[Recsys 2022] A User-Centered Investigation of Personal Music Tours
A User-Centered Investigation of Personal Music Tours
1. Problem Definition
How to best present music to listeners and how can this be achieved automatically with algorithms? Playlists are the most commonly used way in many streaming platforms and can be generated automatically. Can the interestingness of the played music to the listener be improved by automatically generated tours, which contain side or background information of the songs? If so, what are the attributes of the tours? Which of these attributes of the tours are good/bad? Which algorithm recommends better tours, and why? How valuable is the concept of tours in general? What are possible improvements to tours?
2. Motivation
When listening to music, people are often interested in a smooth and harmonious sequence of songs which suits their taste. Additionally, many also want to explore new music. Several platforms as Spotify, Apple Music or YouTube offer the benefit of arranging music automatically, even with regard to personal preferences and many people seem to enjoy these services, which require almost no effort from the user. One problem in this field is how to present the music to the user in the most interesting way. The most common approach is to use playlists, which can take information about the artists, genres or topics into account. Yet, there exist other ways than playlists. A radio show for example often interrupts the continuous play of music for side information or other entertainments. By doing so, the experience for the listener gets more interactive than just listening to the music.
Another alternative are tours, where songs alternate with segues. A segue is a spoken informative sentence about the realtionship between the previous and the upcoming song. By this, previously unrelated songs can be linked for the user, generating a more interesting experience. A playlist, in contrast, can hence be seen as a plain ordered list of songs. In some contexts, tours are found to be superior to playlist. The following figure compares the scheme of playlists with tours:
.png)
The authors propose two algorithms to generate music tours, which aim to maximize the interestingness of the generated tours. They evaluate their results by interviewing participants of their study after their experience to answer the following research questions:
- RQ1: What are the attributes of the tours?
- RQ2: What attributes of tours are good/bad?
- RQ3: Which algorithm recommends better tours, and why?
- RQ4: How valuable is the concept of tours in general?
- RQ5: What are possible improvements to tours?
Previous works focused mainly on the task of recommendation; i.e. choosing the best upcoming song, or creating playlists with similarities between the songs (e.g. audio similarities like beats per minute, etc or web-based similarities like Wikipedia categories). Whereas in this paper, the authors aim to maximize the interestingness of the tours and directly assess the experience of the users. The songs to be included in the tours are here assumed to be given a priori.
3. Method
The two algorithms proposed are “Greedy” and “Optimal” according to their behavior. They both try to find a permutation of the given songs and a list of segues, which maximize the interestingness of the tour. The songs and segues are represented in a knowledge graph. With a segue function paths are found in this graph between the songs. The paths representing the background information link the songs and can then be translated to text form. The graph contains various information harvested from Musicbrainz and Wikidata. The information is divided into 30 different types of nodes like musical genres; locations, e.g. where an artist was born; dates, e.g. when an artist was born; record labels, e.g. who published a song; and relationships between artists, between songs, and between artists and songs. The full information about the graph can be found in the additional matrial, but for simplification the following figure shows a simple exmaple of a music knowledge graph from another paper:
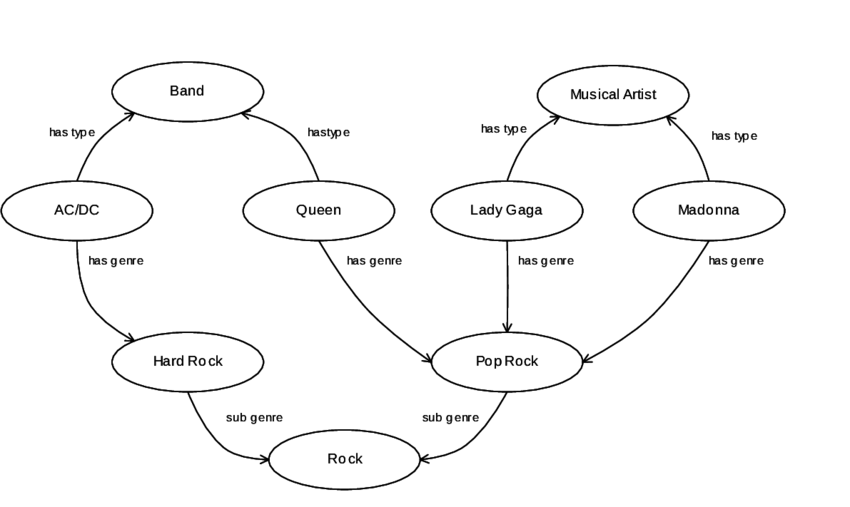
The difference between the Greedy and Optimal algorithm is the approach of choosing the paths in the graph. Greedy is a heuristic, which chooses the next song according to the instrestingness of it segue, i.e. the song with the most intersting segue is iteratively choosen next. Therefore it uses the function interestingness. The interestingness is calculated based on the infrequency and conciseness of the knowledge graph’s paths. That is, the more unique a relationship between two song is, the more interesting it is. On the other hand, if the path contains just very general information, e.g. about the same, broad genre, it should be considered as less interesting. The Optimal algorithm builds the tour by translating the problem to a Traveling Salesman Problem and solves it optimally. That is, the solution of Optimal guarantees the best tour in terms of overall interstingness; greedy can not guarantee that.
An example for the results of the two algorithm gives the following figure. It shows the tour of Greedy and Optimal respectively, build on the same set of given songs.

4. Experiment
The experiment was set up as follows: Participants were recruited via a university-restricted email system. 16 Participants were invited to the study. Each of them sent in 10 different songs of their personal favorites before the study. The two algorithms were then run with these songs and the resulting tours were saved graphically (as a PDF file like the prevoius figure) and as a single audio file containng all ten songs in the specific permutation (one for each algorithm and user) including the segues. The segues were spoken by a computer voice. During the study, each participant was presented her or his graphical PDF and the audios in a random order. After listening to it, the participants were interviewed in semi-structured questions. That is, some questions had only predefined answer options and some were open to any form of answer inlcuding the option to give no answer. As a consequence of this, the data retrieved by these interviews is not metric scaled and in case of open questions not even ordinally scaled. The only form of evaluation possible is therefore a simple majority/minority-based comparison of the answers. Similar, there is no baseline, as the authors do not compare their algorithms and results to other studies. This is partly also due to the fact that their approach is a novelty.
To answer the proposed research questions R1 - R5, the questions during the interview were about what the interviewee likes and does not like about the tours. Following with open questions probing for specific attributes of tours, such as distribution of segue interestingness throughout the tour, questions like “Is the first segue more interesting than the last?”, and “Does the interestingness of segues, from first to last, increase, decrease, stay equal, or something in the middle?” were asked. To investigate segue diversity and narrativity, it was asked wether segues are linked together to form a narrative, or are independent pieces of text. In addtion, one question was “Is the first segue more interesting than the last?” to find out about a possible segue top-bottom bias. Further questions were about the comparison of the two algortihms and the overall interestingness of the tours. Open questions investigated possible future improvements.
5. Result
Interviewees were asked to identify attributes of the tours. Regarding the top-bottom bias, many interviewees mention that the first segue in a tour is more interesting than the last segue. Among the 16 interviewees, 14 find that Greedy exhibits top-bottom bias. In Optimal, the trend is less clear: seven interviewees find top-bottom bias, seven do not, and two interviewees cannot decide. In total, seven interviewees say that the top-bottom bias is stronger in Greedy than in Optimal and the rest do not offer an opinion.
14 out of 16 mention that segue diversity (not song diversity!) is an important attribute and low diversity tours would not be nice to hear. Three and four interviewees say that Greedy and Optimal have low segue diversity, while respectively six and five of them say that Greedy and Optimal have high segue diversity.
Narritivity is not considered as a good attribute of a tour (only two out of 16 are in favour for this). This can be explained by the correlation of high narrativity with low diversity and that the flow of the conversation is not easy to follow with the songs in between. Six interviewees say that their Optimal tour is better than their Greedy tour in narrativity, four say they are not sure, and the rest do not offer an opinion.
Eleven interviewees mention that subsequent songs should have the same tempo, mood, tone, energy, melody and artistic voice. Therefore, similarity in these aspects seem to be an important attribute for these participants.
Eight participants say that song arrangement is important for them, while six say it is not. Respectively six and seven interviewees say that song arrangement is not good in Greedy and Optimal. In fact, neither algorithm optimizes for song arrangement, but for segue interestingness.
Interviewees mostly agree that Greedy produces overall better tours than Optimal. The following table provides an overview of the results:
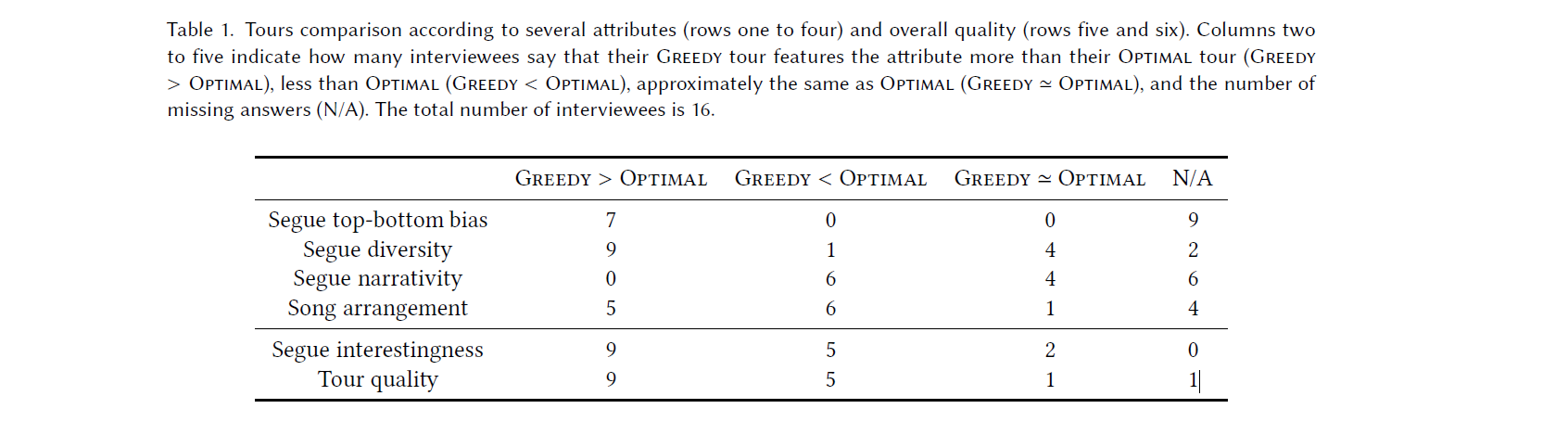
Nine out of 16 participants like the presented concept of tours and find segues interesting. However, it was also mentioned that tours a more suited for active listening than passive listening in the background.
Several improvments were proposed by participants, e.g. specific segues are more interesting than general ones; the text of segues should be limited, long segues are undesirable; prior knowledge should not be contradicted by segues and controversies should be avoided in segues.
The authors conclude from these answers that the used interestingness function in the algorithm is imperfect. Instead of maximizing the sum of the individual interestingness of the segues the diversity between the segues should also be taken into account.
6. Conclusion
Key Findings
According to the interviewees, tours recommended by Greedy feature a segue top-bottombias, that is the first segue tends to bemore interesting than the last segue, while tours recommended by Optimal do not. Tours do not always feature segue diversity, but tours recommended by Greedy are found to be more diverse than tours recommended by Optimal. Tours do not always feature segue narrativity, that is the quality that the sequence of segues in tours presents a narrative with a coherent text, but tours recommended by Optimal are found to feature more narrativity than tours recommended by Greedy. Tours do not always feature good song arrangement, and tours recommended by Greedy are found to be equally good in song arrangement to tours recommended by Optimal.
In conclusion, segue diversity and song arrangement appear to be the two most important attributes of the tours investigated in this work.
Greedy seems to recommend higher quality tours than Optimal. Interviewees motivate their choice mentioning higher segue interestingness and better song arrangement.
For further improvments, prior knowledge controversies and diversity should be taken into account when building the segues.
Personal Opinion from Reviewer
The authors described their goal, method and results well in the paper. However, there are some limitations to this work, which restrict the usage and validity of the findings. First, the findings are based on the personal impression of the users. Of course, this is due to the aim of an user-centered investigation. On the other hand, it reflects just a single experience of the user. Their statements could be biased, since they knew they are in a study. Instead, real observations, e.g. from platform users like Spotify, could be used to conduct a data-driven evaluation.
Even more concerning is the fact that the number of participants was only 16 in total, which is a rather small sample. On top of that, for several participants there are no answers to some questions. This limits the power of the results drastically. With a larger sample and clear quantifiable ratings as answers one could test statistical hypothesis.
The authors only investigated tours and compared two algoritms for tours. In the same study, the users should also have been presented playlists without segues and asked to compare the tours to playlists. This would make the study comparable to previous work.
As mentioned in the paper, similarity between songs is an important feature of tours. Yet, it is unclear how to measure this similarity. It remains subject to further research to find a suited metric.
When aiming for most interesting tours and segues, one should probably try to use the largest knowledge graph possible in order to find the most unique connections. That is, knowledge graphs from Google etc. could contain valuable information to improve the user experience.
Similar to this, since it was found that tours are more suited for active listening, one could show the actual used graph to the user. By this, the user would have the option to explore all connections on her or his own and to discover new music as well.
Author Information
- GIOVANNI GABBOLINI,
- Affiliation: Insight Centre for Data Analytics, School of Computer Science & IT, University College Cork, Ireland
- Research Topic: Recommender systems, Music information retrieval
- DEREK BRIDGE,
- Insight Centre for Data Analytics, School of Computer Science & IT, University College Cork, Ireland
- Research Topic: Case-Based Reasoning (CBR), Recommender Systems, natural language processing, machine learning, ant algorithms
Reference & Additional materials
- Reference: Giovanni Gabbolini and Derek Bridge. 2022. A User-Centered Investigation of Personal Music Tours. In Sixteenth ACM Conference on Recommender Systems (RecSys ’22), September 18–23, 2022, Seattle, WA, USA.ACM, NewYork, NY, USA, 16 pages. https://doi.org/10.48550/arXiv.2208.07807
- Github Implementation: https://github.com/GiovanniGabbolini/play-it-again-sam
- Additional materials: https://zenodo.org/record/6817643