[AAAI-2024] Fine-Tuning Large Language Model Based Explainable Recommendation with Explainable Quality Reward
1. Problem Definition
설명 가능한 추천 시스템의 기존 방식은 다음과 같은 문제점을 갖고 있습니다.
1. 개인화 부족: LLM 기반 설명 추천 시스템은 대개 일반적인 데이터를 기반으로 학습되기 때문에 개인화된 정보가 부족합니다. 이로 인해 아래의 예시 그림처럼 사용자 맞춤형 설명을 생성하지 못하며, 사용자 선호도와 일치하지 않는 설명이 생성될 수 있습니다.
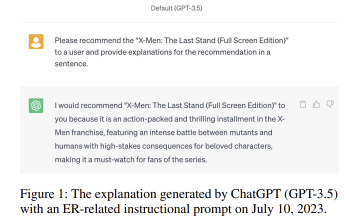
2. 일관성 문제: LLM이 생성하는 설명은 정보가 과부하된 경향이 있으며, 사용자가 관심 없는 항목에 대한 불필요한 정보도 포함될 수 있습니다. 이로 인해 설명의 일관성이 떨어지고, 사용자 경험이 저하될 수 있습니다.
3. 품질 낮은 설명 데이터: LLM을 추천 시스템 작업에 잘 적응시키기 위해서는 설명 데이터로 미세 조정이 필요하지만, 기존 데이터는 품질이 낮거나 충분하지 않습니다. 사용자 리뷰는 때때로 부실하며, 이러한 리뷰 데이터를 기반으로 모델을 학습시키는 것은 설득력 있는 설명을 생성하는 데 한계가 있습니다.
이 문제들을 해결하기 위해 저자들은 강화 학습을 사용하여 설명 품질 보상 모델을 설계하고, 이를 통해 더 높은 품질의 개인화되고 일관성 있는 설명을 생성할 수 있는 LLM2ER-EQR 모델을 제안합니다.
2. Motivation
기존 연구와의 비교
기존의 LLM 기반 설명 가능한 추천(ER) 모델들은 주로 프롬프트 설계를 통해 LLM이 직접 설명을 생성하도록 하는 접근법을 사용했습니다. 예를 들어, PETER는 개인화된 정보를 포함한 프롬프트를 설계하여 설명 생성 성능을 향상시키려 했습니다. 그러나 이러한 방법들은 여전히 개인화 정도가 제한적이며, 사용자 선호도와 아이템 특성을 동시에 반영하는 데 한계가 있었습니다.
또한, ReXPlug와 같은 일부 연구는 제어된 텍스트 생성을 통해 품질 낮은 리뷰 데이터와 개인화 문제를 부분적으로 해결하려 했습니다. 그러나 여전히 설명의 일관성과 정보 과부하 문제를 완전히 해결하지는 못했습니다.
본 연구의 차별성
이러한 한계점을 극복하기 위해 본 논문에서는 다음과 같은 새로운 접근법을 제안합니다:
-
개념 그래프 활용: 사용자와 아이템의 상호작용과 관련된 개념들을 추출하여 개념 그래프를 구축하고, 이를 통해 사용자 선호도와 아이템 특성을 효과적으로 반영합니다.
-
강화 학습 기반 미세 조정: 인간의 피드백 없이도 모델이 설명의 품질을 자체적으로 개선할 수 있도록 강화 학습을 적용합니다.
-
설명 품질 보상 모델: 개념 일관성 보상 모델(CCR)과 고품질 정렬 보상 모델(HQAR)을 설계하여 설명의 일관성과 품질을 동시에 향상시킵니다.
이로써 기존 모델들이 가진 개인화 부족, 일관성 문제, 품질 낮은 데이터의 한계를 동시에 해결하고자 합니다.
3. Method
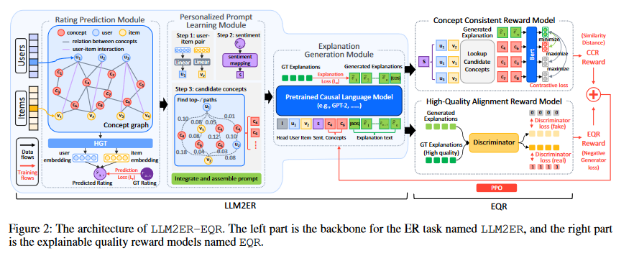
본 논문에서 제안하는 방법론은 LLM2ER라는 대형 언어 모델 기반 설명 추천 시스템을 강화 학습 기법으로 미세 조정하여 LLM2ER-EQR 모델을 구축하는 과정입니다. 이 과정에서 설명의 개인화와 일관성을 보장하고, 고품질 설명 데이터를 기반으로 학습할 수 있도록 여러 모델을 사용합니다.
1) LLM2ER Backbone
LLM2ER는 기본적으로 사용자와 아이템 간의 상호작용을 반영하여 개인화된 설명을 생성하는 시스템입니다. 이를 위해 다음과 같은 두 가지 주요 모듈을 사용합니다.
(a) 협력적 개념 기반 평가 예측 모듈
사용자의 선호도와 아이템의 특성을 반영한 개념 그래프를 구축하여 평가를 예측합니다. 개념 그래프는 사용자, 아이템, 그리고 이들과 관련된 개념들로 구성된 이질적인 그래프입니다.
-
이질적인 그래프 변환기(HGT): 이 그래프의 복잡한 구조를 학습하기 위해 HGT를 사용하여 각 노드(사용자, 아이템, 개념)의 임베딩을 학습합니다.
HGT는 각 노드와 에지의 타입을 고려하여 메시지 전달을 수행하며, 노드의 표현을 업데이트합니다.
-
평가 예측: 학습된 사용자 임베딩 $\mathbf{h}_ u$와 아이템 임베딩 $\mathbf{h}_ v$를 결합하여 예측된 평가 점수 $\hat{r}_ {u,v}$를 계산합니다.
$ \hat{r}_{u,v} = \text{MLP}([\mathbf{h}_u, \mathbf{h}_v]) $
여기서 $\text{MLP}$는 다층 퍼셉트론, $[\cdot]$는 벡터 결합(concatenation)을 의미합니다.
-
손실 함수: 실제 평가 점수 $r_{u,v}$와 예측된 평가 점수 $\hat{r}_{u,v}$ 간의 차이를 최소화하기 위해 평균 제곱 오차(MSE) 손실을 사용합니다.
$ L_ r = \frac{1}{\vert \Omega_ {\text{train}} \vert} \sum_ {(u,v) \in \Omega_ {\text{train}}} (r_ {u,v} - \hat{r}_ {u,v})^2 $
(b) 개인화된 프롬프트 학습 모듈
개인화된 정보를 LLM에 효과적으로 전달하기 위해 프롬프트를 구성합니다. 프롬프트는 다음의 요소들로 구성됩니다.
-
프롬프트 헤드 $I$: 설명 생성에 대한 지침을 자연어로 제공합니다.
-
사용자 및 아이템 임베딩 $(\mathbf{p}_u, \mathbf{q}_v)$: 학습된 임베딩을 LLM의 토큰 임베딩 차원에 맞게 선형 변환합니다.
$ (\mathbf{p}_u, \mathbf{q}_v) = (\text{Linear}(\mathbf{h}_u), \text{Linear}(\mathbf{h}_v)) $
-
감정 표현 $s_{u,v}$: 예측된 평가 점수를 기반으로 긍정 또는 부정의 감정을 나타냅니다. 5점 척도의 평점을 기준으로 3점 이상은 긍정, 미만은 부정으로 매핑합니다.
-
후보 개념 집합 ${c}_{u,v}$: 개념 그래프에서 추출한 사용자와 아이템 간의 상호작용을 나타내는 개념들의 집합입니다. 빔 서치(beam search)를 통해 상위 $l$개의 경로를 선택하고, 해당 경로에 포함된 개념들을 후보로 사용합니다.
최종적으로, 개인화된 프롬프트 $x_{u,v}$는 다음과 같이 구성됩니다.
$ x_ {u,v} = [I, \mathbf{p}_ u, \mathbf{q}_ v, s_ {u,v}, {c}_ {u,v}] $
(c) 설명 생성 모듈
프롬프트 $x_{u,v}$를 입력으로 받아, 사전 학습된 언어 모델(예: GPT-2)을 사용하여 설명 $\hat{e}_{u,v}$를 생성합니다.
생성 과정은 다음과 같습니다.
$ \hat{e}_ {u,v,i} = \arg\max_ {e_ {u,v,i}} P_ {\text{LM}}(e_ {u,v,i} \vert x_ {u,v}, \hat{e}_ {u,v,<i}) $
여기서 $\hat{e}_ {u,v,<i}$는 이전에 생성된 단어들의 시퀀스입니다.
손실 함수: 실제 설명 $e_ {u,v}$와 생성된 설명 $\hat{e}_ {u,v}$ 간의 차이를 최소화하기 위해 음의 로그 우도(NLL) 손실을 사용합니다.
$ L_ e = \frac{1}{\vert\Omega_ {\text{train}}\vert} \sum_ {(u,v) \in \Omega_ {\text{train}}} \frac{1}{n} \sum_ {t=1}^{n} -\log P(e_ {u,v,t}) $
2) 강화 학습을 통한 미세 조정
강화 학습을 통해 모델이 설명의 품질을 자체적으로 개선할 수 있도록 합니다. 이를 위해 두 가지 보상 모델을 설계합니다.
(a) 개념 일관성 보상 모델 (Concept Consistent Reward Model, CCR)
CCR은 생성된 설명 $\hat{e}_ {u,v}$와 후보 개념 ${c}_ {u,v}$ 간의 의미적 유사도를 측정하여 보상을 제공합니다.
-
BERT 임베딩: 생성된 설명과 후보 개념들을 BERT를 사용하여 임베딩합니다.
-
코사인 유사도 계산: 두 임베딩의 평균 벡터 간의 코사인 유사도를 계산합니다.
$ R_ {\text{CCR}}(\hat{e}_ {u,v}, {c}_ {u,v}) = \cos\left( \text{avg}(\text{BERT}(\hat{e}_ {u,v})), \text{avg}(\text{BERT}({c}_ {u,v})) \right) $
-
보상 학습: 긍정 샘플(타겟 사용자-아이템 쌍의 생성된 설명과 후보 개념)과 부정 샘플(다른 사용자-아이템 쌍의 생성된 설명과 후보 개념)을 사용하여 대조 학습(Contrastive Learning)을 수행합니다. 손실 함수는 다음과 같습니다.
$ L_ c = \frac{1}{\vert\Omega_{\text{train}}\vert} \sum_ {(u,v) \in \Omega_ {\text{train}}} \log \frac{\exp(R_ {\text{CCR}}(\hat{e}_ {u,v}, {c}_ {u,v}))}{\sum_ {(u’,v’) \in N_ {u,v}} \exp(R_ {\text{CCR}}(\hat{e}_ {u’,v’}, {c}_ {u’,v’}))} $
여기서 $N_{u,v}$는 부정 샘플의 집합입니다.
(b) 고품질 정렬 보상 모델 (High-Quality Alignment Reward Model, HQAR)
HQAR은 생성된 설명이 고품질 설명 데이터와 얼마나 일치하는지를 평가합니다.
-
고품질 설명 데이터셋 $H$ 구축: 개념 포함 비율이 일정 임계값 이상인 설명들을 선택하여 고품질 데이터셋을 만듭니다.
-
판별자(Discriminator): 생성된 설명 $\hat{e}_{u,v}$와 고품질 설명 $h \in H$를 입력으로 받아, 해당 설명이 고품질인지 여부를 예측합니다.
-
보상 계산: 생성된 설명이 고품질 설명으로 분류되지 않을 확률의 로그에 음수를 취하여 보상으로 사용합니다.
$ R_ {\text{HQAR}}(\hat{e}_ {u,v}) = -\sum_ {i=1}^{n} \log(1 - p_ {\hat{e}_ {u,v,i}}) $
여기서 $p_ {\hat{e}_ {u,v,i}}$는 판별자가 $\hat{e}_ {u,v,i}$가 고품질 설명으로부터 생성되었을 확률입니다.
-
손실 함수: 판별자를 학습하기 위해 이진 교차 엔트로피 손실을 사용합니다.
$ L_ d = -\frac{1}{\vert\Omega_{\text{train}}\vert + \vert H \vert} \left( \sum_ {(u,v) \in \Omega_ {\text{train}}} \sum_{i=1}^{n} \log(1 - p_ {\hat{e}_ {u,v,i}}) + \sum_ {h \in H} \sum_ {i=1}^{n} \log p_ {h_ i} \right) $
3) 모델 훈련 과정
모델 훈련은 다음의 단계로 이루어집니다.
-
평가 예측 모듈 학습: $L_r$을 최소화하여 사용자와 아이템의 임베딩을 학습합니다.
-
설명 생성 모듈 학습: $L_e$를 최소화하여 LLM이 실제 설명을 잘 생성하도록 학습합니다.
-
보상 모델 학습: CCR과 HQAR을 학습하여 보상 함수를 구성합니다.
-
강화 학습을 통한 미세 조정: 보상 함수를 최대화하도록 LLM을 미세 조정합니다. 최종 목표 함수는 다음과 같습니다.
$ R(x_ {u,v}, \hat{e}_ {u,v}) = \lambda_ {\text{CCR}} R_ {\text{CCR}}(\hat{e}_ {u,v}, {c}_ {u,v}) + \lambda_ {\text{HQAR}} R_ {\text{HQAR}}(\hat{e}_ {u,v}) $
여기서 $\lambda_ {\text{CCR}}$, $\lambda_ {\text{HQAR}}$는 보상 함수의 중요도를 조절하는 하이퍼파라미터입니다.
강화 학습 알고리즘으로는 Proximal Policy Optimization (PPO)를 사용하여 정책을 업데이트합니다.
4) 용어 설명 및 수식 유도
-
이질적인 그래프 변환기(HGT): 다양한 유형의 노드와 에지가 있는 이질적인 그래프에서 각 노드의 표현을 학습하는 모델입니다. HGT는 노드와 에지의 타입을 고려하여 메시지 패싱을 수행합니다.
-
대조 학습(Contrastive Learning): 긍정 및 부정 샘플 쌍을 사용하여 임베딩 공간에서 유사한 샘플은 가깝게, 다른 샘플은 멀어지도록 학습하는 방법입니다. CCR의 손실 함수 $L_c$는 InfoNCE (Information Noise Contrastive Estimation) 손실을 기반으로 합니다.
-
판별자(Discriminator): 생성된 샘플이 실제 데이터에서 온 것인지 생성된 것인지 구분하는 모델로, 생성자(Generator)와 함께 GAN (Generative Adversarial Network)을 구성합니다. HQAR에서 판별자는 고품질 설명과 생성된 설명을 구분하는 역할을 합니다.
-
Proximal Policy Optimization (PPO): 강화 학습에서 정책을 업데이트하기 위한 알고리즘으로, 큰 정책 변화로 인한 성능 저하를 방지합니다.
4. Experiment
1) Dataset
실험에는 세 가지 공공 추천 데이터셋이 사용되었습니다:
-
Amazon (Movies & TV): 영화 및 TV 프로그램에 대한 리뷰와 평점을 포함합니다.
-
Yelp (2019): 다양한 비즈니스에 대한 리뷰와 평점을 포함합니다.
-
TripAdvisor: 여행 및 호텔에 대한 리뷰와 평점을 포함합니다.
데이터셋 통계는 다음과 같습니다:
| Dataset | # Users | # Items | # Explanations | # Concepts | # Triplets | Avg. # Explanations/User | Avg. # Explanations/Item | Avg. # Concepts/Explanation |
|---|---|---|---|---|---|---|---|---|
| Amazon (Movies & TV) | 7,506 | 7,316 | 432,075 | 10,141 | 7,223,673 | 57.56 | 59.06 | 7.33 |
| Yelp (2019) | 27,147 | 18,172 | 1,189,056 | 14,657 | 31,417,433 | 43.80 | 65.43 | 11.46 |
| TripAdvisor | 9,765 | 5,429 | 296,118 | 10,948 | 6,992,065 | 30.32 | 54.54 | 9.73 |
2) Baseline
모델 성능을 비교하기 위해 다음과 같은 Baseline 모델들을 사용했습니다:
-
CAML: GRU 기반의 설명 생성 모델
-
NETE: 템플릿 기반 설명 생성 모델
-
ReXPlug: 제어된 텍스트 생성 모델
-
PETER: 프롬프트 학습을 활용한 LLM 기반 모델
-
PEVAE: 변이형 오토인코더를 활용한 모델
-
PRAG: 사실적 오류 문제를 해결한 모델
-
CVAEs: 대조 학습을 활용한 변이형 오토인코더 모델
3) Evaluation Metrics
-
BLEU: 생성된 설명과 실제 설명 간의 n-그램 일치를 측정하여 문법적 유창성을 평가합니다.
-
ROUGE: 생성된 설명과 실제 설명 간의 겹치는 단어를 기반으로 요약 능력을 평가합니다.
-
Distinct-1, Distinct-2: 생성된 설명 내에서 고유한 1-그램 및 2-그램의 비율을 측정하여 다양성을 평가합니다.
-
Concept Overlapping Ratio (COR): 동일한 아이템에 대한 다른 사용자들의 설명에서 개념의 중복도를 측정합니다.
$ \text{COR}(v) = \frac{1}{\vert U_ v\vert(\vert U_ v\vert - 1)} \sum_ {u \in U_ v, u’ \in U_ v, u \ne u’} \frac{\vert(e_ {u,v} \cap C_ {u,v}) \cap (e_ {u’,v} \cap C_ {u’,v})\vert}{\vert(e_ {u,v} \cap C_ {u,v}) \cup (e_ {u’,v} \cap C_ {u’,v})\vert} $
여기서 $U_v$는 아이템 $v$를 평가한 사용자들의 집합입니다.
-
Concept Matching Ratio (CMR): 생성된 설명이 후보 개념과 얼마나 일치하는지를 측정합니다.
$ \text{CMR} = \frac{1}{\vert\Omega_ {\text{test}}\vert} \sum_ {(u,v) \in \Omega_ {\text{test}}} \sum_ {c \in C_ {u,v}} \delta(c \in e_ {u,v}) $
여기서 $\delta(\cdot)$는 인디케이터 함수입니다.
4) Experiment Results
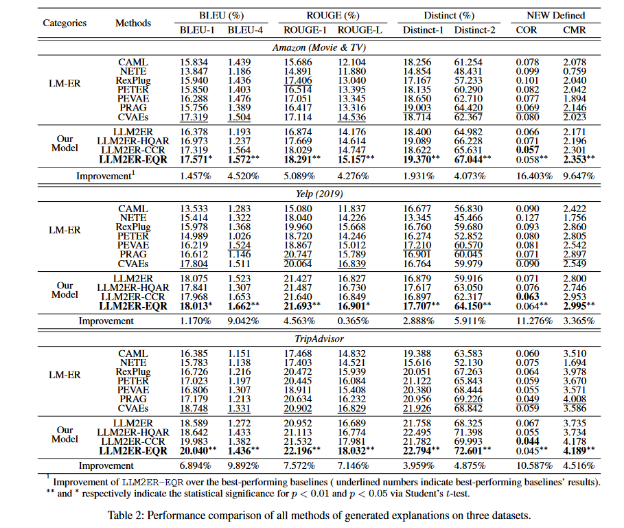
실험 결과, LLM2ER-EQR 모델은 모든 데이터셋에서 Baseline 모델들을 능가하는 성능을 보여주었습니다.
(a) 텍스트 품질 측면
-
BLEU 및 ROUGE 점수: 생성된 설명이 실제 설명과 문법적으로 유사하고 내용적으로 풍부함을 나타냅니다.
- 예를 들어, Amazon 데이터셋에서 BLEU-4 점수는 LLM2ER-EQR이 1.572로, 기존 최고 성능 모델인 CVAEs의 1.504보다 4.5% 향상되었습니다.
-
실험 결과 해석: 높은 BLEU와 ROUGE 점수는 모델이 실제 인간의 언어 표현과 유사한 설명을 생성함을 의미합니다.
(b) 설명 품질 측면
-
Distinct 점수: 설명의 다양성과 독창성이 높음을 보여줍니다.
- Yelp 데이터셋에서 Distinct-2 점수는 LLM2ER-EQR이 64.150으로, Baseline 모델들보다 높은 값을 나타냈습니다.
-
COR 및 CMR: 개인화와 개념 일관성이 높음을 나타냅니다.
- TripAdvisor 데이터셋에서 CMR 점수는 LLM2ER-EQR이 4.189로, 기존 모델들보다 4.5% 이상 향상되었습니다.
-
실험 결과 해석: 낮은 COR 값은 설명들이 서로 중복되지 않고 다양함을 의미하며, 높은 CMR 값은 생성된 설명이 사용자와 아이템의 개념과 잘 일치함을 나타냅니다.
5) 모델의 한계 및 강화 학습의 영향
논문에서 직접 언급되지는 않았지만, 다음과 같은 모델의 한계점이나 강화 학습의 성능 저하 가능성이 있을 수 있습니다:
-
모델의 복잡성: 개념 그래프를 구축하고 강화 학습을 적용하는 과정이 복잡하여, 대규모 데이터셋에서의 확장성 문제가 있을 수 있습니다.
-
강화 학습의 안정성: 강화 학습은 학습 과정에서 불안정할 수 있으며, 보상 함수의 설계에 따라 성능이 크게 좌우될 수 있습니다.
-
보상 모델의 일반화 능력: CCR과 HQAR이 특정 도메인이나 데이터셋에 과적합될 가능성이 있으며, 새로운 도메인에서의 일반화 성능이 떨어질 수 있습니다.
-
계산 비용: 복잡한 모델 구조와 강화 학습으로 인해 계산 비용이 증가하여 실시간 시스템에 적용하기 어려울 수 있습니다.
따라서, 이러한 한계점을 고려하여 모델을 개선하고 적용 범위를 넓히는 것이 향후 연구에서 중요할 것입니다.
5. Conclusion
이 논문은 대형 언어 모델(LLM) 기반 설명 추천 시스템의 성능을 향상시키기 위해 LLM2ER-EQR이라는 새로운 모델을 제안했습니다. 기존 시스템이 가진 개인화 부족, 설명의 일관성 문제, 그리고 품질 낮은 데이터의 한계를 극복하기 위해, 강화 학습을 사용한 보상 모델을 설계하여 설명의 품질을 크게 개선했습니다.
Key Takeaways:
-
강화 학습은 모델이 설명의 품질을 스스로 개선할 수 있도록 하는 강력한 방법으로 작용했습니다.
-
개념 그래프를 활용하여 사용자와 아이템의 상호작용을 효과적으로 반영했습니다.
-
개인화된 설명이 사용자 경험을 높이는 데 중요한 역할을 하며, 설명의 일관성을 높이는 것이 추천 시스템의 신뢰성을 강화합니다.
-
보상 기반 학습을 통해, 인간 피드백 없이도 시스템이 고품질 설명을 제공할 수 있는 모델로 발전할 수 있음을 보여줍니다.
Take Home Message:
이 연구의 핵심은 추천 시스템의 설명이 단순한 정보 제공이 아닌, 사용자 맞춤형으로 전달되어야 한다는 것입니다. 이를 통해 사용자는 더 나은 선택을 할 수 있게 되고, 추천 시스템의 신뢰성도 자연스럽게 증가합니다. LLM과 강화 학습의 결합은, 복잡한 사용자 요구를 반영하는 개인화된 설명 시스템을 구현하는 데 매우 효과적임을 증명했습니다.
향후 연구 방향 및 고려사항:
-
모델의 확장성 개선: 대규모 데이터셋에서도 효율적으로 작동할 수 있도록 모델의 복잡성을 줄이는 방법을 연구할 필요가 있습니다.
-
일반화 능력 향상: 다양한 도메인에 적용할 수 있도록 보상 모델과 전체 시스템의 일반화 능력을 높이는 것이 중요합니다.
-
실시간 적용 가능성: 계산 효율성을 향상시켜 실시간 추천 시스템에 적용할 수 있도록 하는 것이 향후 과제입니다.
6. 추가 이미지 및 내용
실험 설정 및 추가 결과
실험의 설정과 추가적인 결과를 제공하기 위해 남은 이미지를 포함합니다.
(a) Personalized Prompt
개인화된 프롬프트 예시는 다음과 같습니다:
Prompt head: Please generate a recommendation explanation.
Query input: Based on the {sentiment: positive/negative} sentiment and candidate concepts including {candidate concepts, e.g., user preferences, item features}, please provide explanations to recommend {item embedding} to {user embedding}.
Query output: {explanation}
(b) Concept Selection Effectiveness
개념 선택이 모델 성능에 미치는 영향을 분석하기 위해 다양한 최대 경로 길이와 경로 선택 수에 따른 성능 변화를 실험하였습니다.
- 결과 해석: 최대 경로 길이와 경로 선택 수가 너무 크면 후보 개념의 수가 증가하여 COR 값이 높아져 개인화 정도가 감소할 수 있습니다. 반대로 너무 작으면 CMR 값이 낮아져 설명의 일관성이 떨어질 수 있습니다.
(c) Qualitative Case Study

생성된 설명의 사례 비교를 통해 모델의 우수성을 보여줍니다.
-
Case 1: 동일한 아이템에 대해 다른 사용자에게 추천할 때, LLM2ER-EQR은 사용자 선호도에 맞는 개인화된 설명을 생성합니다.
-
Case 2: 생성된 설명은 Baseline 모델들보다 더 많은 사용자 선호도와 아이템 특성을 포함하며, 정보성이 높습니다.