[Recsys 2021] Denoising User-aware Memory Network for Recommendation
Title
[Recsys 2021] Denoising User-aware Memory Network for Recommendation
1. Problem Definition
DUMN(Denosing User-aware Memory Network)은 User의 real click preference를 예측하는 것을 목표로 한다.
User의 선호를 파악하여 Click preference를 예측하는 연구를 CTR(Click-Through Rate) Prediction이라 하고 초기 model인 CF method부터 딥러닝을 활용한 다양한 모델들이 존재한다.
2. Motivation
Sequence-based recommendation system에서 implicit feedback에 noise가 있다는 사실은 대부분 고려되지 않는다. Noise가 존재한다는 것은 representation이 bias를 야기할 수도 있고, suboptimal recommendation performance를 보인다. 기존의 방법들은 user interest의 evolution를 포착하기 위해 utilize item sequence를 사용한다. 하지만 이 방법은 sequence의 길이에 대한 한계가 있기고 long-term interest에 대해 효과적인 model을 구성할 수 없다.
implicit feed back은 비교적 데이터가 많지만 nosie가 있을 확률이 높다. 대표적으로 click or unclick이 implicit feedback인데 실수로 click 했을 수도 있고 스크롤을 빨리 내리면서 상품을 인지하지 못해 click을 못했을 수도 있다. 이처럼 implicit feedback에는 다양한 요인으로 noise가 존재할 수 있지만 explicit feedback을 비교적 정확하다. explicit feedback을 통해 implicit feedback의 noise를 개선하는 모델을 제안한다.
새로운 CTR(Click-Through Rate) Model로 DUMN(Denosing User-aware Memory Network) 제안
DUMN의 Contribution
- Feature purification module based on orthogonal mapping(implicit feedback의 noise 제거)
- User memory network를 사용해 long-term interest에 대한 fine-grained(UMN, PAIR module)
- Develops a perference-aware interactive representation
3. Method
DUMN network는 4가지의 module로 구성되어 있다.
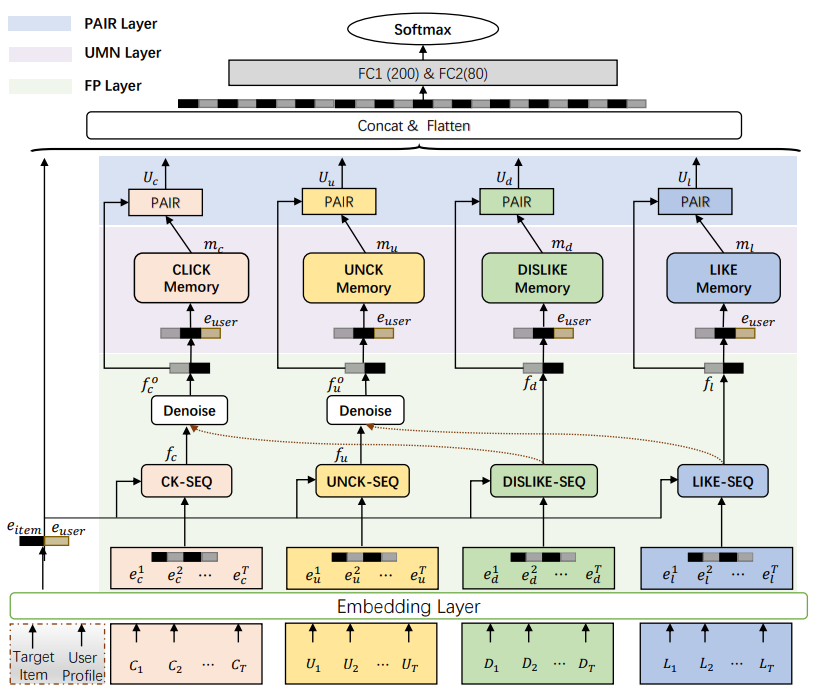
Embedding Layer
Embedding Layer는 user profile, ad, user behavior sequence를 Input으로 받는다. user profile, ad는 embedding layer를 사용하여 high dimensional sparse에서 low dimensional dense로 변환된다.
- user profile (user에 대한 정보)
-
user_id
-
user_gender
-
user_age
-
- ad (target item에 대한 정보)
-
item_id
-
brand_id
-
- user behavior sequence (feedback)
- Implicit feedback
- click sequence: $C=[C_1, C_2, …, C_T]$
- unclick sequence: $U=[U_1, U_2, …, U_T]$
- Explicit feedback
- dislike sequence: $D=[D_1, D_2, …, D_T]$
- like sequence: $L=[L_1, L_2, …, L_T]$
- Implicit feedback
$\longrightarrow$ maximum sequence length($T$)
Feature Purification Layer(FP)
FP Layer는 Short-term interest를 학습하기 위한 Multi-head Interaction-attention과 Implicit feedback를 orthogonal mapping method를 이용하여 정제하는 Denoise 구간으로 구성되어 있다.
Multi-head Interaction-attention
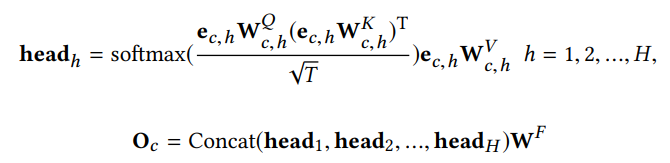
$e_c$는 Click sequence가 Embedding 된 값이다. 이를 H개의 head를 갖는 Multi-head Self Attention으로 학습한다. Multi-head Self Attention에 대한 설명은 이 논문의 주된 내용이 아님으로 생략한다. Multi-head Self Attention를 사용하는 이유는 Short-term에 대한 interest를 학습하는 것에 목적이 있다.
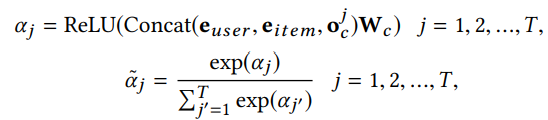
Multi-head Self Attention를 진행할때 유의해야 하는 부분은 Multi-head Self Attention의 Output $O_c$에 $e_{user}, e_{item}$을 Concat 시켜 Activation Function을 통과한 $\alpha$를 계산하여 Soft Max Function을 이용해 확률로 표현하게 된다. 아래 formula에서 j는 j번째 item에 대한 값이라는 뜻이다.
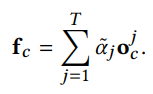
최종적으로 앞서 구한 를 대한 Multi-head Attention 값의 결과인 $O_c$에 가중평균한 것의 $f_c$이다. Click, Unclick, Like, Dislike 모두 동일한 방법으로 계산한다.
Feature Orthogonal Mapping
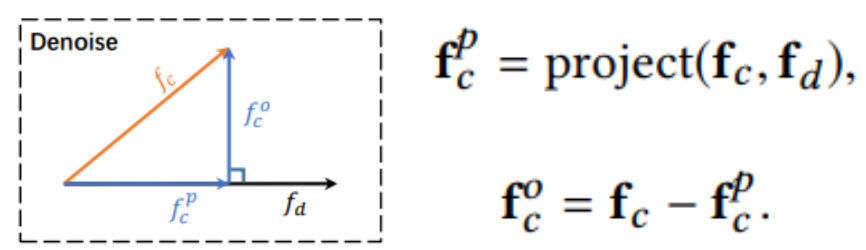
Muti-head Self Attention을 통해 구한 $f_c, f_u$는 implicit feedback에 대한 값이다. implicit feedback을 noise가 있기 때문에 상대적으로 noise가 없고 정확한 feedback인 explicit feedback을 이용하여 noise를 정제할 것이다. 이때 사용하는 것이 Orthogonal Mapping이다. 두 Vector가 Orthognal 하다는 것은 서로 연관성이 없다는 것이다. 따라서 서로 반대되는 관계라고 생각되는 <Click, Dislike>, <Unclick, Like>를 Orthogonal Mapping을 시키면 noise를 제거한 Implicit feedback을 얻을 수 있게 된다. Orthogonal Mapping은 Implicit feedback에 noise를 제거하는 이 논문의 핵심 아이디어 중 하나이다.
** User Memory Network Layer(UMN) **
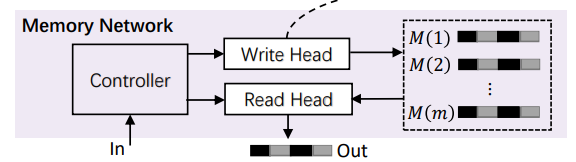
UMN Layer는 long-term preference에 대한 정보를 얻기 위해 사용자 관점에서 보다 안정적이고 세분화된 정보를 얻기 위해한 Layer이다. Memory Network에는 Memory read, write로 나누어지며 사용자의 long-term preference를 저장하거나 사용한다. 이러한 방식은 user_id embedding보다 선호되는 방식으로 long-term preference를 이해하는데 도움이된다. 또한 Controller를 통해 Write, Read의 정도를 조절하며 m개의 slot에 user의 정보를 저장한다.
Memory read
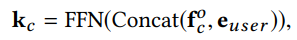
Memory read는 $k_c$를 통해 key를 생성한다. $k_c$는 $f_c^o, e_{user}$를 Concat한 것의 Fully connected layer를 통해 얻어진다.
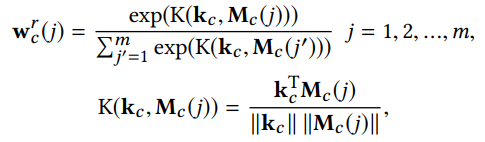
key 값을 slot에 저장되어있던 memory 값인 $M_c(j)$를 이용해 두 vector 사이의 연관성으로 정의할 수 있는 $K(k_c,M_c(j))$의 값을 구한다. 구한 값을 Softmax function을 이용하여 확률로 표현하고 이를 가중치로 $M_c$ 값들을 가중평균하면 최종적으로 Memory read 값인 $r_c$가 얻어진다. Click을 제외한 다른 Variable도 같은 방식으로 형성된다.
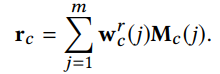
Memory write
Memory write도 기본적으로 memory read에서 $w_c^r$을 계산하는 방식은 같다. Memory write에서는 2가지 vector가 더 등장하는데 add와 erase vector이다. 계산 공식은 아래와 같다. * $\bigotimes$: Outer product
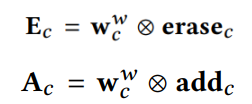
최종적으로 $M_c$는 아래 공식을 통해 계산된다. * $\bigodot$: Outer product
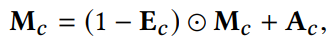
Preference-aware Interactive Representation Component(PAIR)
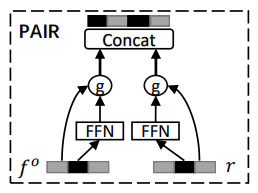
PAIR Layer는 User의 Long, Short-term interest에 대한 cross representation을 얻기 위한 Layer이다. 따라서 FP Layer에서 얻은 $f_o^c$와 UMN Layer에서 얻은 $r_c$를 사용한다. 위의 Layer들의 역할에 대해서 생각해보면 PAIR Layer가 Long, Short-term interest를 합치는 역할을 한다는 것을 이해할 수 있다. 아래 수식에 따라 계산하면 $U$를 얻을 수 있다.
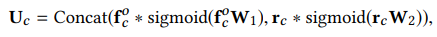
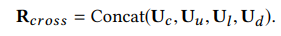
최종적으로 $U$들과 $e_{user}$, $e_{item}$를 Concat시켜 Fully connected layer를 통과해 Sigmoid Function에 넣으면 최종 예측 값인 $\hat{y}$를 얻을 수 있게 된다.
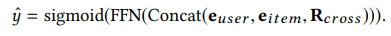
4. Experiment
Experiment setup
- Dataset : Alibaba & Industrial Dataset, train: 2020-12-25 ~ 2021-01-18, test: 2021-01-19 ~ 2021-01-24
- Baseline
- Non-sequence method : Wide&deep, PNN, DeepFM
- Sequence method : DIN, DIEN, DSIN, AutoInt, DFN, DMT
- Parameter Setting
- Maximum length T of each feedback sequence : 100
- Output dimension of the embedding layer : 16
- Dimension of the feed-forward network : 512
- Number of the slot in the memory network : 256
- Dimension of each slot : 64
- Learning rate : 0.005
- Optimizer : Adam
- Evaluation Metric : AUC
Result
RQ1.DUMN이 기존 SOTA methods 보다 더 우월한 performance를 보이는가?
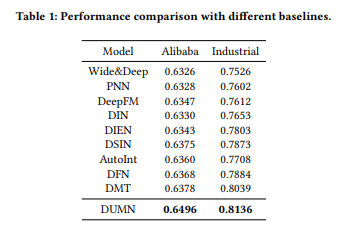
위 표의 결과를 통해 우리는 3가지 결론을 도출해낼 수 있었다.
Baseline으로 제시한 모든 Method 보다 DUMN이 더 좋은 성능을 보였다. Alibaba Dataset, Industrial Dataset에서 각각 1.18%, 0.97%의 성능 향상을 보였다.
또한, 우리는 위 표를 토대로 Sequence-based method가 Non-sequence-based method 보다 기본적으로 성능이 좋은 것을 확인할 수 있었다. 이는 User의 interest의 변화를 Sequence-based method가 더 잘 포착한다고 할 수 있다.
마지막으로 DFN은 Implicit Feedback, Explicit Feedback을 같이 사용하여 User의 interest를 학습한다. 반면에, DSIN은 Implicit Feedback을 Bi-LSTM통해 User의 interest를 학습힌다. 이러한 차이가 있음에도 거의 같거나 좋은 성능을 낸다는 것은 User의 interest를 세분화하여 예측한다면 더 Bias 없는 결과를 얻을 수 있다는 점을 알 수 있다. 따라서 DUMN처럼 User의 interest를 Long, Short-term으로 나누어 분석한다면 더 unbias한 결과를 얻을 수 있다는 점이다.
RQ2. 각 module들의 model에 어떠한 영향을 주고 있으며 실제로 성능을 향상 시키는데 도움이 되는가?
Effect of Feature Purification
Alibaba Dataset과 Industrial Dataset에 대해서 FP Layer가 없는 DUMN-FP의 결과는 각각 0.6417, 0.7981로 FP를 사용한 DUMN보다 낮다(RQ1에 있는 표에서 DUMN 결과 확인 가능). 즉, 본 논문에서 제시된 orthogonal mapping을 통한 denoise이 효과가 있다는 것을 알 수 있다.
Effect of User Memory Network Layer
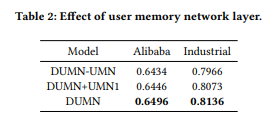
UMN을 사용하지 않은 DUMN-UMN과 4개의 Memory network를 사용하지 않고 1개의 Memory network를 사용한 DUMN+UMN1의 결과를 DUMN 결과와 비교해보면 4개의 UMN을 사용한 DUMN의 결과가 가장 좋은 것을 확인할 수 있다.
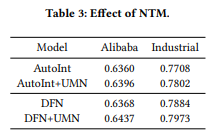
추가로 Long-Term interest를 사용하는 것이 성능 개선에 영향을 주었는지를 확인하기 위해 AutoInt과 DFN에 UMN을 추가하여 분석해보았다. 결과는 두 method 모두 Alibaba Dataset과 Industrial Dataset에서 성능이 상승한 것을 확인해볼 수 있었다. 이는 User의 Long-term interest를 활용하는 것이 User의 interest의 evolution을 이해하는데 도움이 된다는 사실을 보여준다.
Effect of Preference-aware Interactive Representation Component
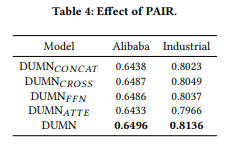
PAIR Layer의 목적은 Long,Short-term interest를 합성시키는 것이다. 따라서 우리는 합성 방식을 여러가지로 바꿔보면서 DUMN이 Gate를 이용하여 합성하는 방식이 최선인지 확인해보았다. Concat, Cross, FFN(Feed-forward network), ATTE(Attetion)를 사용하여 각각 결과를 살펴본 결과 DUMN의 기존 방식인 Gate를 이용한 방식이 가장 좋은 성능을 보였다. 즉, User의 interest가 item마다 다르게 영향을 주기 때문에 기조의 Gate 방식이 가장 잘 작동한다고 추정해볼 수 있다.
Effect of Implicit/Explicit Feedback
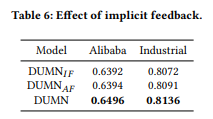
DUMN_IF는 Implicit feedback만 사용하고 $M_l$, $M_d$를 memory metwork layer에서 삭제한 model이다. DUMN_AF는 모든 type의 feedback을 시간을 통해 하나의 sequence로 연결한 Model이다. 위의 표를 보면 모든 유형의 User Feedback을 사용한 DUMN_AF가 더 뛰어남을 알 수 있다. 즉, Implicit feedback만을 사용하는 것은 User의 interest를 더 정확하게 이해하는데 어려움을 겪는다는 것이다. 또한, Feedback을 더 세분화하여 사용한 DUMN이 DUMN_AF보다 더 뛰어남을 볼 수 있는데, 다른 Feedback에 따른 User의 interest는 서로 다른 공간과 표현으로 세분화하여 분석할 필요가 있다는 것이다.
5. Conclusion
DUMN은 Implicit Feedback과 Explicit Feedback을 orthogonal mapping하여 Implicit Feedback의 Noise를 제거하는 방식으로 성능의 향상을 보여준다. Implicit Feedback을 Denoise하는 방법은 다른 추천시스템이나 AI Model에서도 사용할 수 있을 것 같다. 또한, CTR Prediction에 Implicit Feedback과 Explicit Feedback를 같이 사용하는 것에 대한 필요성을 제시하고, User의 interest를 Long, Short-term으로 세분화하여 학습한다. 이러한 방식은 기존 모델들에 비해서 뛰어난 성능을 보였으며 직관적으로도 이해하기 쉬웠다. 또한, 각 module에 대한 필요성을 실험으로 잘 증명하는 부분은 각 module의 역할과 전체 model에 미치는 영향을 이해하는데 도움이 되었다.