public code or other materials, refer them.
- Github Implementation
-
Paper Reference
Paper Reviewer
- Fania Ardelia Devira
- Department: Graduate School of Data Science, KAIST
- Contact: faniadevira@kaist.ac.kr