[KDD 2020] ConSTGAT: Contextual Spatial-Temporal Graph Attention Network for Travel Time Estimation at Baidu Maps
ConSTGAT
1.0 Introduction
우리가 일상에서 사용하는 네비게이션의 역할은 도착 시간을 예측하는 것 입니다. 흔히들 도착시간 예측을 TTE(Travel Time Estimation)이라고 하는데요. 이는 네비게이션 / 라이드헤일링 / 경로예측 등등 도로 상황을 이해하고 대응하려는 다방면의 분야에서 중요하게 다뤄지는 주제입니다. 한편으로 정확하면서도 효율적으로 TTE문제를 푸는 것은 쉽지 않은데요. 이 페이지에서 다룰 논문은 이 문제를 해결하여 실제로 바이두맵에서 적용되고 있는 알고리즘입니다.
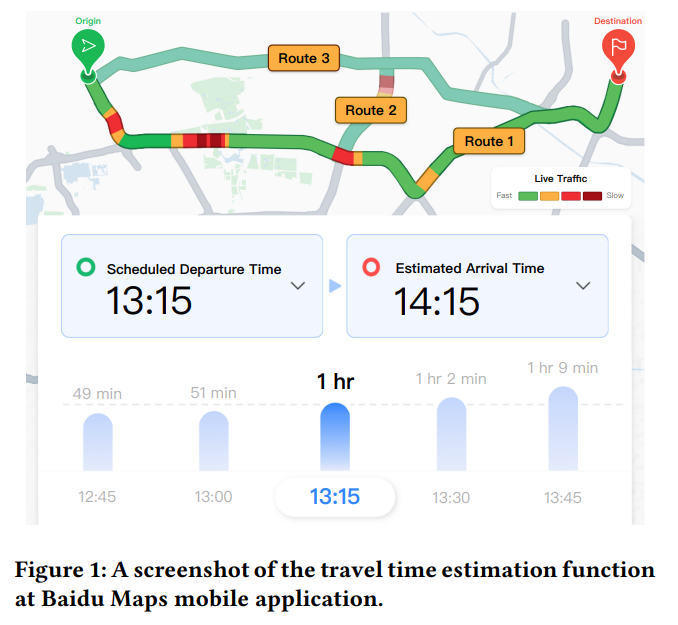
TTE 태스크가 풀어야 하는 문제는 크게 두가지입니다. 정확한 예측이 어렵다는 점, 그리고 주변 정보를 고려하기 어렵다는 점입니다.
-
Accuracy of Traffic Prediction : 루트(경로)는 여러개의 링크(도로)로 구성되어 있는데요.전체 소요 시간은 루트 안의 각 도로 세그먼트의 교통량에의해 좌우되겠습니다. 특히 시작점으로부터 떨어져 있을수록 예측이 더 어렵다는 문제가 있습니다.
TTE문제를 다뤄왔던 기존 알고리즘인 ST-GNN 의 경우 Spatial / Temporal 정보가 네트워크 안에서 각각 독립적으로 이용되기 때문에 두 정보의 상관성을 최대한 활용하지 못하고 있는 상황입니다.
-
Considering Contextual Info : 예측 시간은 인접한 두 링크의 관계도 큰 상관이 있는데요, 가령 좌회전과 우회전에 걸리는 속도가 다르다던지, 교차로의 상태가 어떠한가도 큰 영향을 미치게 됩니다. 이 문제를 푸는데 두가지 접근법이 있습니다.
첫 번째 가장 기본적인 Segment-based Approache가 있습니다. 단순히 각각의 도로 세그먼트들을 독립적으로 계산해 합산하는 방식이라, 효율적이긴 하지만 contextual information를 무시한다는 맹점이 있습니다.
두 번째 방법인 End-to-end Approaches입니다. 앞선 방법과 달리 루트의 모든 링크와 연결점들을 감안하여 전체를 한번에 계산합니다. 따라서 순차적으로 학습하기 위해 Sequence Encoding을 하다보니 연산속도가 현저히 느려진다는 단점이 있습니다.
따라서 이 논문에서는 위에 언급된 (1)Traffic Prediction 과 (2)Contextual Info 의 문제를 동시에 해결하고자 ConSTAGAT라는 모델을 제안합니다. (1) Traffic Prediction 차원에서 이 모델은 시간적, 공간적 데이터 결합해 둘 사이의 상관성을 충분히 학습하도록 Spatio-temporal GNN에 Graph Attention Mechanism을 사용하고, (2) Contextual Info 면에서는 주변정보를 효율적으로 수집하기 위해 Convolution을 활용하도록 했습니다. 마지막으로 이 두 솔루션을 합치는 과정에서 Multi-task Learning으로 퍼포먼스를 증대시키도록 했습니다.
이 논문은 크게 세 가지 점에서 Contribution을 하고 있는데요:
- Potential Impact : 산업적 솔루션으로서 end-to-end neural framework 제시한 것으로 수천만건의 요청을 처리할 수 있다는 것 입니다. 실제로 바이두맵에 ConSTGAT가 적용되어 운영되고 있다는 점이 이 사실을 증명합니다.
- Novelty : 시간과 공간의 정보를 밀접하게 활용하기 위해 Spatial-temporal graph attention network를 개발하고 적용했다는 점, 그리고 contextual info를 효율적으로 처리하게 위해 convolution과 Multi-task Learning을 적용했다는 점에서 학계에 기여한다는 점.
- Technical Quality : 거대한 현실 트래픽 데이터로 성능을 검증했다는 점 그리고 바이두맵에 성공적으로 적용해 실사용되고 있다는 점에서 실용적이고 robust한 TTE 솔루션이라는 점입니다.
2.0 Preliminary
본격적으로 설명하기 앞서, 두 가지 사항을 짚고 넘어가도록 하겠습니다. Notation 및 필요한 데이터를 확인하고, 추출하려는 대상이 무엇인지 파악하도록 합니다.
2.1 Notation
이 모델에 사용되는 데이터는 크게 네트워크에 해당되는 그래프 $G$ / 데이터셋 $D$ 이 있습니다. 후술할 실험과정에 사용되는 Taiyuan, Hefei, Huizhou 세 도시의 로그데이터 샘플값도 $G$ 와 $D$ 를 포함하고 있습니다.

2.2 Feature Extraction
학습을 위해 사용하는 특성들은; Road Network / Historical Traffic Conditions / Background Info 세 가지가 있습니다.
-
Road Network
Road Network는 링크 사이의 관계를 표현합니다. 특히 다음 여덟가지가 feature로 구성됩니다 : ID, Length, Width, # of lanes, Type, Speed Limit, Type of Crossing, Kind of Traffic Light. 여기에 추가적으로 링크 간의 지리적 관계를 표현하기 위해 graph structure을 활용합니다.
-
Historical Traffic Conditions
과거 데이터로부터 주어진 링크 $l$에 대한 타임 슬롯 $t$ 의 평균/중앙값을 feature로 추출합니다. 이 연구에서 사용되는 타임 슬롯은 5분 간격입니다.
-
Background Information
TTE는 수 많은 다른 배경 정보에도 영향을 받을 수 있는데요. 가령 출발시간이 러시아워이거나, 주중이거나, 혹은 다른 시간 관련 특징에 따라 다른 결과를 낼 수 있기 때문입니다. 따라서 이러한 시간 관련 특징도 사용하게 됩니다.
- $x_i^{(B)}$ : $i$번째 링크의 배경정보
3.0 ConSTGAT
3.1 Framework
본격적으로 ConSTGAT 모델의 구조로 들어가도록 하겠습니다. ConSTGAT는 크게 Contextual Information, Traffic Prediction 모듈로 정보를 취합하고, Integration 모듈을 통해 두 모듈을 합치고 예측하는 식 입니다.
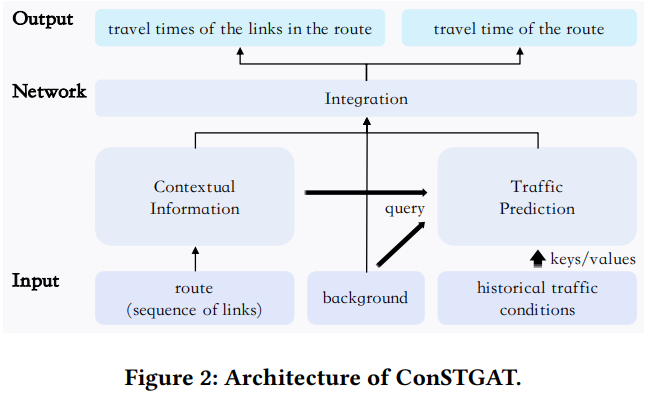
- Traffic Prediction 모듈 : 시간과 공간 데이터, 그리고 그 둘의 상관성을 포착하기 위한 모듈로, 이 논문에서 제시하는 새로운 방법인 spatial-temporal graph attention network을 통해 진행됩니다.
- Contextual Information 모듈 : Contextual Info를 잡아내는 데 활용되는 모듈로, 인접한 링크의 관계를 포착하기 위해 Convolution을 활용합니다.
- Integration 모듈 : Traffic Prediction 모듈, Contextual Information 모듈, 그리고 Background 정보까지 모든 잇풋을 취합해 예측을 하는 모듈로, Multi-task Learning으로 효율적으로 계산하는 모듈입니다.
3.2 Traffic Prediction Module
우선 첫 번째로 Traffic Prediction Module을 살펴보겠습니다. 한 링크의 교통 상황은 해당 링크의 과거 이력과 주변 이웃 링크와 큰 상관관계가 있습니다. 가령 한 링크의 교통량이 많아지면 주변 노드들의 교통량도 잇따라 많아지는 상황 같은 것이지요. 이러한 상황을 예측을 하기 위한 방법으로 STGNN이 활용되어 왔지만, 공간정보와 시간정보가 개별적으로 활용된다는 단점이 있었습니다. ConSTGAT는 이 정보의 상관성까지도 활용하기 위해, 공간정보와 시간정보를 동시에 다루는 방법인 Spatial-temporal graph attention network를 제안합니다.
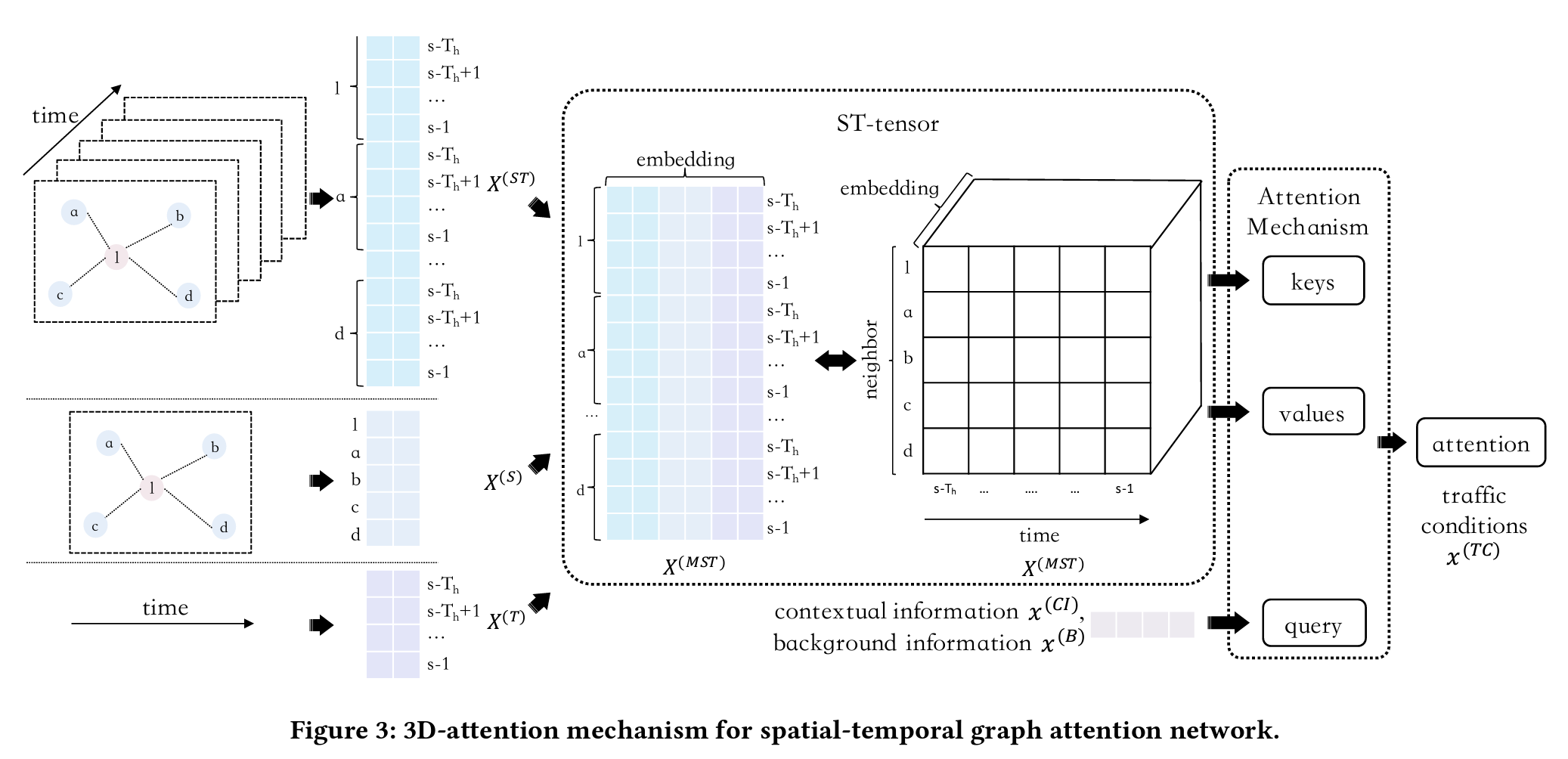
Traffic Prediction 모듈은 교통 히스토리, 그래프$G$ , 출발시간 s 를 인풋으로 받아 앞으로의 교통상황을 예측합니다. 여기서 시간-공간 관계를 포착하기 위해 Graph attention n etwork의 일종인 3D-attention mechanism 을 사용합니다. 그리고 결과적으로 1번 식과 같이 출발시간 이수 $T_{f}$개의 타임슬롯에 대한 교통상황을 예측하도록 하는 것입니다.

이를 구현하기 위한 단계는 크게 3개 단계가 있겠습니다.
1단계 ) ST-tensor 추출하기 : 시간-공간 관계 표현
이를 진행하기 위해 우선 Spatial-temporal tensor $X_i^{^{(MST)}}$을 추출합니다. $X_i^{^{(MST)}}$는 교통 히스토리 $X^{(ST)}_i$, 이웃 링크 특성 $X^{(S)}_i$, 타임슬롯 특성$X^{(T)}$ 행렬을 결합함으로써 얻을 수 있습니다. 세부 내용은 아래를 참조하세요.

조금 더 구체적으로 들어가자면, $k$번째 타임슬롯에서 링크 $i$의 이웃인 링크 $j$의 시공간 행렬은 Concat을 통해 구현될 수 있고, 이를 통해 기존의 행렬이 3D-tensor로 변환됩니다. 이 3D-tensor는 $l_i$에서의 교통상황을 예측할 spatio-temporal tensor (ST-tensor)를 만들기 위해서 반드시 가져야 할 형태이기도 합니다.

2단계 ) Attention Mechanism으로 시간과 공간의 연관 정보 추출하기 : 교통상황 파악
이 단계에선 시간과 공간 관계를 포착하기 위해 새로운 3D-attention 메커니즘을 제안하고 있습니다. 어텐션 메커니즘을 수행하려면 key, value, query가 필요한데요. 각각 다음과 같습니다.
- Query : Contextual Information $x^{(CI)}_{i,w}$ , Background Information $x^{(B)}_i$
- Key : ST-tensor $X^{(MST)}_{i,j,k}$
- Value : ST-tensor $X^{(MST)}_{i,j,k}$
이를 바탕으로 3D-attention은 다음과 같이 전개됩니다.

이에 따라 링크 $l_i$에서 지난 교통 히스토리와 query간의 관계는 8번 식에 따라 $x_i^{(TC)}=Attention(Q_i, K_i, V_i)$ 로 정리될 수 있습니다. 따라서 이렇게 3D-attention으로 구현한 GNN을 “3DGAT”라 부릅니다.
3단계 ) Masking Mechanism으로 Robustness 개선하기
이러한 모델을 학습하는 경우, 종종 약한 시그널 때문에 교통 상태 정보가 사라지게 되는 경우도 있는데요, 이러한 문제를 해결하고 모델의 robustness를 개선하기 위해 이 논문은 Masking Mechanism도 제안합니다. Masking은 NLP 분야에서 성능이 입증된 바 있습니다.
학습단계에서 랜덤하게 과거 교통 컨디션의 10%에 mask를 씌우는 것인데, 보다 구체적으로는 $req=(r,s)$에서 $c_i^t \;(i\in[1,m], t\in[s-T_h,s-1])$의 10%를 제로 벡터로 만드는 것입니다. 이렇게 뉴럴네트워크에 노이즈를 넣어 과적합을 방지하고, 모델의 generalization을 개선하려는 목적입니다.
3.3 Contextual Information Module
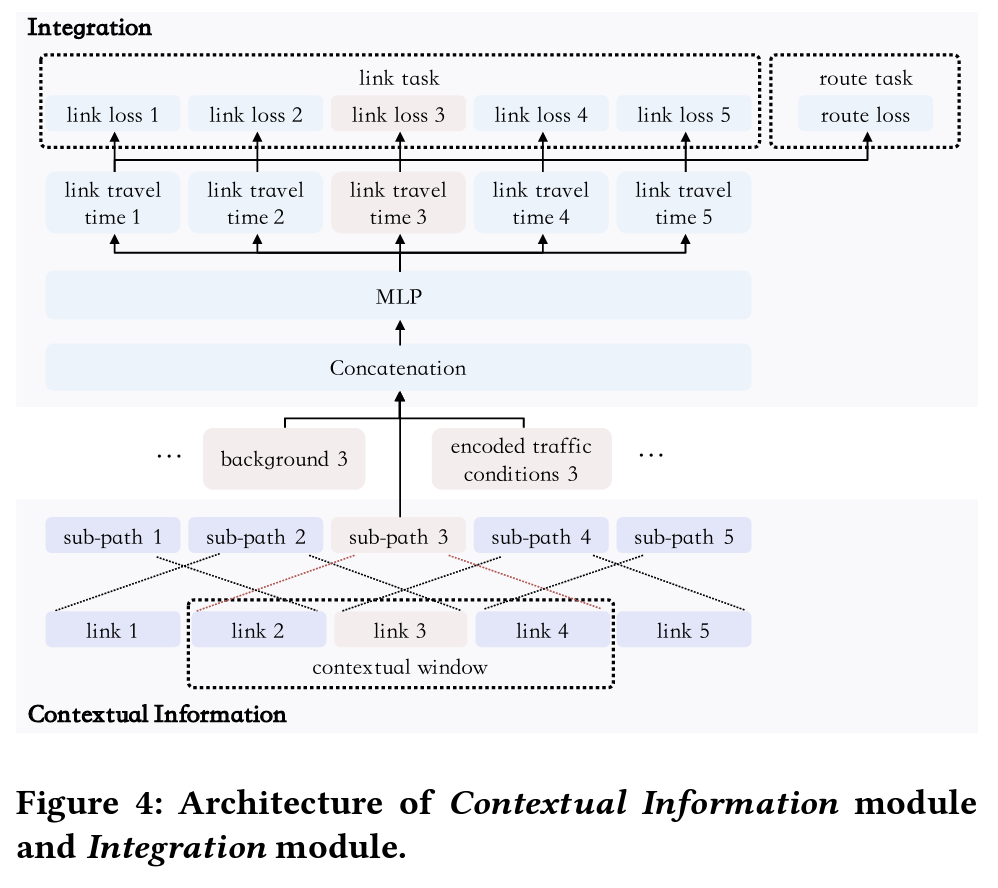
이 섹션에서는 : Convolution을 통해 주변 정보를 효율적으로 학습하는 Contextual Information Module과, Multi-task Learning을 하는 Integration Module을 다룹니다. 총 4개 단계로 이루어질 수 있는데요.
1단계 ) Contextual Information Module : 주변정보 인코딩
여기에서 주변정보, Contextual Information이라 함은, 두 링크 사이의 각도, 중심도로와 보조도로와의 관계 등을 말합니다. 이 주변정보는 travel time을 예측하는데 중요한 역할을 합니다. 여기에서는 루트에 포함된 모든 링크의 travel time을 예측하는데요, 그럴 때 루트 안의 주변 노드의 정보를 활용함으로써 예측 성능을 높이는 식입니다. 주변 노드는 sub-path라고 정의되며, 다음과 같이 표현합니다.
- $p_{i,w}=[l_{i-w},\cdot\cdot\cdot, l_{i-1}, l_{i}, l_{i+1},\cdot\cdot\cdot,l_{i+w}]$
여기에서 $i$는 계산할 대상 링크이고, $w$는 주변정보를 고려하는 window 크기를 말합니다. 가령, $w=0$ 이라면, 링크 $i$의 정보만을 고려하는 것 입니다. 이런 경우에는 segment-base method와 같은 설정이 되겠습니다. 만약 $w\rightarrow \infin$ 이라면, 루트 $r$의 모든 링크들이 고려 대상이 되고, 이는 vanilla end-to-end method와 같은 설정이 되겠습니다.
이처럼 이 모델은 특정 링크의 travel time은 주변 노드의 상황으로부터 영향을 받는다는 가정을 깔고 있는데, 이런 상황에서 CNN은 주변 정보, 즉 지역적 의존성을 수집하기 효율적인 방법입니다. 다음과 같이 $l_i$의 주변 정보를 인코딩 합니다.

이렇게 도출된 주변 정보 인코딩은 앞서 살펴보았던 Traffic Prediction Module의 쿼리와 Integration Module에 사용됩니다.
2단계 ) Integration Module : Travel Time 예측
이제 최종 예측을 위한 모듈인 Integration Module만 남았습니다. 이 단계에서는 Traffic Prediction Module $x_{i}^{(TC)}$, Context Information Module $x_{i,w}^{(CI)}$, Background Information $x_{i}^{(B)}$ 이 세개로부터 인풋을 받습니다. 이렇게 받은 인풋은 그림과 같이 Concatenation을 거쳐 Multiple Fully-connected Layer을 지나 루트안에 있는 모든 링크의 travel timed을 예측합니다.

각각 계산된 링크들의 travel time을 모두 더해 전체 루트의 travel time을 구하므로써 끝이 납니다.

3단계 ) Loss 계산
이렇게 도출된 예측 Travel time을 기반으로 Loss function을 구축하게 되는데요. 서로 다른 방식인 Segment-based method와 End-to-end method의 장점을 한번에 녹이기 위해, 지금까지 계산한 값에 대해 각각의 방식에 따른 Loss Function을 적용합니다.
Segment-based method 차원에서 사용한 손실함수는 Huber Loss로, 루트 안에 포함된 모든 각각의 링크의 travel time에 대해 계산합니다. 한편, End-to-end method 차원에서 사용한 손실함수는 APE로, 합산된 루트의 travel time에 대해 계산합니다. 이 두 방식을 한번에 담은 손실함수는 다음과 같고, 이 손실함수를 최소화 하는 방향으로 학습이 진행됩니다.

4단계 ) 현실 적용
Baidu Maps의 네비게이션은 하루에 몇백만건을 처리해야 하는데, 이런 상황에서는 반응 시간이 매우 중요합니다. 하지만 대부분 높은 정확도를 가진 모델들은 연산시간이 오래 걸리는 End-to-end 방식을 사용하기 때문에 어플리케이션을 스케일업 하기가 어려운 상황입니다.
정확도를 높게 가져가면서도, 연산의 효율성을 보장하기 위해, 이 논문에서는 segment-based method의 방법을 채택합니다. segment-based method처럼 링크 하나하나의 travel time을 단순 합산하되, 그 값들을 미리 계산해둠으로써 시간을 아끼는 방식입니다. 크게 두 스텝이 필요합니다.
- $G$ 에 포함된 모든 링크 $L$ 각각의 travel time과 관련 데이터를 병렬로 계산해 look-up 테이블에 저장합니다.
- 이때, 링크와 연결된 이웃링크 $P(l)$ 를 감안해 걸리는 시간까지 함께 계산합니다. 1단계에서 진행한 w를 고려한 만큼 계산하게 됩니다.
- 또한 history에 존재하는 서로 다른 출발시간에 대하여도 위의 모든 정보를 계산합니다: $s, s+1, \cdot\cdot\cdot , s+T_f-1$
- 위의 계산을 사전에 저장해 둔 뒤, 유저로부터 request가 도착하면, 요청에 해당되는 링크들의 travel time이 저장되어있는 look-up 테이블에서 정보를 불러와 후보 경로(루트)들이 되도록 합산합니다. 이러한 방식으로 정확하면서도 효율적인 TTE가 가능하도록 하는 것입니다.
4.0 Experiments
이렇게 디벨롭된 모델의 실제 성능은 어떨까요? 실제 데이터셋을 통해 검증한 결과를 살펴봅시다.
4.1 Experimental Settings
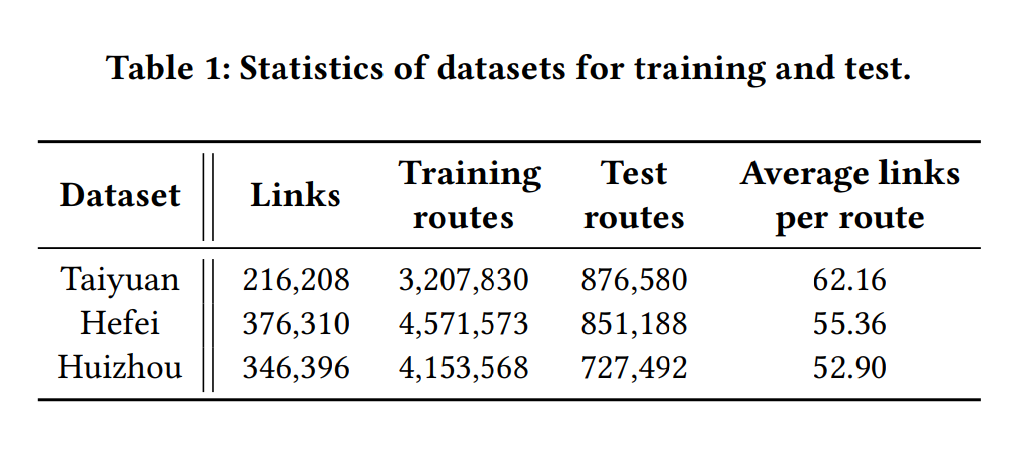
- 사용한 데이터셋
- 2019년 7월 한달 실제 바이두맵의 Taiyuan, Hefei, Huizhou 세 도시의 로그 데이터 샘플링 값
- 첫 4주 간의 데이터는 Training 용으로, 마지막 1주 간의 데이터는 Testing 용으로 분리
- 평가지표
- 회귀 문제에 널리 활용되는 평가 지표인 MAPE / MAE / RMSE 사용
4.2 Methods for Comparison
비교를 위해 사용한 모델 목록입니다. *표시 되어있는 모델이 ConSTGAT모델입니다.
| Baselines | Description | | — | — | | AVG | 2016 각 도시별 평균속도 | | DeepTravel | (1) 시간 / 공간 특성 추출 (2) bi-directional LSTM 적용 | | STANN | (1) Graph Attention으로 공간 특성 추출 (2) LSTM & Attention으로 시간 특성 추출
- 하지만 계산 과정에서 이웃 링크만 고려하는게 아니라 모든 링크를 계산한다는 단점 존재 | | DCRNN | (1) GCN으로 공간 특성 추출 (2) LSTM으로 시간 특성 & Dependency 추출 | | GAT+Attention* | (1) Graph Attention Network으로 공간 특성 추출 (2) Attention으로 공간특성 추출 → 각각 공간 / 시간 특성 별도로 취급 | | 3DGAT* | (1) Graph Attention Network으로 공간 특성 추출 (2) Attention으로 공간특성 추출 → 각각 공간 / 시간 특성 동시에 취급 |
4.3 Experimental Results
4.3.1 Overall Evaluation
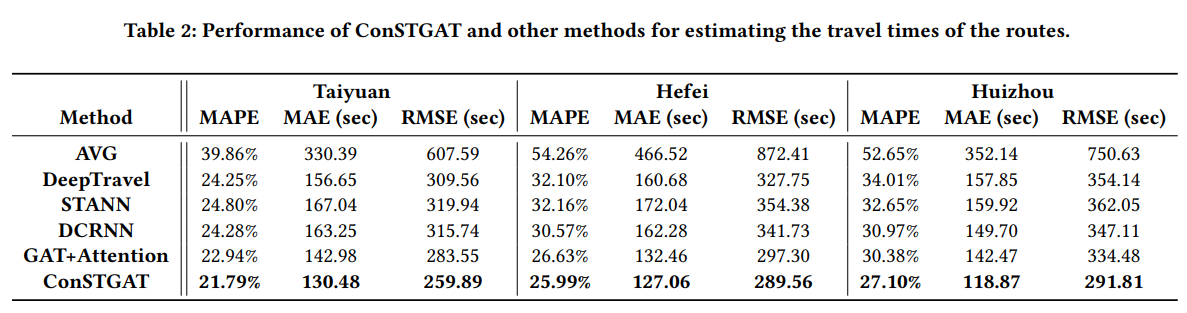
ConSTGAT 는 모든 데이터셋에 대해, 다른 모든 모델의 성능을 압도합니다.
4.3.2 Spatial-Temporal Graph Neural Networks
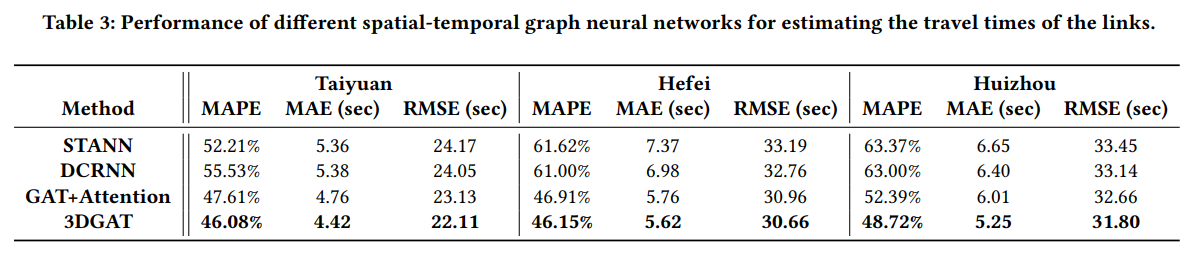
일반적인 STGNN은 전체 루트를 예측하기보다, 특정 링크를 예측하는데 최적화 되어 있습니다. 따라서 STGNN모델들간에 링크를 예측하는 지엽적인 실험도 진행되었는데요. 마찬가지로 ConSTGAT가 다른 모델을 압도하고 있는 것을 확인할 수 있습니다.
*3DGAT는 이 실험을 위해 최적화된 $w=0$인 ConSTGAT의 또 다른 버전.
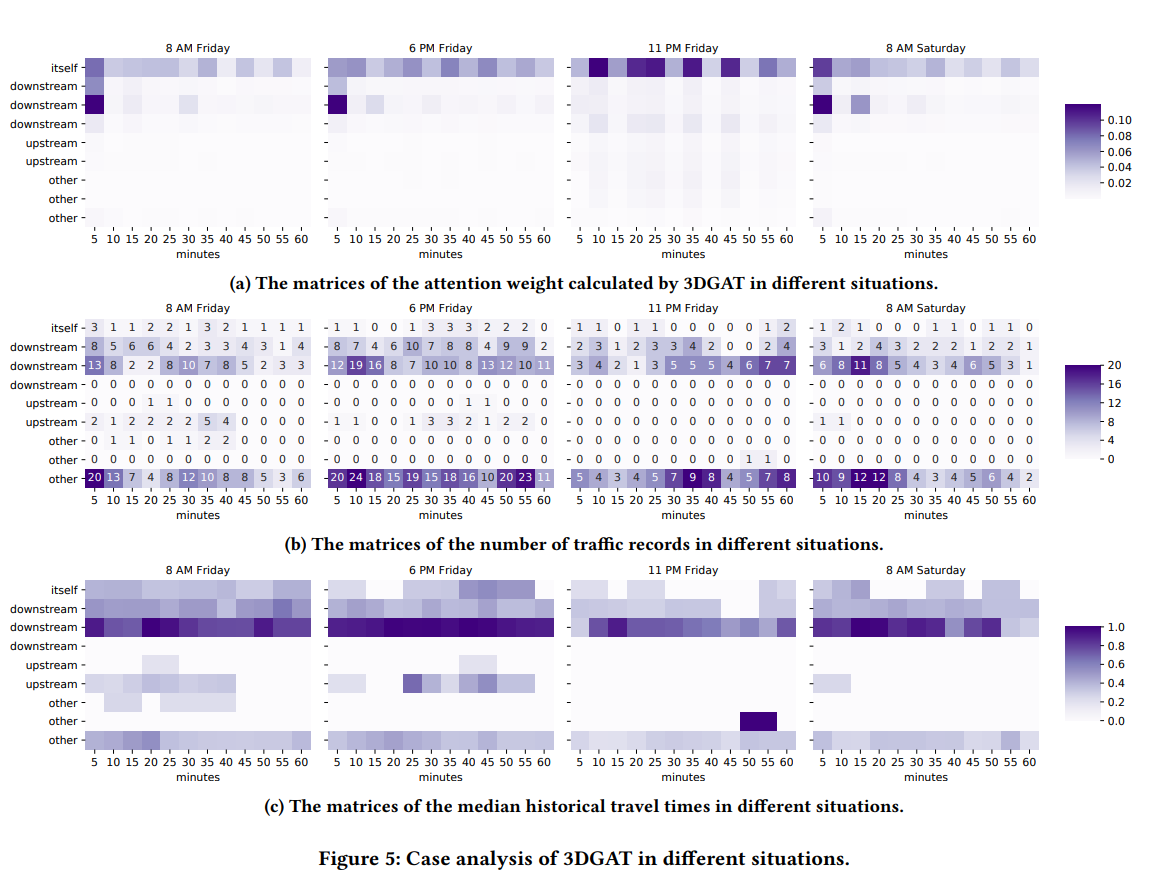
Spatial 정보와 Temporal 정보간의 상관관계를 보기 위해 Attention Weight의 행렬을 그린 것입니다. 특정 링크 $l$과 자신을 포함한 9개의 이웃들을 5분의 타임슬롯 위에서 비교했는데요. 행렬과 결과에 대한 설명입니다 :
-
ROW : itself-자기 자신 downstream 앞으로 갈 링크 upstream 지나온 링크 other 나머지 -
COLUMN : 첫번째 열 - 최신 타임슬롯 마지막 열 - 가장 나중 타임슬롯 -
COLOR : 어두운 색 - 링크 $l$에 적합함 옅은 색 - 링크 $l$에 적합하지 않음
분석결과는 첫 번째로 Downstream 링크들이 링크 $l$에 더 적합한 것으로 확인되었고, 두 번째로는 교통 기록이 더 많거나, 더 긴 travel time을 가진 링크가 예측에 더 중요한 역할을 한다는 것을 확인했습니다.
4.3.3 Contextual Information
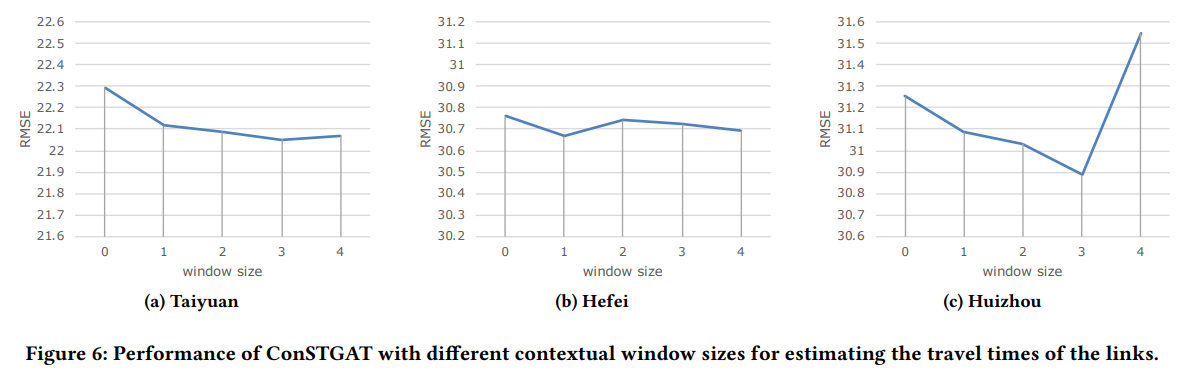
한 루트에서 contextual information의 영향이 얼마나 중요할지 알아본 분석인데요. 이 분석을 하기 위해 ConSTGAT의 contextual window size를 바꿔가며 travel time을 예측해 보았습니다. window size의 의미는 다음과 같습니다.
- $w=0$ : Segment-based method와 똑같다. 계산 시 어떠한 주변 정보도 고려하지 않음
- $w>0$ : 클 수록 주변 링크의 정보를 활용해 계산
결과적으로 주변 정보를 활용할수록 RMSE가 감소하는 것으로 보아 모델의 퍼포먼스가 개선되는 것으로 확인되었습니다. (단 Hefei의 경우 딱히 그런것 같진 않네요.)
4.3.4 Robustness
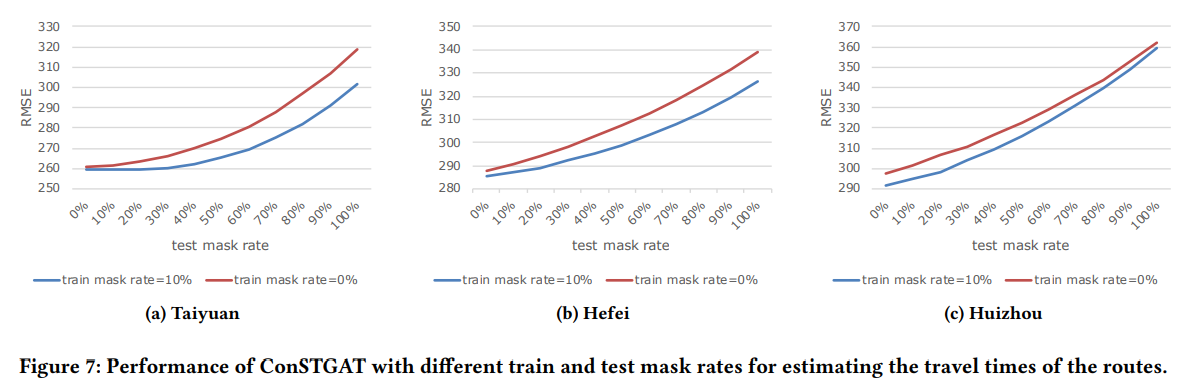
마지막으로 Masking이 모델의 robustness를 개선시키는지 확인하는 테스트입니다. 마스크 비율의 의미는 다음과 같습니다.
- Train mask rate = 0% : 모든 정보를 알되, 일부 노이즈가 있는 정도
- Train mask rate = 100% : 모든 기존 교통 컨디션은 알지 못하고, contextual info와 background info만 있는 상태
결과적으로 Train mask rate 10%인 상황이 아닌상황보다 RMSE가 전반적으로 낮게 나오는 것을 확인할 수 있습니다. 따라서 Masking은 모델의 robustness를 개선하는데 도움이 된다고 볼 수 있겠네요.
5.0 Conclusion
이 논문에은 효율적인 end-to-end STGNN모델인 ConSTGAT를 제안합니다. 기존 모델들이 (1)Traffic prediction 과 (2)Contextual information를 수집하고 가공하는데 가졌던 문제를 해결하기 위해, Spatial / Temporal 의 연관성을 깊게 가져간 3D-attention 메커니즘을 개발했습니다. 또한 주변 정보를 효율적으로 습즉하기 위해 루트의 정보를 convolution을 통해 습득했고, 나아가 퍼포먼스를 개선하기 위해 Multi-task Learning을 도입했습니다.
이 모델을 기반으로 Segment-based 방법에서 힌트를 얻어, 각각의 링크에 대한 travel time을 계산을 동시에 그리고 미리 계산하는 식으로 최종 travel time을 예측하는 프로세스까지. 유저 차원에서의 사용성까지 고려된 모델입니다.
거대 스케일의 현실 데이터를 활용한 실험을 통해 ConSTGAT의 우수성을 증명했고, 또 ConSTGAT는 바이두맵에 실제로 사용되는 알고리즘이기 때문에 실용적이며 안정적인 방법론이라고 할 수 있겠습니다.