[CIKM-21] Learning Dual Dynamic Representations on Time-Sliced User-Item Interaction Graphs for Sequential Recommendation
0. Author Information
Zeyuan Chen, Wei Zhang, Junchi Yan, Gang Wang, Jianyong Wang
1. Problem Definition
이 논문에서는 시퀀스 추천 문제를 다룹니다. 시퀀스 추천이란, 사용자가 과거에 상호작용했던 항목을 바탕으로 가까운 미래에 사용자가 상호작용할 가능성이 높은 항목을 추천하는 문제입니다. 전통적인 추천 시스템에서는 사용자-항목 간의 상호작용을 시간과 독립적으로모델링하지만, 시퀀스 추천은 시간에 따른 사용자 행동 패턴의 변화를 반영해야 합니다.
대부분의 기존 방식은 시간에 따른 user behavior, dynamics를 학습하고자 하였습니다. 하지만 이는 user-item interaction을 충분히 사용하지 않습니다. 이를 위해 이 논문은 사용자 뿐 아니라 item 측면에서도 시계열 상호작용을 고려하여 양방향의 동적인 표현을 학습하는 새로운 모델을 제안합니다. 따라서 해당 모델은 아래와 같이, user, item과 특정 시간 T에 대한 예측을 수행하는 함수를 잘 만드는 것을 목표로 합니다.
$ \hat{y}_{ui} = f(u, i, \mathcal{T}; \Theta)$
2. Motivation
대부분의 기존 연구는 사용자 측면에서의 변화에 초점을 맞추고 있기에, item의 변화를 간과하고 있습니다.
item의 인기도 변화를 고려하는 것이 보다 정교한 추천 결과를 도출할 수 있습니다. 예를 들어, 겨울이 다가옴에 따라 특정 겨울옷이 점점 더 많이 팔리게 되는 패턴을 포착하면 해당 item의 representation이 더욱 정확해지고, 이는 추천 성능 향상에 기여할 수 있습니다.
이러한 방식처럼 user와 item 양쪽 모두를 고려한 방법이 몇 개 존재합니다만, 이들 모두 user와 item 방향에서 개별적인 deep sequential model을 만드는 방식을 따른다. 예를 들어서 user별로 transition을 RNN을 학습하고 item에 대한 변화를 RNN을 통해 학습하여 잘 결합하는 등의 방법입니다. 하지만 이 방식은 user-item interaction의 상당 부분이 무시되거나 global perspective를 충분히 반영하지 못하며, 이 interaction이 명시적으로 모델링이 되지 않습니다.
Discriminated Idea
이 논문에서는 user-item 간 상호작용을 시간 단위로 분할하여 전반적인 시점에서 user and item represenation을 학습하는 시도를 했습니다. 각 시간 단위별로 global user-item interaction graph가 만들어지며 이를 통해 user와 Item represenation 학습에 향상을 유도합니다.
3. Related Work
3-1. Sequential Recommendation
Sequential Recommendation에서 해당 논문과 가장 관련이 있는 모델과의 차별점은 아래와 같습니다.
- RRN [39] - Recurrent Recommender Networks
- 구조적 차이점:
- RRN은 두 개의 RNN을 사용하여 사용자와 항목의 시간적 변화를 각각 독립적으로 학습합니다. 마지막 시간 단계의 출력 표현을 결합해 사용자의 선호도와 항목의 특징을 계산하여 상호작용 확률을 예측합니다.
- DRL-SRe는 사용자와 항목의 동적 표현을 전역적으로 학습하기 위해 시간 슬라이스 기반 그래프 신경망을 사용합니다. 사용자-항목 간의 모든 상호작용을 한꺼번에 고려하여 더 나은 동적 표현을 학습합니다.
- 차별점:
- RRN은 사용자와 항목의 시간적 변화를 각각 독립적으로 모델링하여 서로 간의 상호작용에 대한 정보를 충분히 공유하지 못합니다. 이는 사용자-항목 상호작용을 독립적으로 다루는 방식입니다. 반면 DRL-SRe는 시간 슬라이스 단위에서 사용자와 항목의 상호작용을 동시에 고려하여 더 풍부한 상호작용 정보를 학습할 수 있습니다.
- RRN은 단순한 결합을 통해 두 개의 시퀀스를 연결하는 반면, DRL-SRe는 전역적인 사용자-항목 상호작용을 그래프 구조를 통해 포착하여 더 높은 차원의 관계를 학습합니다.
2. DEEMS [41] - Dual Embedding Enhanced Memory Stream
- 구조적 차이점:
- DEEMS도 두 개의 RNN을 사용하여 user와 item의 표현을 학습하지만, 새로운 손실 함수를 적용하여 차별화된 접근을 시도합니다. DEEMS는 사용자 중심의 순차적 손실과 함께 item 중심의 정보 확산 손실을 도입하여 보다 풍부한 손실 함수를 구성했습니다.
- DRL-SRe는 RNN 대신 시간 슬라이스 그래프 구조를 도입하여 시간 구간별로 모든 user-item 상호작용을 포착하고, 이를 기반으로 전역적인 상호작용 표현을 학습합니다.
- 차별점:
- DEEMS는 손실 함수의 개선을 통해 두 시퀀스를 독립적으로 학습하는 방식의 한계를 일부 극복하려 했습니다. 하지만 여전히 user-item interaction을 직접적으로 결합하는 방식이 아니라, 독립적인 시퀀스를 따로따로 모델링한 후 손실 함수에서 보완하는 방식입니다.
- 반면 DRL-SRe는 두 시퀀스를 그래프 기반으로 동시에 학습하고, 시간적 변화를 반영하는 데에 중점을 둡니다. 시간 슬라이스 그래프는 모든 사용자-항목 상호작용을 한꺼번에 고려할 수 있기 때문에, RNN 기반 모델보다 더 나은 전역적 관계를 포착할 수 있습니다.
3. SCoRe [24] - Sequential Collaborative Representation Learning
- 구조적 차이점:
- SCoRe는 user-item 간의 과거 상호작용을 활용하여 표현을 학습합니다. 그러나 이 모델은 직접 이웃 노드(direct neighbors)에 대해서만 상호작용을 고려하며, 이는 대상 user-item pair와 직접적으로 연결된 노드들만 사용합니다.
- DRL-SRe는 시간 슬라이스 내에서 전역적인 user-item interaction을 활용하여 모든 상호작용을 고려하는 방식으로, 직접적인 이웃 관계에 국한되지 않고 고차원적인 상호작용까지 포착합니다.
- 차별점:
- SCoRe는 로컬(local)한 상호작용에 집중하여 상호작용 네트워크에서 직접 연결된 사용자와 항목 간의 관계만 고려하는 한계가 있습니다. 이는 전체적인 user-item 상호작용 정보를 충분히 반영하지 못할 수 있습니다.
- 반면 DRL-SRe는 한 시간 슬라이스 내의 모든 user-item 상호작용을 포괄적으로 다루어, 전체적인 상호작용 관계를 학습합니다. 이 방식은 상호작용 네트워크 내의 고차원적 관계를 더 잘 반영하여 더 나은 추천 성능을 발휘할 수 있습니다.
4. 연속 시간 기반 모델들 [2, 16, 18] - Continuous-Time Models
- 차이점:
- [2, 16, 18]에서는 user-item representation을 연속 시간(continuous time)에서 학습하지만, 이 방식은 다음 interaction 시간이 미리 알려져 있어야만 유효합니다. 또한, 과거 상호작용을 한 번만 모델링하므로 반복적인 전파를 통한 고차원적 관계를 포착하기 어렵습니다.
- DRL-SRe는 시간 슬라이스 내에서 모든 상호작용을 반복적으로 전파하여 더 정교한 관계를 학습할 수 있으며, 다음 상호작용 시간을 미리 알 필요 없이 시간 구간 내의 상호작용을 포괄적으로 학습합니다.
- 차별점:
- 연속 시간 모델들은 각 사용자-항목 상호작용을 한 번만 모델링하기 때문에 반복적인 상호작용을 충분히 포착하지 못하고, 또한 다음 상호작용 시간이 필요하기 때문에 그 정보가 없는 경우 모델의 성능이 저하될 수 있습니다.
- 반면 DRL-SRe는 시간 구간별로 상호작용을 쪼개어 학습하고, 반복적인 전파를 통해 더 높은 차원의 관계를 학습할 수 있습니다. 또한, 시간 예측 작업을 통해 상호작용 시간 정보가 주어지지 않더라도 모델 성능을 유지할 수 있습니다.
3-2. GNN
GNN은 최근 짧은 sequence를 가지는 session recommendation이라는 분야에 주로 사용되고 있지만, 근본적으로는 user-item interaction을 모델링하는 기법으로써, user-item interaction에 초점을 맞추어 sequential recommendation을 하는 경우는 드뭅니다.
- GLS-GRL 은 사용자 그룹을 대상으로 아이템을 추천하는 반면, DRL-SRe는 개별 사용자와 아이템 간의 상호작용을 학습하여 개별 사용자를 위한 추천을 수행합니다.
- 연구 [22, 28, 40]은 동적 그래프 신경망을 다루고 있지만, 순차 추천을 위한 연구는 아니며, DRL-SRe는 이를 순차 추천에 적용한 첫 사례입니다.
3-3. Temporal Point Process
Temporal Point Process는 비동기적인 시간 간격을 다룰 수 있는 수학적 도구로, 기존 연구들은 상호작용 예측과 시간 예측을 동시에 수행하는 방식으로 이를 사용해왔습니다. 하지만 이 논문은 time-slice 방식에서 발생할 수 있는 시간 정보 손실을 보완하기 위해 과거 연속된 시간 슬라이스에서의 시간 예측을 사용합니다. 즉, time-slice를 하게 되면 이산적인 시간을 다룰 수 밖에 없는데, TPP를 이용하여 해당 구간 안에서 언제 interaction이 일어나는지 예측하고자 하는 것이 목적입니다. 이를 통해 시간적으로 더 세밀한 패턴을 포착하고 추천 성능을 향상시키려는 목적입니다.
4. Method
제안된 모델은 DRL-SRe (Dual Representation Learning Sequential Recommendation)입니다. 이 모델은 시간 단위로 잘린 사용자-항목 상호작용 그래프를 생성하고, 각 시간 단위에서 사용자와 항목의 표현을 학습합니다.
- time-sliced interaction 그래프: 전체 타임라인을 일정한 간격으로 나누고, 각 시간 구간에서 발생한 사용자-항목 상호작용을 그래프로 표현합니다. 이 그래프에서 노드는 사용자와 항목, 그리고 엣지는 상호작용을 의미합니다.
- time-slice 그래프 신경망: 각 시간 슬라이스에서 그래프 신경망을 통해 사용자와 항목의 표현을 학습한 뒤, 이러한 시간별 표현을 RNN(순환 신경망)을 사용해 time-slice 간의 관련성을 모델링합니다.
- auxiliary temporal prediction: time-sliced 데이터에서 발생하는 정보 손실을 보완하기 위해 연속된 시간 슬라이스 간의 시간 정보를 모델링하는 보조 작업을 추가했습니다. 이 작업은 Temporal Point Process을 활용해 특정 시간 구간에서 다음 상호작용이 일어날 가능성을 예측합니다. 즉 다음 상호 작용이 어느 시점에 발생할지를 예측하는 시간 예측 작업입니다.
예시:
- 사용자 u1가 시간 슬라이스 t1에서는 항목 i1과 상호작용하고, t2에서는 i2와 상호작용했다고 가정합니다.
- 각각의 시간 슬라이스에서 사용자와 항목은 그래프 노드로 표현되고, 그래프 신경망을 통해 각 시간에서의 동적 표현이 학습됩니다.
- 이러한 시간 슬라이스 표현을 GRU를 통해 시간적으로 연결하여 사용자의 전체 상호작용 시퀀스를 학습합니다.
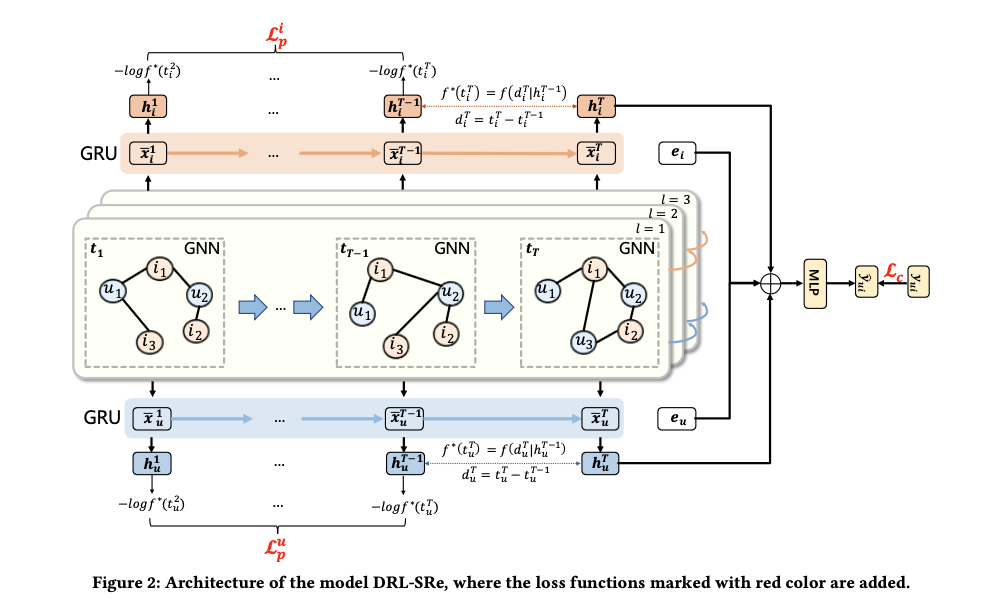
Model Construction
먼저 graph neural network에서 Adjacent matrix를 사용하여 propagation을 하듯, user와 item 모두에 대해 l-layer embedding을 도출해냅니다.
$ \mathbf{X}_{l+1}^s = \hat{\mathbf{A}}^s \mathbf{X}_l^s $
이후 이 layer 간의 표현을 GRU를 통해 학습합니다.
$ \bar{\mathbf{X}}^s_ {U} = \text{GRU}(\tilde{\mathbf{X}}^s_ {U}; \Theta_U^{1}) \Big\vert_ {L+1}, \quad \bar{\mathbf{X}}^{s}_ {I} = \text{GRU}(\tilde{\mathbf{X}}^{s} _{I}; \Theta_I^{1}) \Big\vert _ {L+1} $
이렇게 layer 간의 표현을 학습하게 되면, 하나의 time-slice에서 user와 item에 대한 representation이 도출되게 됩니다. 이후 여러 time-slice에 대해서 GRU를 적용하여 최종 representaion을 도출합니다.
$ \mathbf{H}_ {U} = \text{GRU}(\tilde{\mathbf{X}}_U; \Theta_U^{2}), \quad \mathbf{H}_I = \text{GRU}(\tilde{\mathbf{X}}_I; \Theta_I^{2}) $
마지막으로 예측 단계에서는 모든 모델을 통해 나온 표현과, 최초 embedding들을 모두 MLP에 통과시켜 예측합니다.
$ \hat{y}_{ui} = \sigma(\text{MLPs}(\mathbf{h}_u^T \oplus \mathbf{h}_i^T \oplus \mathbf{e}_u \oplus \mathbf{e}_i; \Theta^{\text{MLP}})) $
Loss function으로써는 binary classification 문제로써의 loss를 사용합니다.
$ \mathcal{L}_ {c} = - \left( y_ {ui} \log \hat{y}_ {ui} + (1 - y_ {ui}) \log(1 - \hat{y}_ {ui}) \right) $
Temporal Point Process
Time-slice로 인해 시간 정보가 손실되는 것을 막기 위헤 TPP 기법을 사용합니다.
여기서 확률 밀도 함수는 다음과 같이 정의 됩니다.
$ f^{*}(t) = \lambda^{*}(t) \exp\left( - \int_{t_j}^{t} \lambda^{*}(\epsilon) d\epsilon \right) $
위의 식은 특정 시간에 대한 intensity function를 상정하고, 해당 event가 발생한 이후 exponential하게 감소하는 형태입니다. 이를 통해 특정 이벤트가 발생한 이후, 지속적으로 이벤트 발생 확률이 감소하는 식으로 모델링할 수 있습니다.
[6]에서 연구된 디자인을 참고하여 intensity function을 user와 item에 대해 각각 다음과 같이 정의합니다.
$ \lambda^{*}_u(t) = \exp\left( \mathbf{w}_U \mathbf{h}^s_u + \omega_U (t - t^s_u) + b_U \right), $
$ \lambda^{*}_i(t) = \exp\left( \mathbf{w}_I \mathbf{h}^s_i + \omega_I (t - t^s_i) + b_I \right) $
이를 확률 밀도 함수 식에 대입하게 되면 아래와 같은 형태가 나오게 됩니다.
$ \begin{array}{l}
f^{*}_{u}(t) = \exp\lbrace\mathbf{w}_U \mathbf{h}^s_u+\omega_U(t-t^s_u)+b_U+\frac{1}{\omega_U}\exp(\mathbf{w_U}\mathbf{h}^s_u + b_U)
-\frac{1}{\omega_U}\exp(\mathbf{w}_U \mathbf{h}^s_u+\omega_U(t-t^s_u)+b_U)\rbrace\,.
\end{array} $
최종적인 Loss function은 negative log likelihood 형식으로, 각 항에는 userd와 item에 대한 representation이 포함되어있으므로, representation에 시간에 대한 정보가 좀 더 잘 반영되게 됩니다. 특히 정의한 확률 밀도 함수의 likelihood를 높이는 방향으로 학습이 진행되게 됩니다.
$ \mathcal{L}_ {p} = - \sum_ {s=1}^{T-1} \log f^{*}_ {u}(t_ {u}^{s+1} \vert \mathbf{h}_ {u}^s) - \sum_ {s=1}^{T-1} \log f^{*}_ {i}(t_ {i}^{s+1} \vert \mathbf{h}_ {i}^s) $
최종적인 학습은 Model과 TPP 모두를 활용한 loss function으로 구성됩니다.
$ \mathcal{L} = \mathcal{L}_c + \beta \mathcal{L}_p $
4. Experiment
Experiment setup
- Dataset: Amazon Baby, Yelp, Netflix 세 가지 공개 데이터셋을 사용하였습니다. 각 데이터셋의 사용자와 항목 수, 상호작용 수 및 시간 구간은 다릅니다.
- Baseline: GRU4Rec, SASRec, SCoRe 등 다양한 최신 시퀀스 추천 모델과 성능을 비교했습니다.
- Evaluation Metric: HR@k, NDCG@k, MRR을 사용해 추천 성능을 평가하였습니다.
Result
- DRL-SRe는 모든 데이터셋에서 다른 최신 모델들보다 월등히 높은 성능을 보였습니다.

- Baby 데이터셋에서 NDCG@10 기준으로 3.39% 향상, Yelp에서는 10.22%, Netflix에서는 9.62% 향상을 보였습니다.
Ablation Study

- Graph, RNN, 보조 시간 예측 작업에 대한 기여도가 크게 나타났고, 각 요소가 중요한 component임을 확인할 수 있습니다.
Replacement Study

- Global Graph : time-sliced된 graph를 사용하지 않고, time-slice를 늘려 하나의 graph를 사용하는 방식입니다.
- historical graph를 사용하지 않고, 마지막 graph만을 사용한 방식입니다.
- user slices, item slices: Dual 뷰로 보지 않고, user 또는 Item의 transition을 보았을 때의 결과입니다.
- GNN에서 각 layer에서 도출된 표현에 대해 처리를 할 때, 어떻게 할지 네 가지 대체 방식 1) concat, 2) last-layer output 3) mean-pooling 4) single GRU 에 대해 실험을 진행하였습니다.
5. Conclusion
Sequential Recommendation에서 사용자와 항목 양쪽의 시간적 패턴을 모두 반영하는 새로운 방법론을 제시했습니다. time-sliced 그래프 신경망과 Temporal Point Process 기반의 보조 시간 예측 작업을 통해 보다 정교한 사용자와 항목의 동적 표현을 학습할 수 있었습니다. 실험 결과는 이 모델이 기존의 최신 모델들에 비해 더 나은 성능을 보여주었음을 입증했습니다.