[AAAI 2023] Contrastive Learning Reduces Hallucination in Conversations
1. Problem Definition
현재 BART, GPT와 같은 언어 모델은 질문과 관련이 없거나 사실이 아닌 문장을 마치 사실인 것처럼 그럴듯하게 생성하는 Hallucination 문제를 가지고 있습니다. Hallucination의 원인은 다양하지만, 주로 학습 데이터의 오류 혹은 언어 모델 학습 구조에서 비롯됩니다. 본 논문에서는 ChatGPT와 같은 대화형 언어모델의 Hallucination을 다룹니다. 대화형 언어모델의 Hallucination 문제를 완화하기 위해 MixCL 이라는 새로운 Contrastive Learning framework를 제안합니다.
2. Motivation
Pilot Experiment
아래 Figure 1은 Dialogue 데이터셋으로 학습한 언어 모델 BART가 생성한 답변을 Human annotation 하여 Hallucination의 비율을 분석 결과입니다.
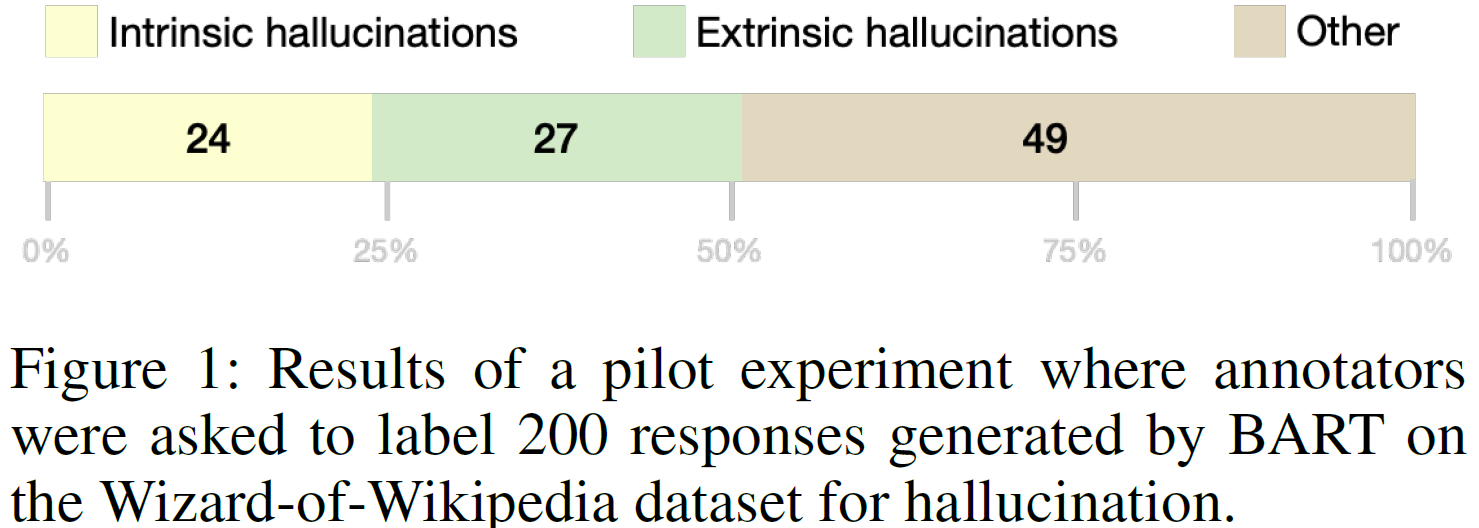
BART의 200개 답변 중에서 Intrinsic hallucination(입력과 비교했을때 factual 하지 않은 답변) 24% 및 Extrinsic hallucination(입력과 관련이 없는 대답) 27% 를 포함하여 최소 51% 의 Hallucination을 포함하는 것을 확인할 수 있습니다.
아래 그림은 대화형 task에서 BART의 Hallucination이 포함된 답변을 나타낸 예시입니다.

Topic이 정해져 있을 때, Apprentice 뒤에 알맞은 답변을 생성해야 하는데, 오류가 없는 ground truth response에 비해 BART의 답변에는 Intrinsic hallucination이 포함된 것을 확인 할 수 있습니다.
이처럼, 기존의 대화형 언어 모델에는 Hallucination이 빈번하게 발생한다는 것을 알 수 있습니다. Figure 2 에서 확인할 수 있듯이, Hallucination은 Span-Level(적은 수의 연속된 단어 집합: 단어 보다는 크고 문장보다는 작은 단위) 에서 빈번하게 발생됩니다. 하지만 기존의 연구에서는 주로 Word-Level 혹은 Sentence-Level에서 임베딩을 진행하여 언어 모델을 학습하였습니다. 따라서 본 논문에서는 Contrastive Learning을 사용한 Span-Level임베딩에 특화된 언어 모델 학습 방법을 소개합니다.
Existing Works
Types of Dialogue Agent
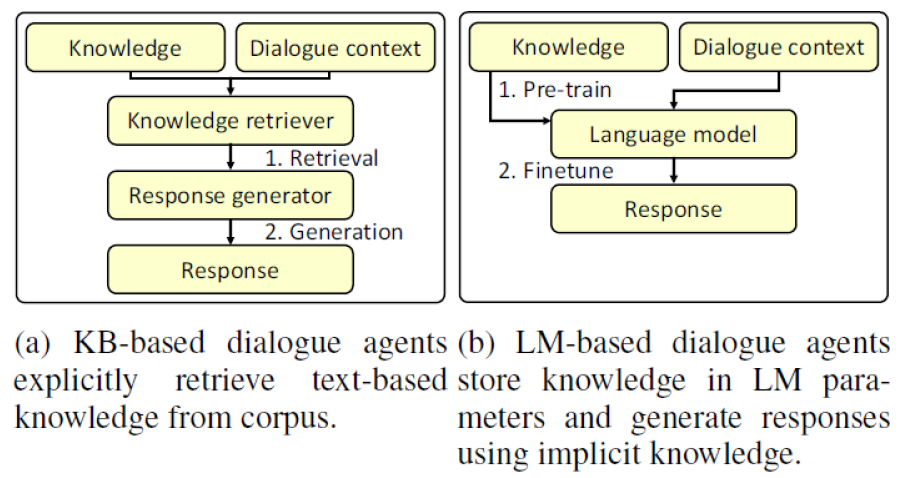
Dialogue Agent는 지식(Knowledge)과 대화 지문(Dialogue context)을 입력 받아서 대화 지문 다음에 올 적절한 답변을 출력하는 모델입니다. Dialogue Agent의 종류는 KB(Knowledge Base)-based model과 LM(Language Model)-based model로 나눌 수 있습니다. 위 그림은 두 Dialogue Agent 모델의 구조를 나타내고 있습니다. 각각의 특징은 다음과 같습니다.
- KB-based model은 지식을 검색하는 IR(Information Retrieval) 모듈을 통해서 입력된 Dialogue와 관련있는 적절한 정보를 추출합니다. 추출된 정보를 바탕으로 Response Generator를 통해 최종 답변을 생성합니다.
- 장점: 정보를 명시적으로 추출하기 때문에 Hallucination 문제가 거의 없습니다.
- 단점: Retreiever 와 Generator 가 서로 분리되어 있기 때문에 답변 생성 속도가 느립니다.
- LM-based model은 pre-training을 통해 모델의 파라미터에 지식을 저장하고 fine-tuning을 통해서 대화 지문에서의 답변 생성을 학습합니다.
- 장점: 모델의 파라미터에 학습된 지식과 답변 생성과 관련된 정보가 함께 포함되어 있어서 답변 생성 속도가 빠릅니다.
- 단점: 정보가 파라미터에 함축적으로 저장되어 있기 때문에 Hallucination 문제가 발생합니다.
본 연구에서는 Dialogue Agent에서 LM-based model의 Hallucination을 완화하는 것에 초점을 맞춥니다.
Text Contrastive Learning
Contrastive Learning(대조 학습)의 목표는 비슷한 데이터끼리는 가까이 임베딩 하고 성질이 다른 데이터끼리는 멀리 임베딩 하는것입니다. 아래 그림은 Text data에서 Contrastive Learning 이 진행되는 방식을 나타냅니다.
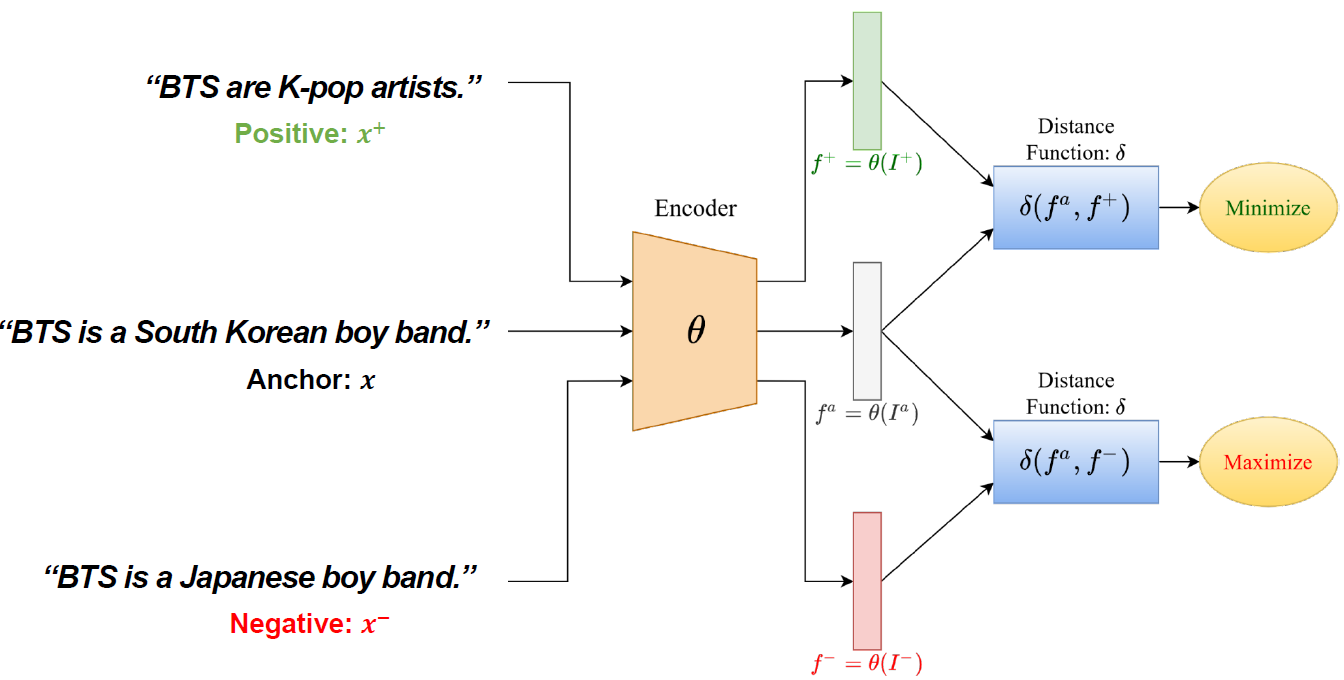
먼저, 가운데 “BTS is a South Korean boy band” 라는 문장을 Anchor 데이터 라고 가정해 보겠습니다. 이때 Anchor 데이터는 기준이 되는 데이터 입니다. 또한 Anchor 비슷한 특성을 가진 데이터를 초록색으로 표시된 것과 같이 Positive sample 이라고 합니다. 예를 들어 위와 같이 “BTS are K-pop artists” 라는 문장은 Anchor 와 의미가 같으므로 Positive sample 입니다. 반대로 Anchor 특성이 다른 데이터를 Negative sample 이라고 합니다. “BTS is a Japanese boy band” 라는 문장은 Anchor 와 의미가 다르므로 Negative sample 입니다. 이들을 전부 같은 encoder에 통과시켜 데이터를 word 혹은 sentence 단위로 임베딩($h=f_\theta(x)$) 하고 나서, 앵커 데이터와 positive sample은 embedding space에서 거리($\delta(h,h^+$))를 가깝게 하고, 앵커 데이터와 negative sample은 거리($\delta(h,h-)$)를 멀게 하도록 loss function을 설정합니다.
기존의 Contrastive loss function은 다음과 같습니다.
$\begin{align} \mathcal{L}_ {\mathrm{contrastive}} = -\log \frac{e^{\operatorname{sim}\left(\mathbf{h}_ {i}, \mathbf{h}_ {i}^{+}\right) / \tau}}{\sum_ {j=1}^N\left(e^{\operatorname{sim}\left(\mathbf{h}_ {i}, \mathbf{h}_ {j}^{+}\right) / \tau}+e^{\operatorname{sim}\left(\mathbf{h}_ {i}, \mathbf{h}_ {j}^{-}\right) / \tau}\right)} \end{align}$
$\mathbf{h}_ {i}$,$\mathbf{h}_ {i}^{+}$, $\mathbf{h}_ {i}^{-}$ 는 각각 anchor, positive, negative의 임베딩 벡터입니다. 이렇게 세팅을 하고 학습을 시키면 인코더의 파라미터 $\theta$는 positive와 negative의 특성을 파악하여 구분할 수 있게 업데이트가 됩니다. 본 논문에서는 Contrastive Learing을 사용하여 효율적으로 Span-Level로 임베딩하는 전략에 대해 탐구합니다.
3. Method
Preliminaries
일반적으로 언어 모델 학습에서 필요한 두 가지 과정을 살펴보겠습니다. 먼저, $x, y, k$를 각각 대화 문장(dialogue context), 대화 응답(corresponding response), 외부 지식(ground-truth knowledge) 이라고 하겠습니다.
Pre-training on Knowledge Corpus
본 논문에서는 언어 모델로 BART-Large를 사용하였고, 원래 데이터에 일부러 노이즈를 추가한 후, denoising self-supervised learning을 통해 Pre-training 합니다.
$\begin{align} \mathcal{L}_ {\mathrm{LM}}=-\mathbb{E}_ {k \sim \mathcal{K}} \log p_ {\theta}(k \vert \hat{k}) \end{align}$
여기서 $\mathcal{K}$ 는 위키피디아와 같은 외부 지식의 집합이고 $\hat{k}$는 원래 지식 $k$ 에서 masking이나 deletion을 통해 노이즈가 추가된 text 입니다. 즉, 노이즈 데이터 $\hat{k}$을 통해 정상적인 데이터 $k$를 output 하는 가능도를 최대화하는 방향으로 모델이 학습되게 됩니다. 따라서 denoising self-supervised learning 이란 노이즈를 제거하며 원본 데이터를 복원하는 과정입니다. 이는 언어 모델의 파라미터에 올바른 지식 정보를 저장하여 Hallucination이 없는 답변을 생성하기 위함입니다.
Fine-tuning on Dialogue Dataset
다음은 Dialogue Dataset을 Fine-tuning 하는 과정입니다.
$\begin{align} \mathcal{L}_ {\mathrm{MLE}}=-\log p_ {\theta}(y \vert x)=- \sum_ {t=1}^{|y|} \log p_ {\theta} \left(y_ {t} \vert y_ {<t}, x\right) \end{align}$
일반적으로 sequence to sequence를 바탕으로 한 언어 모델에서 teacher forcing이 사용되는데, 이때 Maximum Likelihood Estimation을 통해 학습합니다. 수식의 우변은 $x$와 이전 ground truth 답변 토큰 $y_{<t}$ 를 입력하여 다음 ground truth 답변 토큰 $y_t$를 추정하는 teacher forcing 과정을 나타냅니다. 이는 언어 모델의 디코더가 다음 스텝에서 올바른 토큰을 출력하도록 학습하는 방식으로, fine-tuning 하려는 dialogue dataset의 특징을 올바르게 학습할 수 있습니다. 최종적으로 언어 모델의 파라미터는 dialogue response task에 적합하게 미세조정 됩니다. 본 논문에서는 이렇게 언어 모델을 미세조정 하는 과정에서 Hallucination 문제가 자주 발생한다고 강조합니다.
Positive/Negative Sampling
Contrastive Learning 에서는 Positive sample 및 Negative sample을 생성하는 전략도 중요합니다. 두 데이터의 퀄리티는 모델의 성능에 큰 영향을 미치기 때문입니다.
본 논문에서는 Positive sample은 다른 연구와 비슷하게 human labeling 혹은 heuristic 한 방법을 사용했다고 합니다.
Negative sample은 TF-IDF retriever 를 사용하여 주어진 dialogue context $x$에 대해 관련이 없는 정보를 knowledge base $\mathcal{K}$로 부터 추출합니다. 또한 앞서 살펴본 pre-trained & fine-tuned 언어 모델 $p_\theta$를 사용하여 추출합니다.
MixCL: Mixed Contrastive Learning
다음으로 Figure 3은 본 논문에서 소개하는 MixCL 모델의 전체적인 구조입니다.
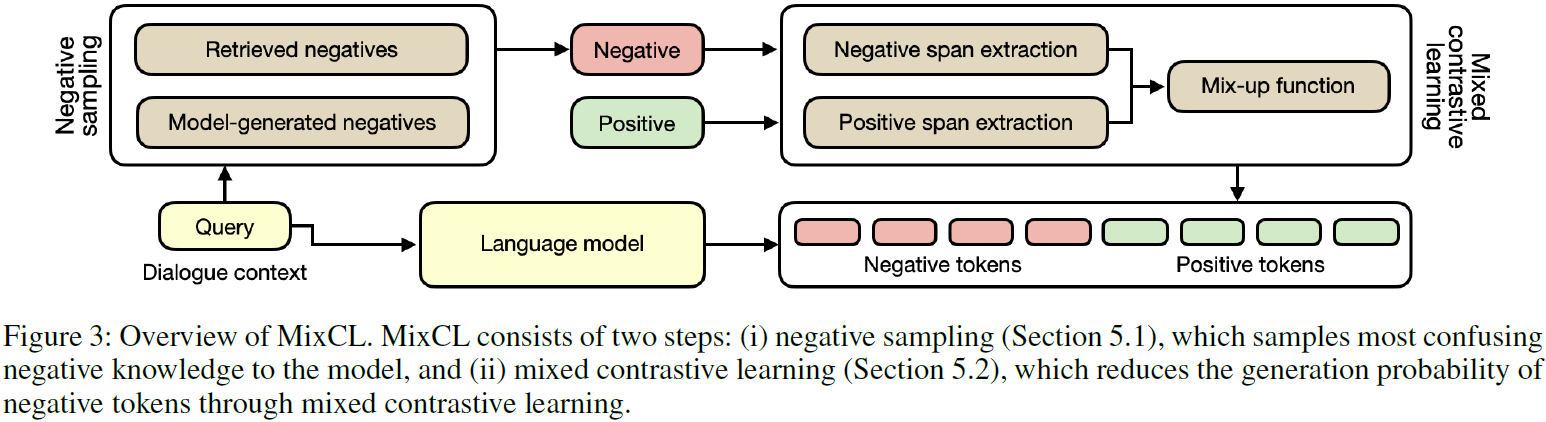
본 논문에서는 먼저 Dialogue context query로 부터 human labeling 혹은 huristic한 방법을 통해 positive sample을 만들었습니다. 또한 retriever 및 사전 학습된 모델을 사용하는 전략을 통해 negative sample을 만들었습니다. 그리고 이러한 정보를 원래 query와 함께 사용하여 최종적으로 언어 모델의 output 중에서 negative sample의 비중을 줄이는 것이 목표입니다. Figure 3에서 Mixed Contrastive Learning 부분은 앞서 생성한 Positive/Negative sample을 Span-Level에서 접근하여 token embedding을 하려고 합니다.
Extracting Spans
Intrinsic hallucination은 주로 Entity(사람 이름 혹은 장소 이름, 숫자 등)에서 발생합니다. 따라서 문장에서 알맞은 Entity를 추출하는 것이 중요합니다. 이를 위해 본 논문에서는 Named Entity Recognition (NER) 방법을 사용했습니다.
Extrinsic hallucination은 주로 글에서 관련 없는 문장에서 발생합니다. 따라서 이러한 특성은 문장의 전체적인 구조를 파악하는 것이 중요하기 때문에 Constituency Parsing (CP) 방법을 사용했습니다.
Mix-up Function
Positive sample을 $z^+$, Negative sample을 $z^-$ 라고 하겠습니다. Span-Level 분석을 위해서 새로운 데이터 $\tilde{z} = Mix(z^+,z^-)$ 를 새로 정의합니다. 여기서 $Mix()$ 함수는 $z^+$에 있는 Span을 랜덤하게 선택하여 $z^-$의 Span과 서로 위치를 바꾸는 역활을 합니다. 또한 $\tilde{z}$에 대응되는 binary sequence $\phi$ 를 정의합니다. 이는 $\tilde{z}$를 구성하는 토큰이 $z^+$로 부터 구성된 것이면 1로, $z^-$로 부터 구성된 것이면 0으로 바꾸어 줍니다.
예시를 통해 살펴보겠습니다.
- $z^+$: BTS is South Korean boy band.
- $z^-$: BTS is a popular Japanese musician group.
여기서, Positive Span이 South Korean 이고 Negative Span이 Japanese 이라면, $\tilde{z}$ 및 $\phi$ 는 다음과 같이 정의됩니다.
-
$\tilde{z}$: BTS is Japanese boy band.
-
$\phi$: [1, 1, 0, 1, 1]
Mixed-contrast Loss
본 논문에서는, 앞서 정의한 $\tilde{z}$ 와 $\phi$로 Mixed contrast loss function $l_{\operatorname{mix}}$을 다음과 같이 설정 합니다:
$\begin{align} l_ {\operatorname{mix}}\left(z^{+}, z^{-}\right) = -\sum_ {j=1}^{\left|\tilde{z}_ {i}\right|} [ \phi_ {i, j} \log p_ {\theta}\left(\tilde{z}_ {i, j} \vert \tilde{z}_ {i,<j}, x\right) + \left(1-\phi_ {i, j}\right) \log \left(1-p_ {\theta} \left( \tilde{z}_ {i, j} \vert \tilde{z}_ {i,<j}, x\right) \right) ] \end{align}$
이때, $\tilde{z}_ {i}=Mix(z^+,z^-_ {i})$ 이고 $\phi_ {i, j}=sign({\tilde{z}}_ {i,j})$ 입니다.
이를 모든 $z^{+}$와 $z^{-}$에 적용하면 최종 MixCL Loss는 다음과 같습니다:
$\begin{align} \mathcal{L}_ {\mathrm{MCL}} = \sum_ {z^{+} \sim \mathcal{Q}_ {\mathrm{Pos}}(x)} \sum_ {z_ {i}^{-} \sim \mathcal{Q}_ {\mathrm{Neg}}(x)}^{i=1, \ldots, M} l_ {\text {mix }}\left(x, z^{+}, z_ {i}^{-}, \theta\right) \end{align}$
이는 Span-Level에서 Contrastive Learning을 적용한 방식으로, 언어 모델이 Positive Span을 생성하는 가능도는 높이고 Negative Span을 생성하는 가능도는 낮추는 방향으로 학습하도록 작동합니다.
한 번에 이해가 어려울 수 있으니, 예시를 통해 살펴보겠습니다. 다음과 같은 Dialogue 데이터가 있다고 하겠습니다:
Topic: BTS Dialogue Context ($x$):
- User1: Do you know BTS?
- User2: Yeah, but I don’t know which country they are from.
그리고 다음과 같이 Positive Sample및 Negative Sample 이 추출되었다고 생각해보겠습니다:
-
$z^+$: BTS is a South Korean boy band.
-
$z^−_1$: BTS is a popular Japanese musician group.
-
$z^−_2$: BTS is a North American boy group band.
그러면 $\tilde{z_1}$, $\tilde{z_2}$, $\phi_1$, $\phi_2$ 은 다음과 같이 정의됩니다:
- $\tilde{z_1}$: BTS is a Japanese boy band.
-
$\phi_1$: [1, 1, 1, 0, 1, 1]
- $\tilde{z_2}$:BTS is a North American boy band.
- $\phi_2$: [1, 1, 1, 0, 0, 1, 1]
이때 MixCL loss를 적용시켜보면,

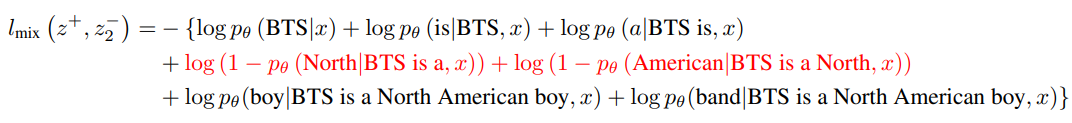
MCL Loss는 다음과 같습니다: $\begin{align} \mathcal{L}_ {\mathrm{MCL}} = l_ {\text {mix}}(z^+,z^-_ {1}) + l_ {\text {mix}}(z^+,z^-_ {2}) \end{align}$
이때 $\mathcal{L}_{\mathrm{MCL}}$이 작아지려면, Negative Span에 해당하는 “Japanese”, “North American”의 생성 가능도가 감소해야 하고 나머지 Positive Span의 생성 가능도는 커져야 하는 것을 확인할 수 있습니다.
Final Training Objective
최종적으로 Final Loss는 다음과 같이 3개의 Loss의 가중합으로 설정합니다:
$\begin{align} \mathcal{J}(\theta)=\alpha_ {1} \mathcal{L}_ {\mathrm{MLE}}+\alpha_ {2} \mathcal{L}_ {\mathrm{MCL}}+\alpha_ {3} \mathcal{L}_ {\mathrm{LM}} \end{align}$
4. Experiment
Experiment setup
Dataset
본 논문에서는 Dialogue Dataset으로 Wizard of Wikipedia (WoW) 한 개만 사용합니다. 다음 Table 1은 WoW 데이터셋의 통계량을 나타냅니다.
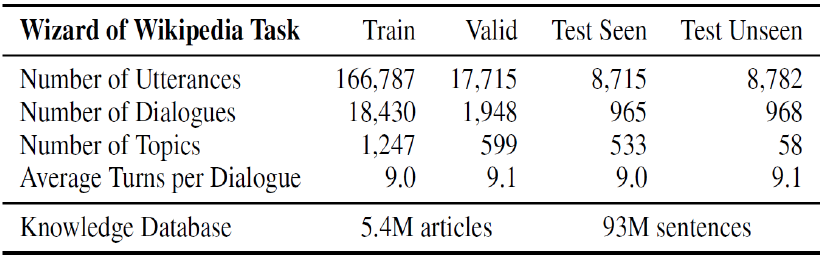
아래 그림은 WoW 데이터 예시 입니다. Topic이 있고, Wizard 와 Apprentice 가 대화를 하고 있는 Dialogue data 입니다. 이때 Wizard는 topic에 대해서 가운데 파란색으로 표시된 위키피디아에서 제공받은 knolwdge를 사용하여 답변합니다. Apprentice 는 그러한 추가 정보 없이 대화를 이어 나갑니다. 이 데이터를 학습해서 답변을 잘하는 Wizard agent 모델을 만드는 것이 목표입니다.

Baseline
- KB-based methods: TMN, DukeNet, KnowledGPT, KnowBART
- LM-based methods: GPT-2, BlenderBot, KnowExpert, MSDP
Evaluation Metric
F1, RL(ROUGE-L), B2, B4 (BLEU) MT(Meteor), KF1(Knowledge-F1), EF1(Entity-F1), and ACC( Accuracy)
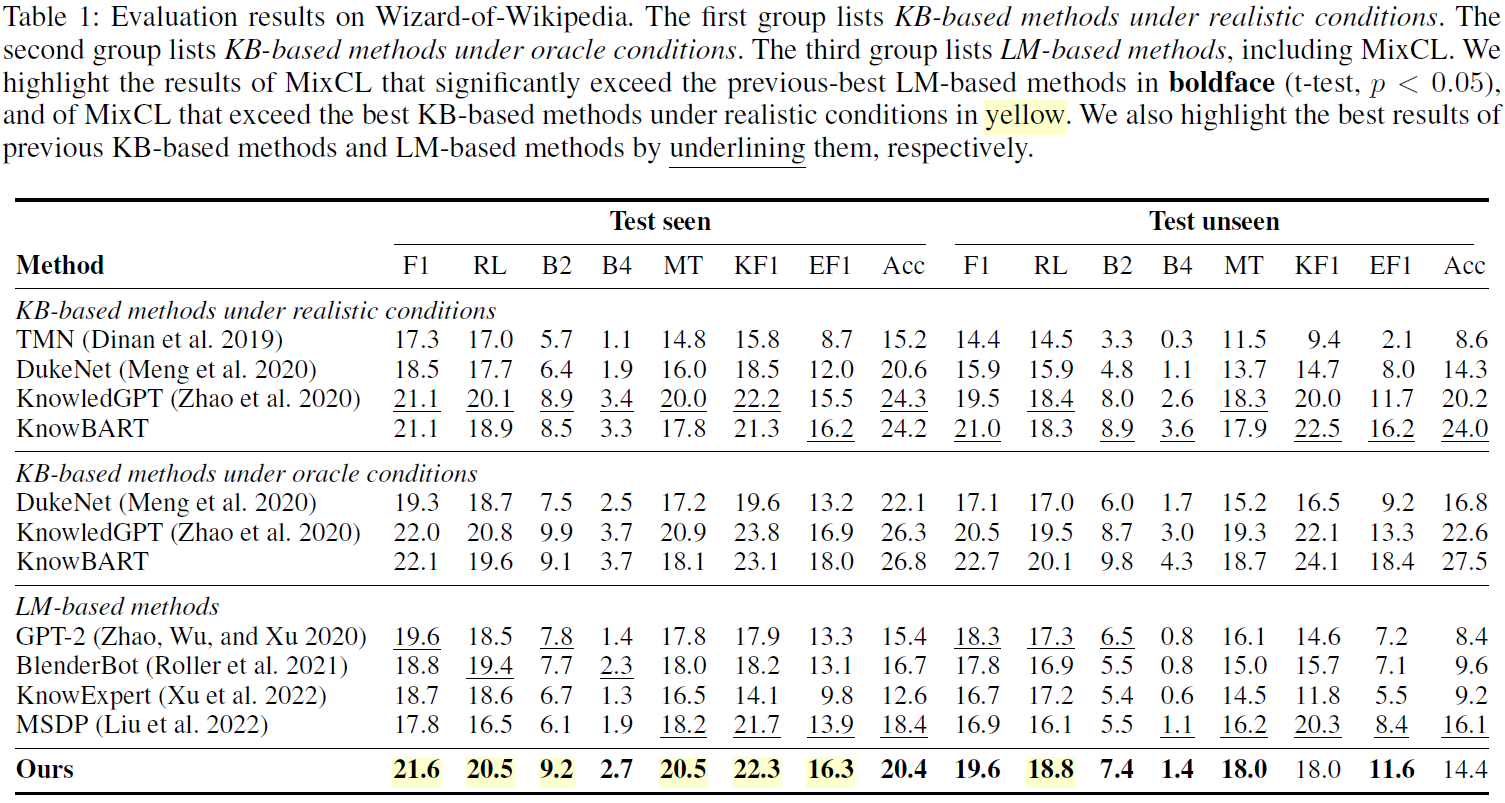
Result
아래 Table 1은 여러 가지 knowledge dialogue agent model로 WoW 데이터를 학습한 결과입니다. KB-based 모델도 있고 LM-based 모델도 있습니다. 대부분의 평가 지표에서 MixCL 모델 성능이 우수한 것을 확인할 수 있습니다.
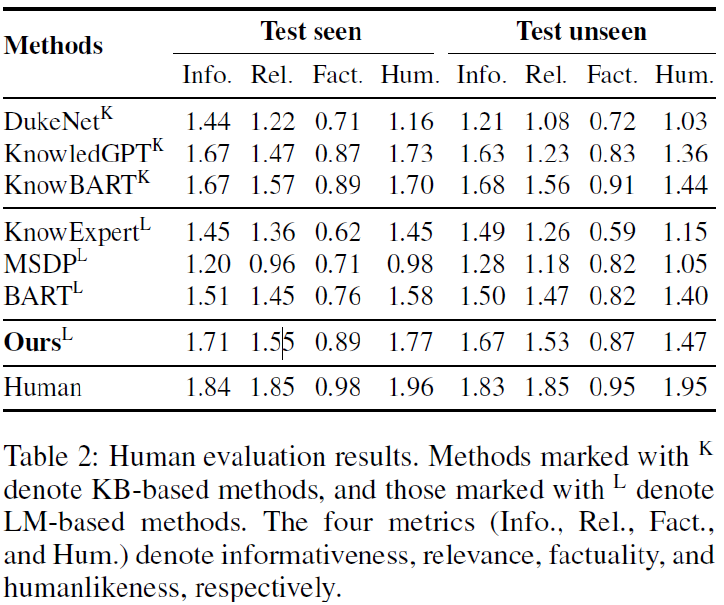
아래 Table 2는 사람이 모델 답변을 평가한 지표입니다.
마찬가지로 다른 모델들 보다 성능이 좋은 것을 알 수 있습니다.
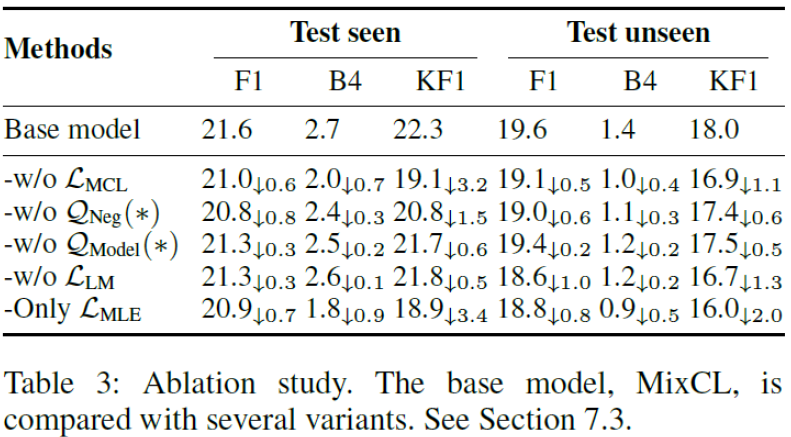
아래 Table 3은 구성 요소들을 하나씩 제거하며 학습을 한 결과입니다. 요소를 제거할 때 마다 성능이 낮아지는 것을 알 수 있습니다. 즉, 본 논문에서 모델링한 loss 함수 및 negative sampling 과정이 효과가 있다는 것을 보여줍니다.
아래 Figure 4의 세로축 F1은 모델 응답의 factuality를 나타내고, 가로축 latency는 모델의 응답 지연율을 나타냅니다. 즉, 왼쪽 위에 있을수록 성능과 효율이 좋은 것입니다. 또한 원의 크기는 모델의 파라미터 개수를 의미합니다. 즉, MicCL로 학습한 BART-Large는 다른 모델들에 비해 모델의 파라미터 수는 적고 답변 퀄리티와 응답 속도는 우수하다는 것을 나타냅니다.

Case Study
아래 Table 4는 실제 MixCL로 학습한 BART-Large의 답변입니다. 주제를 요가라고 하고 주어진 Dialogue(Context)가 있을 때, 다음에 이어질 답변을 모델들이 생성한 결과입니다. 다른 모델들은 단순한 답변을 한 반면에, 초록색에 표시된 것처럼 MicCL은 위키피디아 지식을 사용하여 더 자세하게 답변한 것을 확인할 수 있습니다.

아래 Table 6은 다음 예시를 나타냅니다. 주제는 양궁인데 다른 모델들은 빨간색으로 표시된 것처럼 검색을 잘못하여 초콜릿이나 체스와 같은 다른 답변을 합니다. 반면에 MixCL은 양궁 정보를 정확하게 전달하는 것을 알 수 있습니다.

아래 Table 7은 MicCL의 한계점을 나타내는 예시입니다. 주제는 군의관이고 끝에 캐나다의 Winnipeg이라는 도시의 소방서에 대해 말하고 있습니다. 하지만 빨간색으로 표시된 것처럼 Winnipeg 소방서는 세계에서 가장 큰 소방서가 아님에도 불구하고 세계에서 가장 크다고 답변합니다. 즉, factual 한 에러를 포함하고 있습니다. 이처럼 본 논문에서 제안한 MixCL도 여전히 Hallucination이 발생한다는 것을 알 수 있습니다.

5. Conclusion
대화형 언어 모델의 Hallucination을 개선하고자 MixCL이라는 새로운 Contrastive Learning 기반 언어 모델 학습 방법을 소개하였습니다. 기존의 연구와 차별화되는 MixCL의 핵심적인 요소는 Negative sampling strategy, Extraction Span, Mixed-contrast loss 입니다. 실험에서 데이터는 WoW Dialogue Dataset 하나만 사용하였고 학습 모델로는 BART-Large를 사용했습니다. MixCL은 기존의 Dialogue Agent(KB-based, LM-based) 보다 factuality, latency 등 대부분의 평가 지표에서 좋은 성능을 보였습니다. 또한 MixCL은 Ablation study와 Human evaluation을 통해 언어 모델의 Hallucination을 확실하게 완화할 수 있음을 보였습니다.
6. Discussion
Text Data 에서 Span-Level로 접근하여 Contrastive Learning 으로 언어 모델을 학습시키는 아이디어는 참신하고 좋았다. Positive Span과 Negative Span을 적절하게 구분하도록 Mix function을 정교하게 고안한 것이 핵심이라고 생각된다. 앞으로 언어 모델의 Hallucination을 완화하기 위해서는 Span-Level 접근 방법이 유망해 보인다.
하지만 본 논문에서 Positive Span과 Negative Span의 위치를 랜덤하게 바꾸는 부분에서 랜덤이 아닌 더 효율적이고 합리적인 방법이 있으면 어떨까 라는 생각이 든다. 또한 WoW 데이터 하나만으로 실험한 부분에서 한계라고 생각된다. 더 다양한 데이터셋으로 실험해 보았을 때 어떤 결과가 나올지 궁금하다.
Author Information
- Jihwan Oh
- Contact: jh.oh@kaist.ac.kr
- Affiliation: DISL KAIST
- Research Topic: Large Language Model, Text Summarization, Data Creation with LLM