[CVPR 2023] DARE-GRAM_Unsupervised Domain Adaptation Regression by Aligning Inverse Gram Matrices
본 리뷰를 읽어주셔서 감사합니다. 다음 두가지 사항에 착안하여 최종적으로 리뷰를 수정하였습니다.
- 복잡한 부분에 설명을 추가하였고, 불필요한 수식을 문자 서술로 대체하였습니다.
- 실험과 본 연구의 연결성, 실험 결과에 대한 해석을 추가 서술하였습니다.
- 입력에 문제가 발생하는 수식을 사진으로 대체하였습니다.
0. Preliminaries
본 연구는 unsupervised domain adaptation regression task를 다룹니다.
문제 정의에 앞서, Domain Adaptation에 대해 간단히 설명드리겠습니다.
Domain Adaptation이란?
우리가 보유하고 있는 데이터셋으로 학습한 모델 $f(\boldsymbol x)$가 있다고 가정하겠습니다.
일반적인 머신러닝 task에서는 iid(independent and identically distributed) 상황을 가정합니다.
즉, 학습된 모델 $f$ 가 새로운 input에 대한 추론(inference)를 실시할 때, 그 input 데이터의 분포 역시 훈련 데이터의 분포와 다르지 않을 것이라고 가정합니다.
하지만 모델의 현실 적용에 있어서 iid와 같은 naive한 가정은 지켜지지 않는 경우가 많습니다.
만약 데이터의 분포 변화가 일어나게 된다면 분포 변화 이전의 데이터를 사용하여 학습된 모델 $f(\boldsymbol x)$는 분포 변화 이후의 데이터에 대해 높은 성능을 기대할 수 없을 것입니다.
이러한 데이터 분포의 변화를 극복하여 분포 변화 이후의 데이터에 대해서도 좋은 성능을 보이도록 하는 것이 바로 Domain Adaptation(이하 DA)입니다.
일반적인 DA에 관련한 context에서는 분포 변화 이전의 데이터를 Source domain data, 분포 변화 이후의 데이터를 Target domain data라고 일컫습니다.
1. Problem Definition
DA 는 Unsupervised, Supervised로 구분됩니다.
Unsupervised/Supervised의 구분은 Target domain data $\chi_ t$의 label ${ y_ t^i}_{i=1}^{N_t}$의 유무에 달려있습니다.
본 연구에서 다루는 Unsupervised DA(이하 UDA)에서는, source domain의 labeled samples $\chi_ s :={\boldsymbol{x}_ i^S,\boldsymbol{y}_ i^S}_ {i=1}^{N_ s}$ 과 Target domain의 unlabeled samples $\chi_ t:={\boldsymbol{x}_ i^T}_ {i=1}^{N_ t}$가 주어집니다. 여기서 $N_ s$와 $N_ t$는 각각 $\chi_ s$와 $\chi_ t$의 sample size를 의미합니다. Classification problem의 Discrete labels $\mathcal Y$와 달리, 본 연구에서는 continuous and multidimensional한 labels $\mathcal Y\subset \mathbb{R}^{N_ r}$ 를 대상으로 합니다.
$P(\chi_ s):=$ Source domain 데이터의 분포($y$를 포함하지 않는 $x$에 대한 marginal 분포)
$P(\chi_ t):=$ Target domain 데이터의 분포(마찬가지로 $x$에 대한 marginal 분포이며, 애초에 $y$가 주어지지 않았습니다.)
Preliminary에서 설명드린대로, $P(\chi_ s)$와 $P(\chi_ t)$의 discrepancy를 극복하는 것이 UDA에서 풀어야 할 문제입니다. 그렇다면 우리는 궁극적으로 Target domain에서도 좋은 일반화 성능을 보이는 모델 $F:\boldsymbol x\mapsto \boldsymbol y$ 를 학습해야 합니다.
우리는 source domain에 대해 데이터와 라벨 모두를 가지고 있기 때문에 다음의 MSE loss를 사용한 지도학습을 통해 baseline model을 다음과 같이 훈련시킬 수 있습니다.
$\mathcal{L}_ {src} = \frac{1}{N_ s} \sum_{i=1}^{N_ s} \left| \tilde{\boldsymbol y}_ s^i - \boldsymbol y_ s^i \right|_ 2^2$ (이 때 $\tilde{y}_ s^i=F(x_ s^i)$는 source domain data에 대한 baseline model의 예측 값입니다.)
하지만 Preliminary에서 설명드린대로, $P(\chi_ s)$와 $P(\chi_ t)$간에는 discrepancy가 존재합니다.
따라서, 당연히 Source domain data($\chi_ s$)만을 사용한 baseline model $F$로 Target domain data ($\chi_ t$)에 대한 예측을 수행해서는 안됩니다. $P(\chi_ s)$와 $P(\chi_ t)$간의 차이를 극복하기 위해서는, 학습에 있어 추가적인 제약이 필요합니다. 이에 본 연구에서는 source data $\chi_ s$만을 사용한 baseline model과는 다르게 $\chi_ s$와 $\chi_ t$를 모두 활용하여 Target domain에서도 좋은 일반화 성능을 보이는 모델 $F:\boldsymbol x\mapsto \boldsymbol y$ 를 학습하는 방법을 제시합니다.
수식을 사용하여 목표를 다음처럼 나타낼 수 있습니다.
$\arg \min\limits_ F \mathbb{E}_ {(\boldsymbol x^t, \boldsymbol y^t)} | F(\boldsymbol x^t), \boldsymbol y^t |_ 2^2$
이때 $\boldsymbol y^t$는 학습시에 주어지지 않습니다.(Unsupervised Domain Adaptation이기 때문입니다.)
2. Motivation
딥러닝을 사용한 Deep UDA에서의 일반적인 접근 방식에 대해 설명드리겠습니다.
UDA에서의 목표는 $P(\chi_ s)$와 $P(\chi_ t)$의 discrepancy를 극복하는 것입니다.
데이터 분포인 $P(\chi_ s)$와 $P(\chi_ t)$가 다르다는 것은, 각 분포의 marginal samples인 ${\boldsymbol{x}_ i^S}_ {i=1}^{N_ s}$와 ${\boldsymbol{x}_ i^T}_ {i=1}^{N_ t}$가 다르다는 것을 의미합니다. 서로 다른 분포의 데이터셋에 대해 동시에 좋은 예측을 하는 것은 쉽지 않은 일입니다. 그러나 Source domain data와 Target domain data간의 discrepancy가 존재한다고 하더라도, 두 데이터 간에 공유하고 있는 중요한 성질이 있을 것입니다. 그렇다면, 두 데이터 모두에 대해 좋은 성능을 내기 위해서는 두 데이터가 공유하는 중요한 성질에 근거하여 예측이 이루어져야 할 것입니다.[Figure 1 참조]

[Figure 1]. 모델이 source와 target에 대해 모두 좋은 예측 성능을 내기 위해서는 Source와 Target간의 차이점이 아닌, 공유하는 ‘숫자’라는 본질에 집중해야 합니다.
딥러닝은 latent space 상에서 데이터의 유의미한 저차원 representation을 효과적으로 추출해 내는 것으로 알려져 있습니다. Original space 상에서 ${\boldsymbol{x}_ i^S}_ {i=1}^{N_ s}$와 ${\boldsymbol{x}_ i^T}_ {i=1}^{N_ t}$간의 discrepancy가 존재하더라도 딥러닝이 제공하는 latent space 상에서 ${\boldsymbol{x}_ i^S}_ {i=1}^{N_ s}$와 ${\boldsymbol{x}_ i^T}_ {i=1}^{N_ t}$간의 discrepancy를 줄일 수 있을 것입니다. 만약 원래는 서로 달랐던 두 데이터 분포가 latent space 상에서 겹쳐진다면, latent space 상에서 하나의 label predictor $g_ \beta$(=linear layer)를 이용하여 두 데이터 셋에 대해 모두 좋은 예측을 수행할 수 있을 것입니다.

[Figure 2]. Deep UDA에서의 일반적인 접근
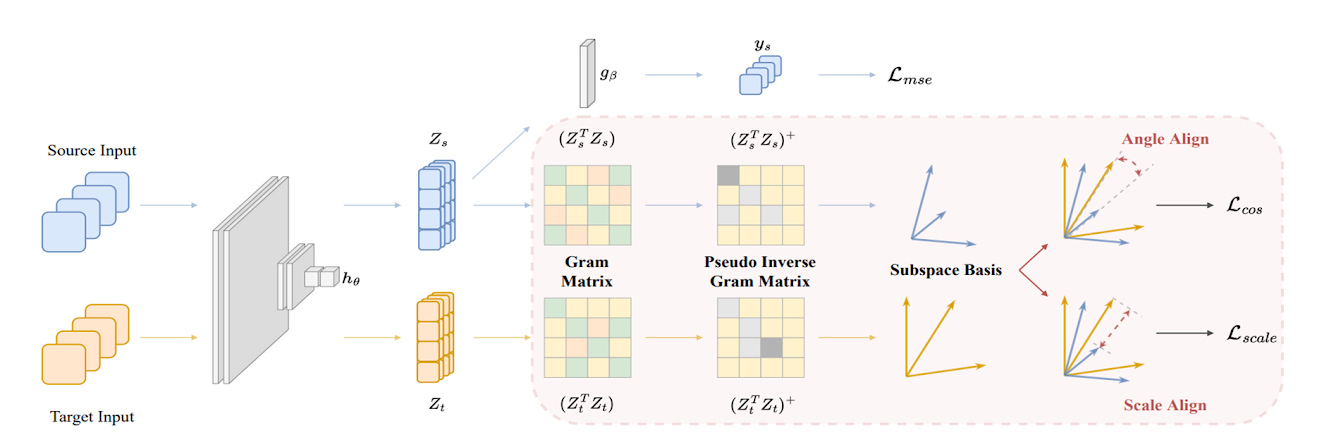
딥러닝을 활용한 Domain Adaptationd의 일반적인 접근에서는, input 데이터 $\boldsymbol x$가 주어졌을 때, deep representation인 $\boldsymbol z=h_ \theta(\boldsymbol x)$ 를 학습하기 위해, feature encoder $h_ \theta$가 사용됩니다. latent space의 representation $\boldsymbol z$는 Linear layer $g_ \beta$를 거쳐 최종 prediction $\boldsymbol y$가 됩니다. 이를 수식으로 표현하면 아래와 같습니다.
$\tilde{\boldsymbol y} = F(\boldsymbol x) = g_ {\beta}(h_ {\theta}(\boldsymbol x)) = g_ {\beta}(\boldsymbol z)$
아래와 같이 latent feature matrix $\boldsymbol Z$를 정의하겠습니다.
$p:=$ latent space representation $(z=h_ \theta(x)\in\mathbb{R}^{p})$
$b:=$ batch size
$\boldsymbol Z:=$ latent feature matrix $(\boldsymbol Z=[\boldsymbol z^1,…,\boldsymbol z^b]^T\in\mathbb{R}^{b\times p})$
앞서 ‘원래는 서로 달랐던 두 데이터 분포가 latent space 상에서 겹쳐지게 한다’라고 설명했습니다. 실제로 많은 DA 접근에서 source features $\boldsymbol Z_ s$와 target features $\boldsymbol Z_ t$의 분포 차이를 최소화 하는 것을 목표로 합니다. 그렇게 latent features가 정렬된다면, target domain에 대해 좋은 성능을 낼 것이라고 가정하곤 했습니다. 그러나 source features와 target features이 latent 상에서 유사하더라도 각각 linear layer $g_ \beta$를 통과한 후에는 둘 간의 유사성을 장담할 수 없습니다. 이는 regression problem에서 특히 주의해야 합니다. 이제 그 이유에 대해 말씀드리겠습니다.
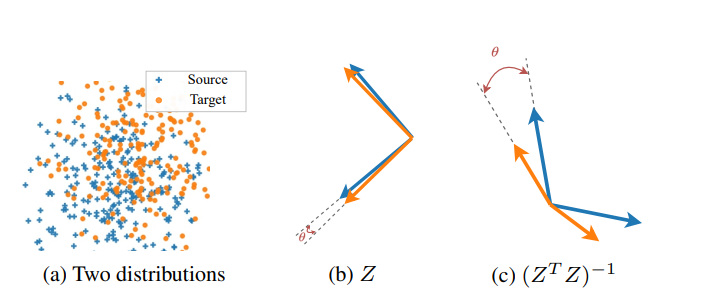

[Figure 3] OLS solution에서 inverse gram 연산의 영향
선형회귀를 생각해보면, 단순한 선형회귀는 별도의 최적화 과정(e.g, gradient descent)없이 명시적인 최적해를 구할 수 있습니다. 이를 최소제곱해(Ordinary least square solution)이라고 하죠. [Figure 2]의 말단에 있는 Linear layer $g_ \beta$역시 마찬가지일 것입니다. Latent feature $\boldsymbol Z$가 linear layer $g_ \beta$를 거쳐 $\boldsymbol Y$가 됩니다. 즉, $\boldsymbol Y=\boldsymbol Z\beta$라고 표현할 수 있습니다. parameter $\beta$는 다음과 같은 ordinary least-squared(OLS) solution을 갖습니다.
$\hat{\beta}= (\boldsymbol Z^T\boldsymbol Z)^{-1}\boldsymbol Z^T\boldsymbol Y$
여기서 $(\boldsymbol Z^T\boldsymbol Z)^{-1}\in \mathbb{R}^{p\times p}$는 inverse of Gram Matrix입니다. 일반적으로 어떤 행렬을 제곱한 것의 역행렬을 Gram Matrix라고 일컫습니다. 본 논문의 제목을 보시면 ‘Aligning gram matrix’라는 표현을 확인하실 수 있습니다. 예상하실 수 있듯, 본 논문의 핵심은 단순하게 latent space의 feature $\boldsymbol Z$를 정렬하는 것이 아니라 latent feature $\boldsymbol Z$의 inverse gram matrix인 $(\boldsymbol Z^T\boldsymbol Z)^{-1}$를 정렬할 것입니다. 그 근거가 무엇인지 이제 설명드리겠습니다.
서로 다른 도메인(source and target)의 두 가지 dataset $\boldsymbol X_ s ^{‘}, \boldsymbol X_ t^{‘}$가 있다고 가정하겠습니다. (’을 붙인 이유는 일반적인 notation인 $\boldsymbol X$와 specific한 dataset $\boldsymbol X^{‘}$를 구별하기 위함입니다.) DA가 잘 이루어 졌다면, 두 개의 데이터에 대한 예측은 최종적으로 같거나 유사해야 합니다. $\boldsymbol Z_ s^{‘}=h_\theta(\boldsymbol X_ s^{‘}), \boldsymbol Z_ t^{‘}=h_ \theta(\boldsymbol X_ t^{‘})$변환을 거치고 latent vector $\boldsymbol Z^{‘}$에 대해 linear regression이 수행되므로(linear layer $g_ \beta$), $\boldsymbol Y^{‘}=\boldsymbol Z^{‘}\hat{\beta}=\boldsymbol Z^{‘}(\boldsymbol Z^{‘T}\boldsymbol Z^{‘})^{-1}\boldsymbol Z^{‘T}\boldsymbol Y^{‘}$값이 source와 target에 대해 같거나 유사해야 합니다. 즉, DA의 목표인 source와 target이 모두 유사하게 좋은 성능을 내기 위해서는, $\hat{\beta}_ s$와 $\hat{\beta}_ t$사이의 적절한 optimal $\hat{\beta}_ *$를 linear layer의 parameter로 삼아야 합니다. $\hat{\beta}_ *$는 $\hat{\beta}_ s$와 $\hat{\beta}_ t$사이의 값이므로, $\hat{\beta}_ s$와 $\hat{\beta}_ t$의 차이가 크다면, 안정적으로 shared linear layer의 optimal parameter $\hat{\beta}_ *$을 찾을 수 없게 됩니다. 즉, 우리의 목표를 위해서는 각 도메인에 대한 $\hat{\beta}$이 유사해야 하고, 이를 위해서는 $(\boldsymbol Z^T \boldsymbol Z)^{-1}$가 비슷해야 합니다.
[Figure 3]의 (a)에서 서로 약간 다른 gaussian distribution을 따르는 Source domain data $\boldsymbol x_ s$ 와 Target domain data $\boldsymbol x_ t$ 의 데이터 분포를 확인할 수 있습니다. (b) $\boldsymbol x_ s$와 $\boldsymbol x_ t$는 feature encoder $h_ {\theta}$를 통해 latent space로 mapping 됩니다($\boldsymbol z_ i = h_ {\theta}(\boldsymbol x_ i)\;where\;i=s,t$).
$\boldsymbol x_ s$ 들은 feature encoder를 통해 $\boldsymbol Z_ s$로 변환되고, $\boldsymbol x_ t$ 들은 feature encoder를 통해 $\boldsymbol Z_ t$로 변환되었습니다.
(b)를 보시면, $\boldsymbol Z_ s$와 $\boldsymbol Z_ t$가 latent space 상에서 잘 정렬되어 있습니다. $\boldsymbol Z_ s$의 기저벡터와 $\boldsymbol Z_ t$의 기저벡터가 잘 정렬되어있기 때문이죠.
(c)하지만 잘 정렬되어 있었던 $\boldsymbol Z_ s$와 $\boldsymbol Z_ t$는, inverse gram 연산을 거친 후에는 더이상 정렬되어 있지 않을 수 있습니다. Linear layer의 OLS solution에는 inverse gram 연산 항이 포함되어 있는데, 그렇다면 분명히 어떤 문제가 발생할 수 있겠네요. <Figure 3>가 말하고자 하는 바는 OLS solution과 관련이 있는 linear layer를 마지막에 사용하는 regression problem에서는 기존의 DA 방법들처럼 $\boldsymbol Z$를 정렬하는 것으로는 부족하며, 오히려 $(\boldsymbol Z^T \boldsymbol Z)^{-1}$를 latent space 상에서 정렬해야 한다는 것입니다.
Method에서는 우리가 집중해야 할 두 가지에 대해 알아보겠습니다.
-
Angle Alignment of $(\boldsymbol Z^T \boldsymbol Z)^{-1}$
-
Scale Alignment of $\boldsymbol Z$
3. Method
우리에게 정렬의 대상은 $\boldsymbol Z^T \boldsymbol Z$이 아닌 $(\boldsymbol Z^T \boldsymbol Z)^{-1}$입니다. 학습 중에 batch size $b$는 embedding dimension $p$보다 일반적으로 작습니다$(\boldsymbol Z\in \mathbb{R}^{b\times p}, with\; b<p)$.
따라서 Gram matrix $(\boldsymbol Z^T \boldsymbol Z\in \mathbb{R}^{p\times p})$의 rank $r$은 $b$보다 작거나 같게 됩니다. 즉, fully ranked 되지 않고 따라서 invertible 하지 않습니다. Gram matrix $\boldsymbol Z^T \boldsymbol Z$가 invertible하지 않다면, $(\boldsymbol Z^T \boldsymbol Z)^{-1}$를 계산하는 데에 문제가 생기게 됩니다. 이에, Moore-Penrose pseudo-inverse를 사용합니다.
3.1 Angle Alignment
Angle Alignment 방법에 대해 먼저 설명하겠습니다.
Feature matrix $\boldsymbol Z$의 SVD 형식을 $\boldsymbol Z = UDV^T$라고 하겠습니다. 따라서, Gram matrix $\boldsymbol Z^T \boldsymbol Z$는 $\boldsymbol Z$의 SVD를 이용해 다음과 같이 분해 될 수 있습니다.
$(\mathbf{Z}^T\mathbf{Z}) = (UDV^T)^T(UDV^T) = V\Lambda V^T,$
$\lambda_ k := \Lambda_ {k,k} = D_ {k,k}^2 \quad \text{for } k = 1, \ldots, p.$
$\boldsymbol Z^T \boldsymbol Z$의 eigenvalues를 다음과 같이 나열할 수 있습니다.
$\lambda_ 1 \geq \ldots \geq \lambda_ k \geq \ldots \geq \lambda_ p \geq 0$
Moore-Penrose pseudo-inverse는 $\lambda_ k$보다 작은 singular values를 0으로 대체하여 유도할 수 있습니다. ($k$는 하이퍼파라미터)
$(\mathbf{Z}^T\mathbf{Z})$의 pseudo-inverse는 다음과 같이 표현될 수 있습니다.

위 연산은 역행렬의 가장 큰 singular value에 해당하는 차원을 제거하는 것과 동일합니다. 해당 연산의 근거를 제공하는 연구가 존재하는데, [Xinyang Chen et al. 2019]에 의하면 DA에서 큰 고윳값(우리의 경우에는 $\boldsymbol Z^T \boldsymbol Z$의 작은 고윳값을 제거하여 $(\mathbf{Z}^T\mathbf{Z})^{-1}$의 큰 고윳값을 제거함)을 제거하는 것이 성능 개선에 도움을 준다고 합니다. $k$개의 principal component로 구성된 source와 target의 Gram Matrix를 $G_ s^+ = (\mathbf{Z}_ s^T\mathbf{Z}_ s)^+$와 $G_ t^+ = (\mathbf{Z}_ t^T\mathbf{Z}_ t)^+$라고 하겠습니다.
지금까지의 흐름을 간단히 정리하겠습니다.
이번 섹션 3.1의 목표는 inverse gram matrix $(\boldsymbol Z^T \boldsymbol Z)^{-1}$의 angle alignment입니다. 하지만 $\boldsymbol Z^T \boldsymbol Z$가 non-invertible한 경우가 많기에, 우리는 pseudo-inverse gram matrix인 $G_ s^+ = (\mathbf{Z}_ s^T\mathbf{Z}_ s)^+$와 $G_ t^+ = (\mathbf{Z}_ t^T\mathbf{Z}_ t)^+$를 구했습니다.
이제 $G_ s^+$와 $G_ t^+$ 의 angle alignment만이 남았는데, 이는 $G_ s^+$와 $G_ t^+$ 의 column vectors간의 cosine similarity를 최대화 하여 수행할 수 있습니다. columns 간의 consine similarity는 다음과 같이 표현할 수 있습니다.
$\cos(\theta^{S \leftrightarrow T}_ i) = \frac{G^+_ {s,i} \cdot G^+_ {t,i}}{|G^+_ {s,i}| |G^+_ {t,i}|}\quad where\; i\in [1,p],\; and\; G_ i^+:ith\;column\;of\;the\;G_ i^+$
$M = [\cos(\theta_ 1^{S \leftrightarrow T}), \ldots, \cos(\theta_ p^{S \leftrightarrow T})]$일때, pseudo-inverse of Gram matrix의 선택된 $k$개의 basis를 정렬하기 위한 loss는 다음과 같습니다.

이 손실함수를 최소화하면, source domain과 target domain이 latent space 상에서 비슷한 방향의 기저벡터를 가지게 될 것이고, 이는 우리가 원하는 $(\boldsymbol Z^T \boldsymbol Z)^{-1}$ 의 angle alignment를 이루게 해줄 것입니다.
3.2 Scale Alignment
[Xinyang Chen et al.2021]에 의하면, UDA Regression에서는 Source domain의 feature scale를 유지하는 것이 매우 중요하다고 합니다. 3.1에서는 $(\boldsymbol Z^T \boldsymbol Z)^{-1}$의 angle alignment에 대해 알아보았는데, 이번 절에서는 feature matrix인 $\boldsymbol Z$의 scale alignment에 대해 알아보겠습니다.
우리는 target feature의 scale을 source feature의 scale에 맞출 것입니다. matrix의 scale을 측정하는 한가지 방법에 대해 다음과 같이 제시하겠습니다.
$|\boldsymbol Z|_ 1 = \text{Tr}\left(\sqrt{\boldsymbol Z^T\boldsymbol Z}\right) = \sum_ {i=1}^{N} \sqrt{\lambda_ i}$
즉, feature matrix $\boldsymbol Z$의 scale은 $\boldsymbol Z^T \boldsymbol Z$의 eigenvalue 제곱근의 합으로 정의됩니다.
Scale alignment를 위한 손실함수는 다음과 같습니다.

손실함수가 위와 같이 정의되는 이유는 무엇일까요?
우리는 $|\boldsymbol Z_ s|_ 1$와$|\boldsymbol Z_ t|_ 1$를 비슷하게 하여 feature matrix의 scale를 맞춰주는 것만을 원하는 것이 아닙니다. 우리는 source와 target에서 크기순으로 $k$개의 eigenvalues를 정렬하여 인덱싱하였는데요, source의 $i$th eigenvalue는 target의 $i$th eigenvalue와 비슷해져야 source와 target의 $i$th basis의 영향력이 비슷해지기 때문입니다. 이 두가지 목표를 모두 달성하기 위해선 위와 같은 손실함수의 설계가 필요합니다.
3.3 Overview
학습에 있어서 고려해야 할 두 가지 요소를 알아보았습니다.
-
Angle alignment of $(\boldsymbol Z^T \boldsymbol Z)^{-1}$
-
Scale alignment of $\boldsymbol Z$
여기서 끝나면 안됩니다. 왜냐면, 기본적으로 source domain에 대한 충분한 성능이 보장되어야 하기 때문이죠. 1과 2는 source와 target domain에 대해 각각 비슷한 성능을 내는 모델을 만드는데 기여합니다. source domain에 대한 성능이 보장되지 않으면, 1과 2에 대해 비슷하게 안좋은 모델이 학습될 위험이 있습니다. 따라서 다음 요소 역시 고려되어야 합니다.
- Supervised Loss of source domain
따라서 우리의 종합 손실함수는 다음과 같습니다.
$\mathcal{L}_ {\text{total}}(\mathbf{Z}_ s, \mathbf{Z}_ t) = \mathcal{L}_ {\text{src}} + \alpha_ {\text{cos}} \mathcal{L}_ {\text{cos}}(\mathbf{Z}_ s, \mathbf{Z}_ t) + \gamma_ {\text{scale}} \mathcal{L}_ {\text{scale}}(\mathbf{Z}_ s, \mathbf{Z}_ t)$
$where\; \alpha_ {cos},\gamma_ {scale}\;are\;hyperparameters$
4. Experiment
본 연구에서는 3가지 데이터셋(dSprites, MPI3D, Biwi Kinect)에 대해 실험을 진행하였고, 3가지의 실험에 대해 모두 대조군보다 우월한 성능을 보였습니다. 실험 세팅이 크게 다른 것 없이 유사하므로 dSprites 데이터셋에 대한 실험만 소개하겠습니다.
Experiment setup
- Dataset : dSprites

dSprites 데이터셋을 사용한 regression problem은, 주어진 이미지에 대해 이미지 속 도형의 크기(Scale), x좌표(position X) y좌표(position Y) 총 3가지를 맞춰야 합니다.
3개의 domain(color,noisy,scream)이 있고, source와 target domain으로 6가지의 조합이 가능합니다.
C: color domain, N: noisy domain, S: scream domain
$(C\to N, C\to S, N\to S, N\to C, S\to C, S\to N)$
예를 들어 $C\to N$의 경우에 Unsupervised domain adaptation regression이 던지는 질문은
“$C$도메인의 labeled dataset과 $N$도메인의 unlabeled dataset을 가지고 있을때, 이것을 이용해서 $N$도메인의 regression problem을 잘 풀어낼 수 있는가?” 입니다.
- baseline
A pre-trained ResNet-18을 baseline으로 사용하였습니다.
- Evaluation Metric
MAE를 사용하였고, 각 실험을 3번씩 반복하여 평균값을 최종 실험 결과로 취하였습니다.
Result

본 논문의 DARE-GRAM은 여타 domain adaptation 비교군들과 비교하여 동일한 실험 하에서 더 나은 성능을 보였습니다.
위 실험 결과에 대해 간단히 설명드리겠습니다.
Resnet-18은 source domain에 대해 훈련시킨 baseline model이므로, 이 모델에 별다른 조치를 하지 않고 target domain에 대한 예측을 잘 해낼 수 없을 것입니다. 표 1행에 Resnet-18의 MAE가 다른 방법들의 MAE를 훌쩍 상회하는 것을 보실 수 있는데, 이는 위와 같은 이유 때문입니다.
Unsupervised domain adaptation(UDA) 연구는 classication 분야에서 많이 이루어졌습니다. TCA(2행)부터 DANN(7행)은 classification을 목표로 한 UDA 방법입니다. 따라서 큰 성능의 개선이 이루어지지 않는 것을 확인할 수 있습니다.
비약적인 성능의 발전은 RSD(8행)로부터 시작됩니다. RSD는 regression 문제를 겨냥한 많지 않은 UDA 연구중 하나이고, 본 논문 DARE-GRAM이 발표되기 전까지 위 데이터셋에 대해 state of the art를 달성한 방법입니다.
RSD와 DARE-GRAM의 가장 큰 차이점은 inverse gram matrix의 정렬 여부입니다. 마지막 layer에 linear layer가 사용됨에 따라 OLS solution의 inverse gram matrix의 성질을 고려해야 한다는 DARE-GRAM의 문제제기는 합리적임을 실험적으로 완벽히 보이고 있습니다.
5. Conclusion
우리는 labeled source domain과 unlabeled target domain 모두에서 좋은 성능을 내는 모델을 학습하기 위한 Unsupervisd Domain Adaptation Regression 방법인 DARE-GRAM에 대해 알아보았습니다.
학습에 있어서 우리가 고려한 것은 다음의 세 가지 입니다.
-
MAE on source samples
-
Angle alignment for Inverse Gram Matrix $(\boldsymbol Z^T \boldsymbol Z)^{-1}$
-
Scale alignment for feature Matrix $\boldsymbol Z$
아래는 본 네트워크의 전체적인 구조를 보여주는 그림입니다.

Author Information
-
Author name : 최승준(choi seung jun)
-
Affiliation : KAIST ISYSE istat lab
-
contact : seungjun(at)kaist.ac.kr
-
Research Topic : Causality, Generalization
6. Reference & Additional materials
Please write the reference. If paper provides the public code or other materials, refer them.
-
Reference
-
Xinyang Chen, Sinan Wang, Mingsheng Long, and Jianmin Wang. Transferability vs. discriminability: Batch spectral penalization for adversarial domain adaptation. In International conference on machine learning, pages 1081–1090. PMLR, 2019
-
Xinyang Chen, Sinan Wang, Jianmin Wang, and Mingsheng Long. Representation subspace distance for domain adaptation regression. In International Conference on Machine Learning, pages 1749–1759. PMLR, 2021.