[CIKM-2024] Learnable Item Tokenization for Generative Recommendation
Wang, W., Bao, H., Lin, X., Zhang, J., Li, Y., Feng, F., Ng, S., & Chua, T. (2024). Learnable Item Tokenization for Generative Recommendation. In Proceedings of the 33rd ACM international conference on information and knowledge management
1. Introduction
1.1 Motivation
최근 대형 언어 모델(Large Language Model, LLM)의 등장과 함께, 모든 후보군에 대한 추천 확률을 추정하는 전통적인 방법과 달리 대형 언어 모델을 활용하여 추천할 아이템의 ID를 직접적으로 생성하는 생성형 추천 시스템(Generative Recommendation System)이 제시되었다. 생성형 추천 시스템을 활용할 때 중요한 요소는 아이템 토큰화(Item Tokenization)로, 각 아이템에 식별자(Identifier)를 부여하는 것이다. 아이템 토큰화는 대형 언어 모델의 표현 공간과 추천 데이터 간의 간극을 좁히는 것을 목적으로 하며, 크게 세 가지 방법으로 나눌 수 있다.
- ID identifier
- Textual Identifier
- Codebook-based Identifier
ID Identifier은 각 아이템에 고유한 숫자를 부여하는 방식으로, 이를 통해 각 아이템의 식별자가 중복되지 않도록 한다. 하지만 숫자가 특별한 의미를 가지는 것이 아니므로 아이템에 대한 정보를 반영할 수 없고, 이에 따라 등장이 적은 아이템, 이른바 cold-start item 추천이 어렵다는 단점이 있다.
Textual Identifier은 아이템의 이름, 특징, 설명 등 아이템에 대한 정보를 아이템의 식별자로 사용하는 방식이다. 이를 통해 cold-start problem에 대응하기 용이하다는 장점이 있다. 하지만 이 방식 역시 몇 가지 단점이 있다. 첫째로, 식별자 상에서 정보가 배열된 순서가 의미 없고 불규칙적이다. 이로 인해 중요하지 않은 단어가 포함되어 있거나, 단어의 배열이 그 단어의 중요도와 관계없는 경우 텍스트를 식별자로 사용하는 것이 추천할 아이템을 생성하는 데에 부정적인 영향을 준다. 예를 들어, 영화의 제목이 “With“나 “Be“처럼 사용자의 선호도와 무관한 단어로 시작하는 경우 이러한 아이템을 생성할 확률이 낮아진다. 또한 이 방식은 사용자의 행동에 따른 경향성, 즉 collaborative signal을 반영하지 못한다는 단점이 있다. 이로 인해 문자 상의 의미가 비슷하지만 사용자의 선호도가 다른 아이템이 존재할 시 추천의 성능이 떨어진다.
Codebook-based Identifier은 각 아이템에 hierarchical code sequence를 부여하는 방식으로, 이를 통해 아이템의 토큰이 넓은 의미에서부터 좁은 의미를 담도록 한다. 이러한 방식을 활용하여 textual identifier의 단점을 보완할 수 있으나, collaborative signal을 반영하지 못한다는 한계점이 존재한다. 또한, 코드의 분포가 데이터 상에서 편향되어있어 모델이 이러한 편향을 학습하고, 이로 인해 생성된 코드의 분포가 더욱 편향되는 문제가 존재한다. 실제로 이러한 양상을 다음과 같이 실험적으로 확인할 수 있다.
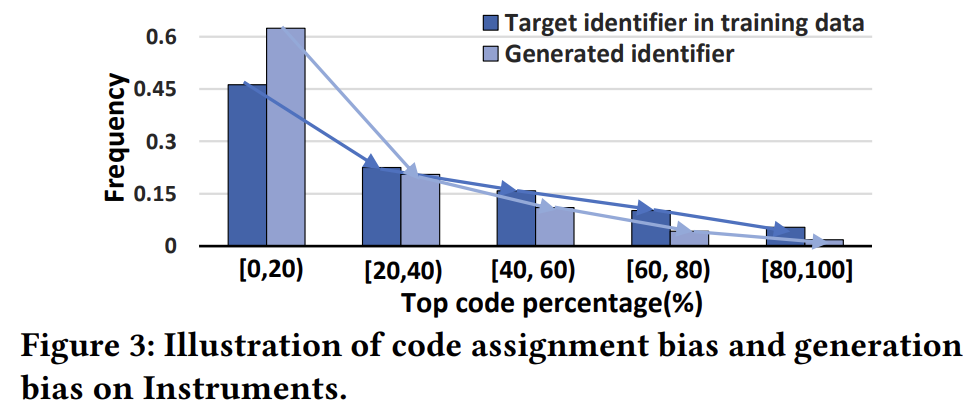
따라서 본 논문은 이상적인 식별자의 조건을 다음과 같이 제시한다.
- 계층적인 의미를 반영하여 토큰이 넓은 의미부터 좁은 의미 순으로 표현하도록 한다.
- Collaborative signal을 반영하여 선호 양상이 비슷한 아이템들에 비슷한 토큰을 부여한다.
- 토큰 부여 시 다양성을 높여 편향으로 인한 문제를 완화한다.
1.2 Preliminary: Codebook-based Identifier
Codebook-based Identifier은 기존의 ID Identifier이나 Text Identifier의 단점을 보완하고자 제시된 개념으로, Residual-Quantized Variational AutoEncoder(RQ-VAE)를 활용하여 각 아이템에 고정된 길이의 튜플을 배정하는 방식이다.
가장 기본적인 Codebook-based Identifier의 구조는 다음과 같다. [1]
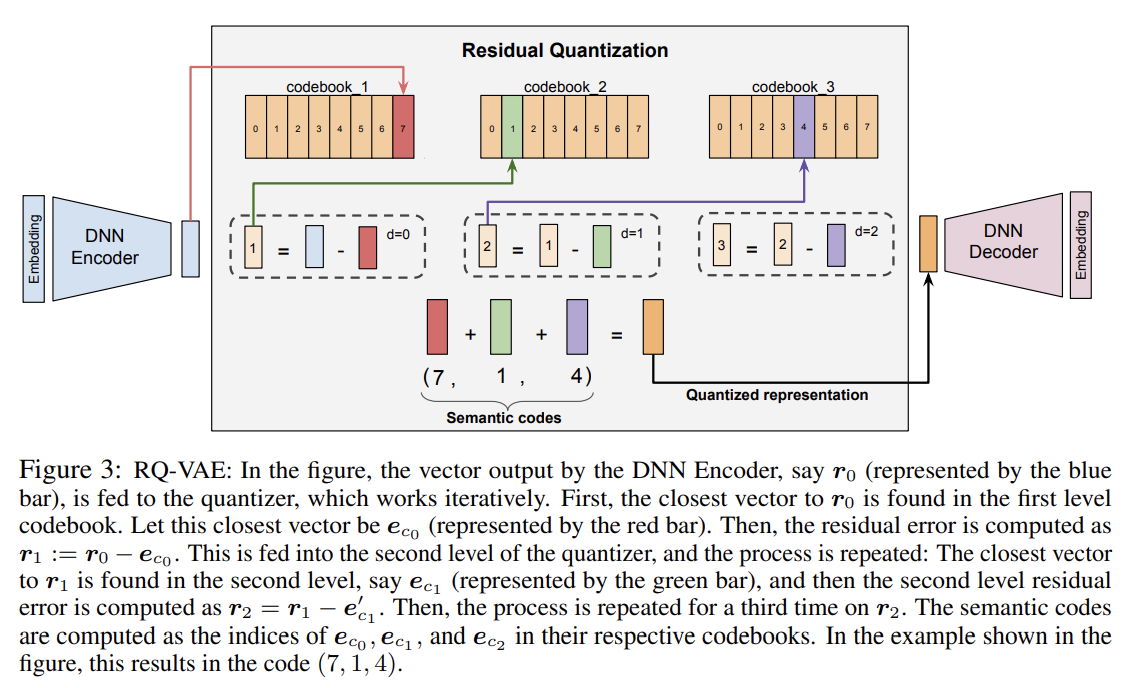
우선 아이템에 대한 텍스트를 Sentence-T5나 BERT같은 general-purpose pre-trained text-encoder에 통과시켜 각 아이템에 대한 임베딩을 얻는다. 이 텍스트 임베딩을 오토인코더의 입력값으로 하여 잠재 표현(latent representation)을 얻는다. 이렇게 얻은 임베딩과 첫 레벨의 코드북 임베딩을 비교하여 가장 가까운 벡터를 선정한다. 이 벡터에 대응되는 숫자가 첫번째 레벨의 코드가 된다.
이후 임베딩에서 첫번째 코드 벡터를 뺀 값을 다음 레벨의 입력값으로 넘긴다. 다음 레벨에서도 마찬가지로 가장 가까운 벡터를 선정하여 코드를 결정하고, 입력값에서 이 벡터를 뺀 값을 다음 레벨로 넘긴다. 이 과정을 반복하여 각 레벨에서의 코드와 대응되는 벡터를 얻는다. 이러한 재귀적인 구조로 아이템에 배정된 코드는 넓은 의미에서부터 좁은 의미에 해당하게 된다. 이를 통해 상위 레벨의 코드가 동일한 아이템은 하위 레벨의 코드가 동일한 아이템보다 더 유사하다. 예를 들어, (7, 1, 4)의 코드를 배정받은 아이템은 (6, 1, 4)의 코드를 배정받은 아이템보다 (7, 4, 0)의 코드를 배정받은 아이템과 더 유사하다.
이 과정을 거친 후 아이템의 quantized representation은 각 레벨에서 배정된 벡터들의 합으로 표현된다. 이러한 quantized representation은 디코더를 통과하여 최초 입력값을 재건하도록 학습된다. 이 전체 과정은 디코더를 통해 얻은 값과 인코더 간의 차이에 대한 reconstruction loss와 각 레벨에서의 입력값과 배정된 벡터 간의 차이에 대한 RQ-VAE loss로 학습된다. 이를 수식으로 표현하면 다음과 같다.
$\mathcal{L}(x) := \mathcal{L}_ {Recon} + \mathcal{L}_ {RQ-VAE}$
$\mathcal{L}_{Recon} := \vert\vert x - \hat{x} \vert\vert ^2$
$\mathcal{L}_ {RQ-VAE} := \sum_ {d=0}^{m-1} \vert\vert sg[r_ i]-e_ {c_ i}\vert\vert^2 + \beta \vert\vert r_ i-sg[e_ {c_ i}]\vert\vert^2$
이때 sg는 stop gradient operation을 의미한다.
이러한 Codebook-based Identifier은 기존의 ID Identifier이나 Text Identifier의 문제로 지적되었던 계층적 의미를 반영하지 못한다는 점을 효과적으로 해결하였고, 이를 바탕으로 더욱 효율적인 생성형 추천을 가능하도록 하였다. 하지만, 본 논문에서 지적하듯 이렇게 생성된 식별자는 코드 분포가 균일하지 않으며, 사용자의 선호도를 전혀 반영하지 못한다는 단점이 있다.
1.3 LETTER: LEarnable Tokenizer for generaTivE Recommendation
본 논문은 Codebook-based Identifier의 문제점을 보완하고자 두 가지 Regularization를 도입하였다.
- Collaborative Regularization: RQ-VAE를 통해 학습한 quantized embedding과 잘 학습된 Collaborative Filtering(CF) 모델을 통해 얻은 CF embedding 간의 contrastive alignment loss를 도입하여 생성된 식별자가 사용자의 선호도를 반영할 수 있도록 한다.
- Diversity Regularization: diversity loss를 도입하여 코드 임베딩의 다양성을 높이고, 이를 통해 편향 문제를 해결한다.
2. Method
모델의 전반적인 구조는 다음과 같다.
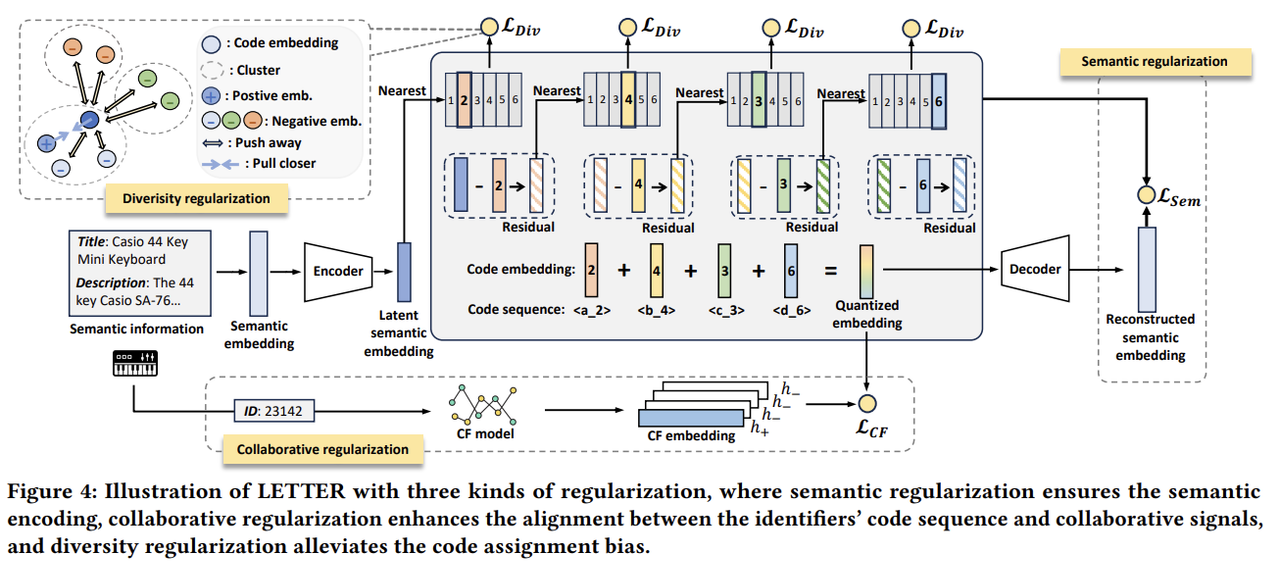
2.1 Semantic Regularization
본 논문은 pre-trained text encoder로 LLaMA-7B를 사용하였다. 식별자 배정과 오토인코더 학습 과정은 앞서 설명한 [1]과 동일하다.
2.2 Collaborative Regularization
본 논문은 식별자에 collaborative signal을 반영하기 위해 quantized embedding과 CF embedding을 contrastive learning을 통해 맞추는 collaborative regularization을 도입하였다. 잘 학습된 추천 모델(SASRec, LightGCN)을 활용하여 CF embedding을 구하고, 다음과 같은 contrastive loss를 활용한다.
$\mathcal{L}_ {CF} = -{1 \over B} \sum_ {i=1}^{B} {exp(< \hat{z_ i}, h_ i >) \over \sum^B_ {j=1} exp(< \hat{z_ i}, h_ j >) }$
이를 통해 기존 방법과는 달리 생성된 식별자가 사용자들의 선호도를 반영한다.
2.3 Diversity Regularization
본 논문은 코드 생성 편향 문제를 해결하기 위해 코드 임베딩이 더욱 다양하도록 하는 ‘diversity regularization*을 도입하였다. 다음 그림에서 볼 수 있듯, 코드 임베딩의 분포가 편향되면 코드 배정 역시 편향된다. 반대로, 코드 임베딩의 분포가 균일하면 코드 배정 역시 균등하다. 따라서 코드 임베딩의 분포를 균일하게 하여 코드 생성 편향 문제를 해결하고자 한다.
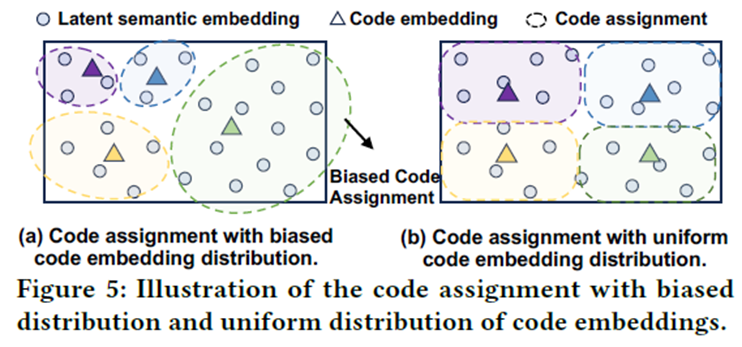
각 레벨의 코드북에 대해, 코드 임베딩을 constrained K-means clustering을 활용하여 K개의 그룹으로 나눈다. 이후 같은 클러스터에 속한 임베딩끼리는 가깝게 하고, 다른 클러스터에 속한 임베딩은 멀게 하도록 다음과 같은 loss를 사용한다.
$\mathcal{L}_ {Div} = -{1 \over B} \sum_ {i=1}^{B} {exp(< e^i_ {Cl}, e_ + >) \over \sum^{N-1}_ {j=1} exp(< e^i_ {Cl}, e_ j >) }$
이때 e+는 같은 클러스터에서 임의로 뽑은 코드 임베딩이고, eiCl 은 아이템 i와 가장 가까운 코드 임베딩이다.
2.4 Overall Loss
LETTER의 training loss는 다음과 같은 가중합으로 나타난다.
$\mathcal{L}_ {LETTER} = \mathcal{L}_ {Recon} + \mathcal{L}_ {RQ-VAE} + \alpha \mathcal{L}_ {CF} + \beta \mathcal{L}_ {Div}$
2.5 Instantiation
LETTER을 대형 언어 모델 기반 생성형 추천 모델에 활용할 때 다음과 같은 과정을 거친다. 우선, 토큰화 모델을 2.4의 loss로 먼저 학습한다. 이후 학습된 모델을 바탕으로 아이템을 토큰화하고, 이를 대형 언어 모델의 학습에 사용한다.
기존의 대형 언어 모델 기반 생성형 추천 모델은 generation loss를 활용하여 대형 언어 모델을 학습하였다. 하지만 이러한 방식은 추천 시스템에 적합하지 않으며, 따라서 본 논문은 다음과 같은 ranking-guided generation loss를 도입하였다.
$\mathcal{L}_ {rank} = - \sum_ {t=1}^{\vert y \vert} log P_ {\theta}(y_ t \vert y_ {<t}, x)$
$P_ {\theta}(y_ t \vert y_ {<t}, x) = {exp(p(y_ t)/\tau) \over \sum_ {v \in V} exp(p(v)/\tau)}$
3. Experiments
본 논문은 다음과 같이 3가지 Research Question을 제시하며, 이에 답하기 위해 3가지 real-world 데이터셋을 활용한 실험 결과를 제시한다.
- RQ1: 본 논문의 LETTER가 다른 식별자들에 비해 어떠한 추천 성능을 보이는가?
- RQ2: LETTER의 각 요소가 성능에 어떠한 영향을 끼치는가?
- RQ3: 다양한 상황에서 LETTER의 성능이 어떻게 달라지는가?
3.1 Experimental Settings
본 논문은 다음과 같이 3가지 데이터셋에 대해 실험을 진행하였다.
- Instruments: Amazon review dataset으로부터 얻은 악기 구매 데이터
- Beauty: Amazon review dataset으로부터 얻은 화장품 구매 데이터
- Yelp: Yelp 플랫폼에서 이루어진 business interaction 데이터
본 논문에서 사용한 Baseline들은 다음과 같다.
- 전통적인 추천 시스템 방법론: MF, Caser, HGN, BERT4Rec, LightGCN, SASRec
- 텍스트 기반 생성형 추천 시스템: BIGRec
- ID 기반 생성형 추천 시스템: P5-TID, P5-SemID, P5-CID
- Codebook 기반 생성형 추천 시스템: TIGER[1], LC-Rec
본 논문에서는 TIGER과 LC-Rec에서 사용한 대형 언어 모델 기반 추천 모델을 backbone으로 사용하였다. Collaborative Regularization에서는 선행학습된 추천 모델로 SASRec을 사용하였다.
3.2 Overall Performance (RQ1)
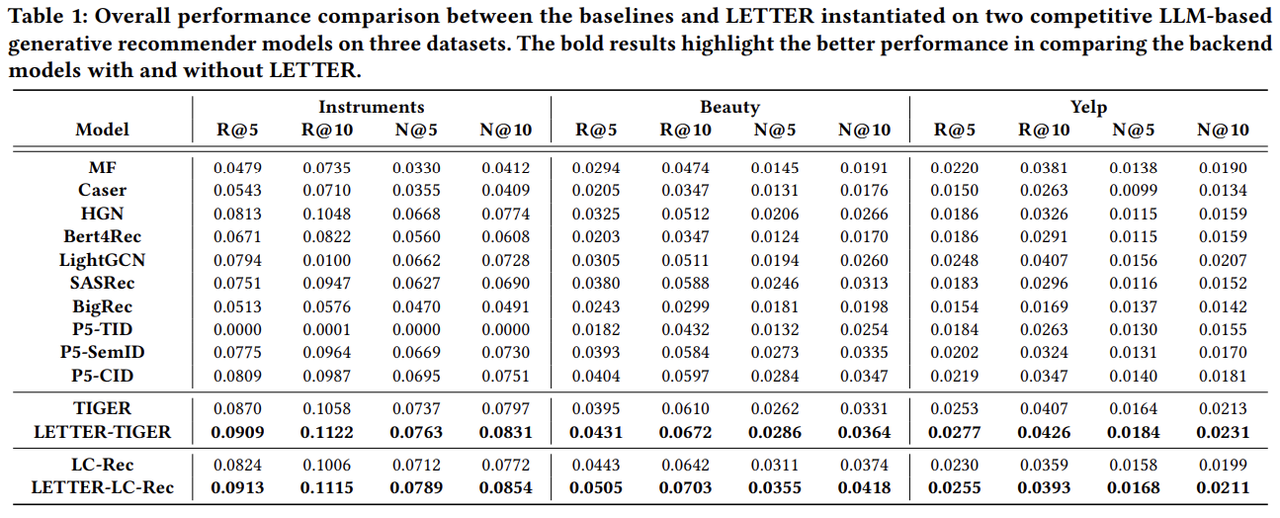
- 전반적으로 코드북 기반 방법들이 ID, 텍스트 식별자를 사용하는 방법들보다 높은 성능을 기록하는데, 이는 계층적인 의미를 더 효과적으로 전달할 수 있기 때문이다.
- 본 논문에서 제시한 LETTER을 사용할 시 backbone 모델만 사용하는 것보다 성능이 향상됨을 확인할 수 있다. LETTER가 기존의 코드 편향 문제 및 선호도 반영 문제를 성공적으로 해결했다고 해석할 수 있다.
3.3 Ablation Study (RQ2)
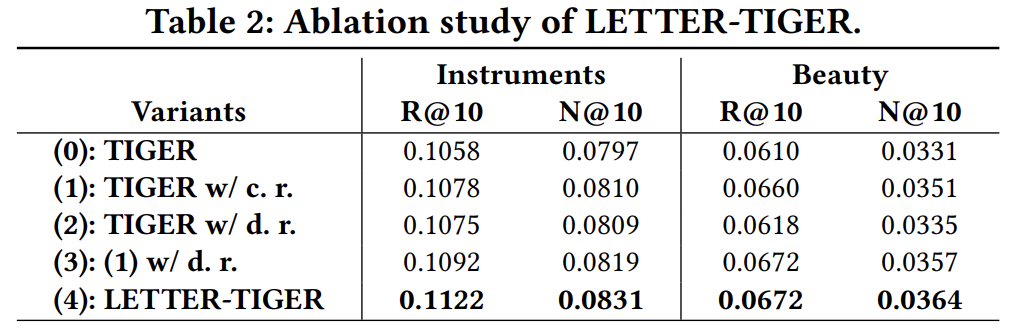
위 표는 backbone 모델인 TIGER에 LETTER의 각 요소를 추가한 결과이다. 이때 c.r. 과 d.r. 은 각각 collaborative regularization과 diversity regularization을 의미한다. 위 실험을 통해 각 요소들이 성능 향상에 모두 기여함을 확인할 수 있다.
3.4 Code Assignment Distribution and Code Embedding Distribution (RQ2)

위 그림은 첫번째 코드북의 코드 분포를 나타낸다. 진한 색으로 표시된 그래프가 diversity regularization을 포함한 모델이고, 연한 색으로 표시된 그래프가 diversity regularization을 포함하지 않은 모델에 해당한다. diversity regularization을 도입했을 때 도입하지 않은 것보다 코드 분포의 편향성이 덜하고, 더 많은 코드가 이용됨을 확인할 수 있다.
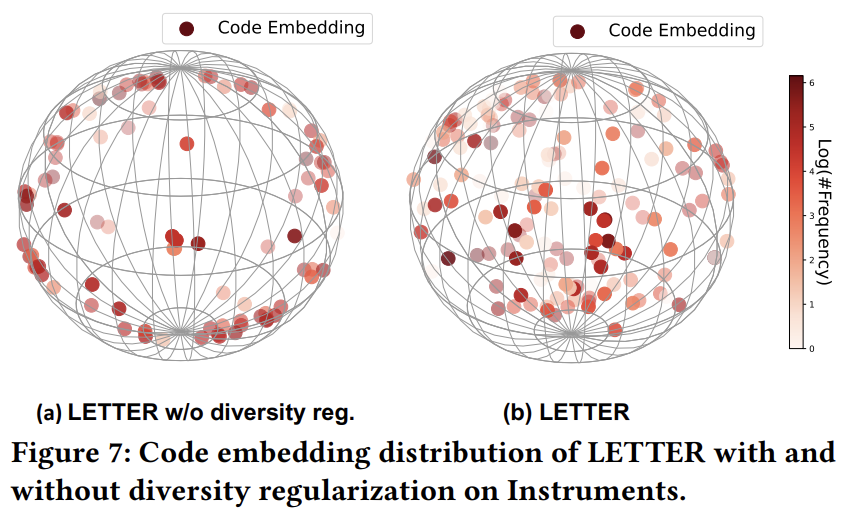
위 그림은 첫번째 코드북에 해당하는 코드 임베딩의 분포를 나타낸 것으로, 왼쪽 그림이 diversity regularization을 도입하지 않은 모델, 오른쪽 그림이 diversity regularization을 도입한 모델에 해당한다. 이때 오른쪽 그림에서 코드 임베딩이 더욱 고르게 분포되어있음을 확인할 수 있다.
3.5 Investigation on Collaborative Signals in Identifiers (RQ2)
본 논문이 제시한 방법이 실제로 collaborative signal을 잘 반영하는지 확인하고자 다음과 같은 두 실험을 진행하였다.
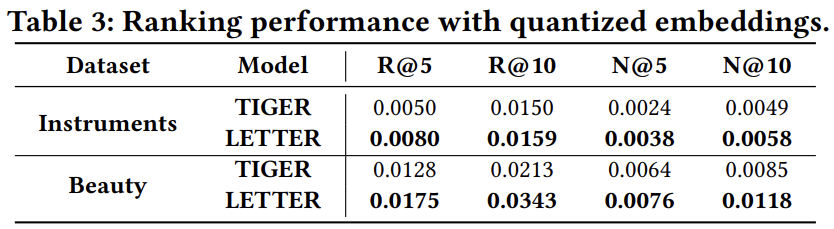
위 실험 결과는 LETTER의 아이템 임베딩을 활용한 ranking 성능을 확인한 것으로, 이미 학습된 기존의 CF 모델(SASRec)의 아이템 임베딩을 각각 TIGER과 LETTER의 quantized embedding으로 대체했을 때의 성능이다. TIGER의 임베딩을 사용했을 때보다 LETTER의 임베딩을 사용했을 때의 성능이 높은 것으로, LETTER의 임베딩이 사용자의 선호도를 잘 반영함을 확인할 수 있다.

위 실험 결과는 사용자 선호 양상이 비슷한 아이템 간의 코드의 유사도를 확인한 것으로, 사전학습된 CF 임베딩을 활용하여 각 아이템 별로 가장 비슷한 아이템을 매칭하고 이들의 코드 유사도를 측정한 것이다. 앞선 실험과 마찬가지로 LETTER의 코드 임베딩 간의 유사도가 TIGER에 비해 높은 것으로 보아 LETTER의 임베딩이 사용자의 선호도를 잘 반영함을 확인할 수 있다.
3.6 Hyper-parameter Analysis (RQ3)
본 논문에서는 다음과 같이 hyper-parameter의 효과를 실험적으로 검증하였다.

- Identifier length: 식별자의 길이가 짧으면 정보의 손실이 발생하며, 반대로 식별자의 길이가 너무 길어지면 오차가 누적되어 성능이 하락한다.
- Codebook size: 코드북의 크기가 커짐에 따라 일반적으로 성능이 향상되나, 너무 큰 코드북은 데이터 상의 노이즈에 취약하다.
- Strength of collaborative regularization: 가중치가 커짐에 따라 일반적으로 성능이 향상되나, 지나치게 큰 가중치는 의미를 학습하는 데에 방해가 될 수 있다.
- Strength of diversity regularization: 가중치가 지나치게 큰 경우 의미와 선호도를 반영하는 데에 방해가 될 수 있다.
- Cluster: 클러스터 크기가 지나치게 커지면 같은 클러스터를 구성하는 코드들의 유사도가 떨어지고, 반대로 지나치게 작아지면 코드들의 유사도가 과하게 높아진다.
- Temperature: 값의 변화에 따라 hard negative, 즉 positive와 비슷한 negative sample에 대한 가중치가 달라져 학습에 영향을 준다.
4. Conclusion
4.1 Summary
- 본 논문은 대형 언어 모델 기반 생성형 추천 모델을 구성하는 요소 중 식별자를 생성하는 방식을 제시한다. 이와 관하여 기존의 코드북 기반 방법의 문제점을 제시하고, 이를 해결하기 위한 방법으로 collaborative regularization과 diversity regularization을 제시한다.
- 본 논문은 [1]에서 제시한 코드북 기반 식별자 생성 방법을 기반으로, 사전학습된 CF 모델의 임베딩과 코드북으로 생성한 임베딩을 비슷하도록 만드는 collaborative regularization과 코드와 임베딩의 분포를 더욱 균일하게 만드는 diversity regularization을 도입하였다. 또한 기존의 대형 언어 모델 기반 생성형 추천 방법론에서 사용하던 generation loss를 대체하고자 추천 도메인에 맞는 랭킹 기반의 ranking-guided loss를 제시한다.
- 본 논문에서 제시한 방법은 기존의 식별자 생성 방법에 비해 높은 추천 성능을 보였으며, 다양한 실험을 통해 각 요소들의 성능을 검증하였다.
4.2 Review
본 논문은 코드북 기반 기존 방법론들의 문제점을 지적하고 이에 대한 직관적인 해결책을 제시하여 추천 성능을 향상시켰다. 기존 방법론에서 나타나는 양상으로부터 문제점을 찾고, 이를 해결하는 것이 중요함을 알 수 있다. 또한 매우 다양한 실험을 진행하며, 단순히 성능을 통해 각 요소의 효과를 검증하는 것이 아니라 이를 설명할 수 있는 실험들로 설득력을 더한 점이 인상적이다.
다만 이 논문에서 제시한 문제 및 해결책이 완전히 새로운 것은 아니다. LC-Rec[2] 역시 기존 TIGER[1]에서 제시한 코드북 기반의 식별자가 collaborative signal을 반영하지 못하며 서로 다른 아이템에 중복된 코드가 배정되는 문제가 발생함을 주장한다. 이러한 문제를 해결하기 위해 마지막 레벨에서의 코드 배정이 균일하도록 하는 제약을 추가하고, 대형 언어 모델을 fine-tune하는 방식으로 collaborative signal을 반영하고자 한다.
본 논문에서 제시한 LETTER은 LC-Rec과 달리 collaborative signal을 반영하는 과정에서 fine-tuning에 의존하지 않아 효율적이라는 장점이 있으며, 코드 분포를 모든 레벨에서 균일하도록 하여 코드 편향이라는 더욱 넓고 근본적인 문제를 해결하였다.
최근 대형 언어 모델을 활용하는 추천 시스템이 각광받는 이유 중 하나는 대형 언어 모델이 가지고 있는 넓은 분야의 지식을 활용하여 모든 추천 분야에 적용할 수 있는 universal model을 만들 수 있다는 기대이다. 이를 위해 본 논문에서 제시한 코드북 기반 식별자를 universal model을 위한 방법론으로 확장하는 것을 향후 연구 방향으로 제시해볼 수 있다. 예를 들어, 이러한 코드 생성 모델을 여러 도메인의 데이터에 동시에 학습을 시키고, 새로운 데이터셋에 대해 transfer learning을 진행하는 방법을 생각해볼 수 있다. 풍부한 source data를 통해 코드의 분포 양상과 추천을 위한 대형 언어 모델을 학습하고, 이를 소량의 target data에 adaptation할 수 있다면 작은 데이터가 들어와도 기존의 선행학습된 모델을 살짝 변형시켜 적용이 가능하다. 다만 본 논문에서 제시한 방법은 이러한 세팅을 고려하지 않은 방식이므로 이에 따른 모델의 변형이 필요하다. 이러한 연구 방향이 실제로 가능한지 확인하는 것은 많은 실험을 필요로 하나, 만약 이렇게 domain adaptation이 가능한 ID를 만들 수 있다면 universal recommender system에 한발 다가갈 수 있을 것이다.
5. References
[1] Rajput, S., Mehta, N., Singh, A., Hulikal Keshavan, R., Vu, T., Heldt, L., … & Sathiamoorthy, M. (2024). Recommender systems with generative retrieval. Advances in Neural Information Processing Systems, 36.
[2] Zheng, B., Hou, Y., Lu, H., Chen, Y., Zhao, W. X., Chen, M., & Wen, J. R. (2024, May). Adapting large language models by integrating collaborative semantics for recommendation. In 2024 IEEE 40th International Conference on Data Engineering (ICDE) (pp. 1435-1448). IEEE.
Reviewer Information
- Name: Hoyoung Choi(최호영)
- Master student at DSAIL(Data Science and Artificial Intelligence Lab), KAIST
- Research Topic: Graph Neural Networks, Recommender System, Sports Analytics