[SIGIR 2024] Pacer and Runner Cooperative Learning Framework between Single- and Cross-Domain Sequential Recommendation
저자: Chung Park, Taesan Kim, Hyungjun Yoon, Junui Hong, Yelim Yu, Mincheol Cho, Minsung Choi, Jaegul Choo
출판: SIGIR ‘24, July 14–18, 2024, Washington, DC, USA
리뷰어: 20219003 Sang Wook Park
0. Preliminaries
Cross-Domain Sequential Recommendation (CDSR): CDSR은 사용자의 여러 도메인에 걸친 상호작용 시퀀스를 활용하여 다음 아이템을 예측하는 추천 시스템 접근 방식이다. 이는 Single-Domain Sequential Recommendation (SDSR)과 대조되는데, SDSR은 특정 도메인 내의 상호작용만을 고려한다.
Negative Transfer: 한 도메인에서 학습한 지식이 다른 도메인의 성능을 저하시키는 현상을 말한다.
CDSR에서 이는 특히 도메인 간 관계가 약하거나 데이터 희소성 수준이 다를 때 발생할 수 있다.
1. 문제 정의
CDSR은 여러 도메인의 정보를 활용하여 추천 성능을 향상시키는 것을 목표로 한다. 그러나 일부 도메인에서 CDSR이 SDSR보다 성능이 떨어지는 부정적 전이 문제가 발생할 수 있다. 이 논문은 이러한 부정적 전이 문제를 해결하고 모든 도메인에서 일관된 높은 성능을 달성하는 것을 목표로 한다.
구체적으로, 주어진 시간 t까지의 크로스 도메인 시퀀스 $X_ {1:t}$를 기반으로 다음 아이템 $x^d_ {t+1}$을 예측하는 것이 목표이다:
$argmax_ {x^d_ {t+1} ∈ V_ d} P(x^d_ {t+1} \vert X_ {1:t})$
여기서 $V_ {d}$는 도메인 d의 아이템 집합이다.
2. 동기
기존 CDSR 모델들은 부정적 전이 문제를 효과적으로 해결하지 못했다. 특히, 일부 도메인에서 CDSR의 성능이 SDSR보다 낮아지는 현상이 관찰되었다. 또한 많은 모델들이 도메인 쌍 간의 관계만을 모델링하여 다수의 도메인을 다루는 데 한계가 있었다.
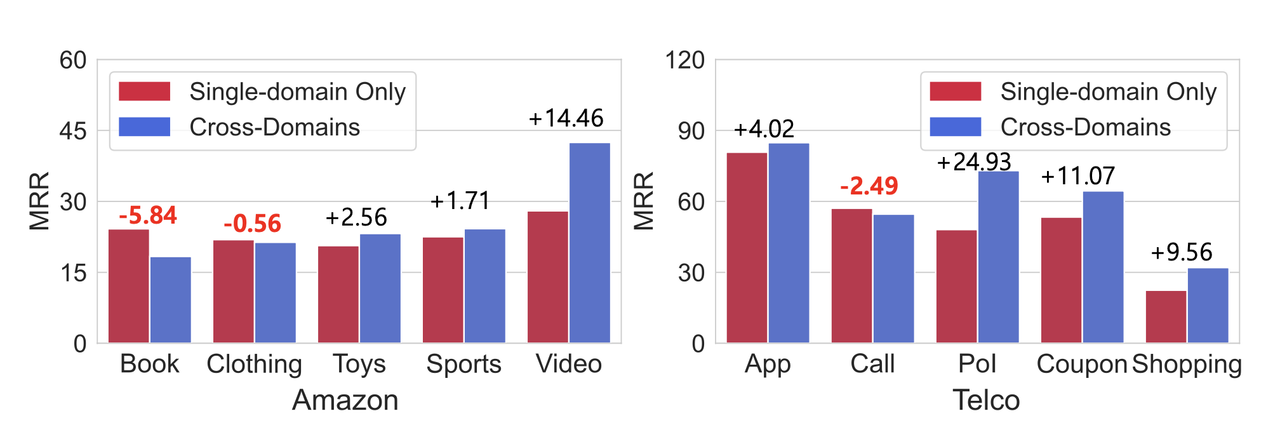
Figure 1은 Amazon 데이터셋의 Book, Clothing 도메인과 Telco 데이터셋의 Call 도메인에서 CDSR 접근법(다중 도메인으로 학습)이 SDSR 접근법(단일 도메인으로 학습)보다 성능이 낮은 것을 보여준다. 이는 다른 도메인으로부터의 부정적 전이를 나타낸다.
이 논문은 이러한 한계를 극복하고 모든 도메인에서 일관된 성능 향상을 달성할 수 있는 새로운 CDSR 프레임워크를 제안하고자 한다.
3. 방법
논문에서 제안하는 SyNCRec 모델은 다음과 같은 주요 구성 요소를 가진다:
저자는 SyNCRec(Asymmetric Cooperative Network for Cross-Domain Sequential Recommendation)이라는 새로운 CDSR 모델을 제안했다.
-
각 도메인별 부정적 전이 정도를 추정하고, 이를 예측 손실의 가중치로 적용하여 부정적 전이가 큰 도메인의 그래디언트 흐름을 제어한다.
-
비대칭 협력 네트워크를 통해 다중 도메인 시퀀스로 학습한 모델(CDSR)과 단일 도메인 시퀀스로만 학습한 모델(SDSR)의 성능을 비교하여 각 도메인의 부정적 전이를 평가한다.
-
SDSR과 CDSR 태스크 간 유용한 정보 전달을 촉진하기 위해, 도메인별로 두 태스크의 표현 쌍 간 상호 정보를 최대화하는 보조 손실을 개발했다.
3.1 Shared Embedding Layer
모든 도메인의 아이템에 대한 임베딩을 공유한다. 이는 도메인 간 지식 전이를 촉진하고 모델의 일반화 능력을 향상시킨다.
3.2 Asymmetric Cooperative Network with Mixture-of-Sequential Experts (ACMoE)
- MoE 아키텍처를 사용하여 SDSR과 CDSR 태스크를 동시에 수행하는 멀티태스크 학습 구조이다.
- Transformer 기반의 experts 네트워크들로 구성된다.
- Stop-gradient 연산을 통해 일부 experts는 SDSR에, 다른 experts는 CDSR에 특화되도록 한다.
- 이를 통해 두 태스크의 손실을 독립적으로 계산할 수 있어 부정적 전이를 정확히 평가할 수 있다.
ACMoE의 수학적 formulation은 다음과 같다:
$(Y_ d)_ {single} = h_ d(f_ d(E_ d))$
$f_ d(E_ d) = \sum_ {k=1}^j g_ d(E_ d)_ k SG(f^k_ {TRM}(E_ d)) + \sum_ {k=j+1}^K g_ d(E_ d)_ k f^k_ {TRM}(E_ d)$
여기서 $h_ d$는 도메인 d의 tower network, $f_ d$는 sequential expert layer의 mixture, SG는 stop-gradient 연산을 나타낸다.
3.3 Loss Correction with Negative Transfer Gap (LC-NTG)
- SDSR과 CDSR 태스크의 손실 차이를 이용해 각 도메인의 부정적 전이 정도(NTG)를 계산한다.
- 계산된 NTG를 CDSR 손실의 가중치로 사용하여 부정적 전이가 큰 도메인의 그래디언트 흐름을 줄인다.
부정적 전이 간격(NTG)은 다음과 같이 정의된다:
$\phi_\pi(d) = \sum_ {t=1}^T (l^d_ t - l_ t)$
여기서 $l^d_ t$와 $l_ t$는 각각 SDSR과 CDSR 태스크의 t 시점에서의 손실을 나타낸다.
3.4 Single-Cross Mutual Information Maximization (SC-MIM)
- SDSR과 CDSR 태스크에서 얻은 표현 간의 상호 정보를 최대화하는 보조 손실을 도입한다.
- 이를 통해 두 태스크 간 유용한 정보 전달을 촉진한다.
$L^d_ {SC-MIM} = \rho((Y_ d)_ {single}, (Y_ d)_ {cross}) - \log \sum_ {u^-} \exp(\rho((Y_ d)_ {single^-}, (Y_ d)_ {cross}))$
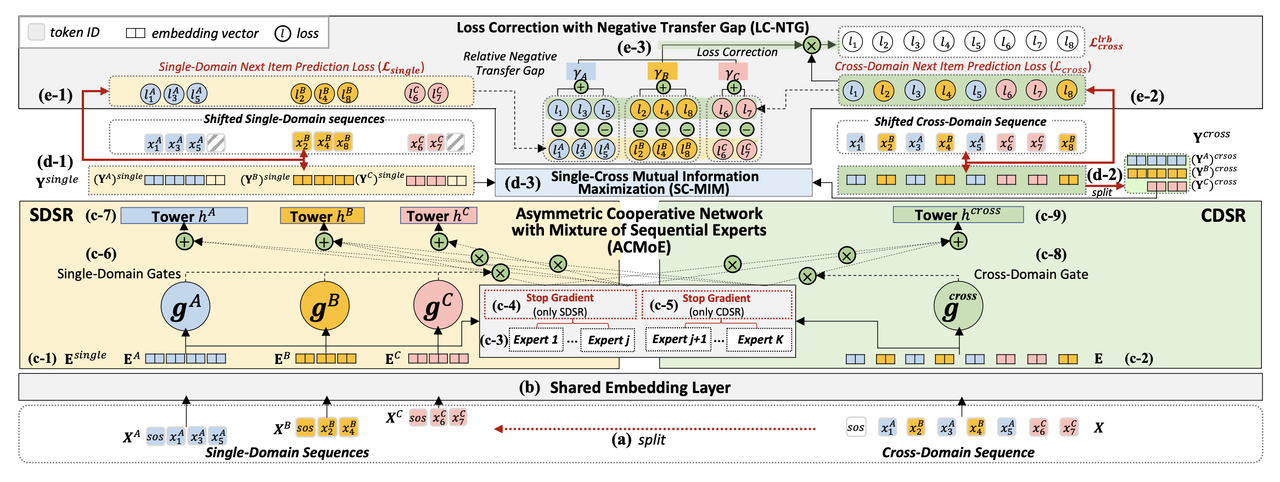
Figure 2는 SyNCRec의 전체 아키텍처를 보여준다. 이 모델은 SDSR과 CDSR 태스크를 동시에 학습하면서 부정적 전이를 최소화하고 도메인 간 지식 전이를 최적화한다.
4. 실험
실험은 다음 다섯 가지 연구 질문에 답하기 위해 설계되었다:
RQ1) 세 개 이상의 도메인을 포함하는 실제 응용에서 SyNCRec의 성능이 현재의 최신 기준 모델들을 능가하는가? RQ2) SyNCRec이 CDSR(Cross-Domain Sequential Recommendation) 작업에서 모든 도메인에 걸친 부정적 전이 문제를 효과적으로 해결할 수 있는가? RQ3) SyNCRec의 다양한 구성 요소들이 CDSR 작업에서의 성능에 어떤 영향을 미치는가? RQ4) 하이퍼파라미터 설정의 변화가 SyNCRec의 성능에 어떤 영향을 미치는가? RQ5) 모델을 온라인에 배포했을 때 어떤 성능을 보이는가?
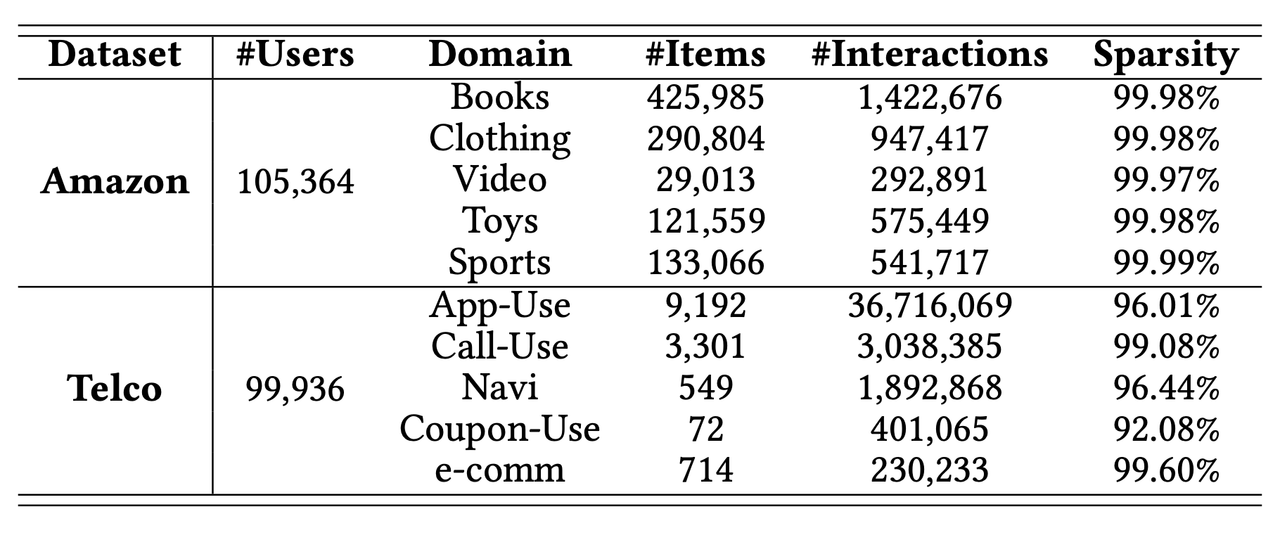
4.1 데이터셋 및 평가 지표
실험은 Amazon(5개 도메인)과 Telco(5개 도메인) 두 개의 실제 데이터셋에서 수행되었다. 평가 지표로는 HR, NDCG, MRR을 사용했다. 각 데이터셋의 통계는 다음과 같다:
4.2 베이스라인 모델
다양한 베이스라인 모델들(BPRMF, GCMC, SASRec, BERT4Rec, CAT-ART, CGRec 등)과 비교 실험을 진행했다.
- 일반 추천: BPRMF, GCMC
- 단일 도메인 순차적 추천(SDSR): GRU4Rec, SASRec, BERT4Rec 등
- 크로스 도메인 추천(CDR): BiTGCF, DTCDR, CMF 등
- 크로스 도메인 순차적 추천(CDSR): MIFN, 𝜋-net, MAN, C2DSR, CGRec 등
4.3 주요 결과
SyNCRec의 성능을 다른 베이스라인 모델들과 비교한 결과는 다음과 같다:
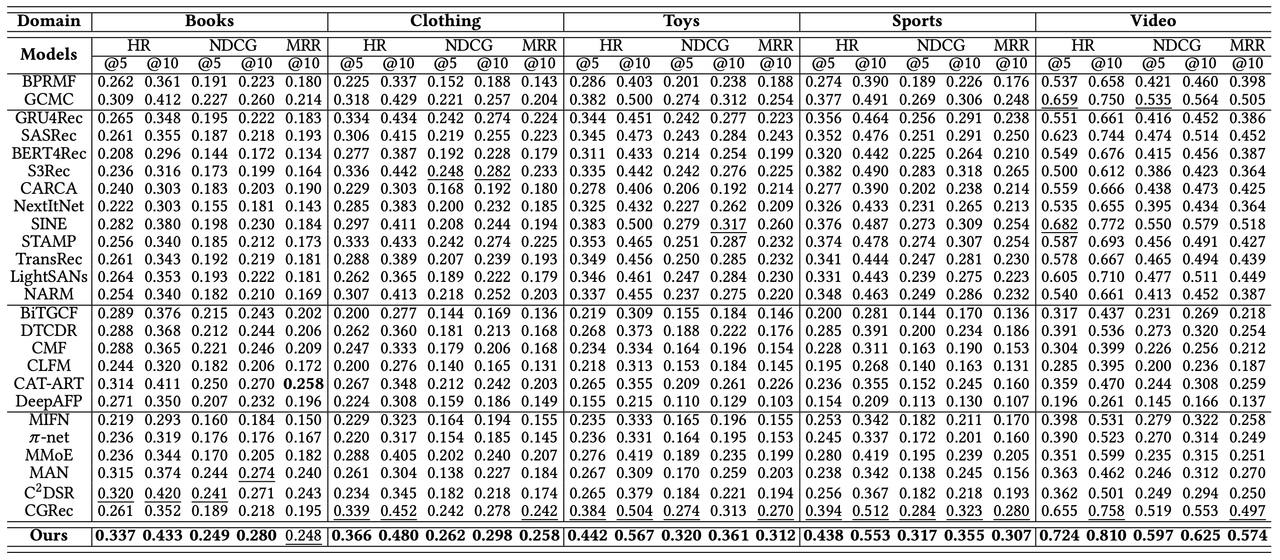
SyNCRec은 모든 도메인에서 가장 높은 HR@5 성능을 보여주었다.
- SyNCRec은 대부분의 도메인에서 최고의 성능을 달성했다. 예를 들어, Amazon 데이터셋의 Books 도메인에서 HR@5를 3.13% 향상시켰고, Telco 데이터셋의 Call-Use 도메인에서는 11.96% 향상시켰다.
- 특히 기존 모델들이 SDSR보다 성능이 떨어졌던 도메인들에서도 SyNCRec은 일관된 성능 향상을 보였다.
- 모델의 각 구성 요소를 제거한 실험에서 모든 구성 요소가 성능 향상에 기여함을 확인했다.
- LC-NTG, SC-MIM, ACMoE 각 컴포넌트를 제거한 변형 모델들과의 비교를 통해 각 요소의 중요성을 입증했다.
- 특히 ACMoE를 통한 SDSR/CDSR 태스크 분리가 정확한 부정적 전이 추정에 중요함을 확인했다.
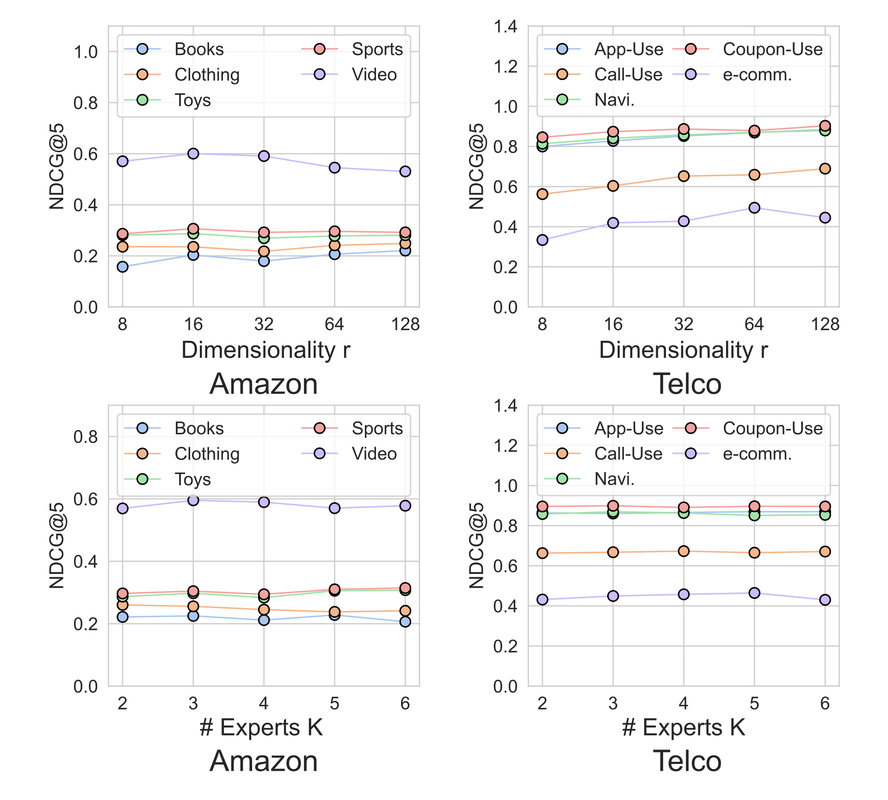
Figure 3은 SyNCRec과 주요 베이스라인 모델들의 성능을 비교한 그래프이다. SyNCRec이 대부분의 도메인에서 우수한 성능을 보이는 것을 확인할 수 있다. 실제 서비스에 SyNCRec을 적용한 결과, 기존 SASRec 기반 모델 대비 17.3%, 규칙 기반 모델 대비 25.6%의 CTR 향상을 달성했다.
5. 결론
이 논문은 CDSR에서의 부정적 전이 문제를 해결하기 위한 새로운 프레임워크 SyNCRec을 제안했다.
- 도메인별 부정적 전이를 동적으로 추정하고 이를 손실 함수에 반영한다.
- SDSR과 CDSR 태스크 간 정보 공유를 위한 보조 손실을 도입한다.
- 실제 데이터셋에서의 성능 검증 및 온라인 A/B 테스트를 통한 실용성을 입증했다.
향후 연구 방향으로는 더 다양한 도메인과 태스크에 대한 확장성 검증, 온라인 학습 시나리오로의 적용 등을 고려해볼 수 있을 것 같다. SyNCRec은 SDSR과 CDSR 태스크 간의 협력적 학습을 통해 모든 도메인에서 일관된 성능 향상을 달성했다. 실험 결과는 SyNCRec이 기존 방법들의 한계를 극복하고 실제 추천 시스템에서 유용하게 적용될 수 있음을 보여준다.
6. Critics
-
모델의 복잡성: SyNCRec은 여러 컴포넌트로 구성된 복잡한 모델로, 해석 가능성과 실제 시스템 적용 시 계산 비용 측면에서 단점이 될 수 있을 것 같다.
-
민감도: 모델의 성능이 여러 하이퍼파라미터(Sequential Expert Networks 수, 임베딩 차원 등)에 민감할 수 있다. 이에 대한 더 자세한 분석이 필요해 보인다.
-
확장성: 현재 실험은 5개 도메인으로 제한되어 있는데, 더 많은 도메인으로 확장 시 성능과 계산 효율성이 어떻게 변화하는지 추가 검증이 필요할 것으로 보인다.
-
장기 종속성: 현재 모델은 Transformer 기반 구조를 사용하고 있어 매우 긴 시퀀스에 대한 처리에 한계가 있을 수 있다. 이를 개선하기 위한 방안도 고려해보면 좋을 것으로 보인다.
6. 참고문헌
- Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Chenglin Li, Yuanzhen Xie, Chenyun Yu, Bo Hu, Zang Li, Guoqiang Shu, Xiaohu Qie, and Di Niu. 2023. One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 366–374.