[NIPS-21] Language Models as Recommender Systems: Evaluations and Limitations
1. Problem Definition
이 논문은 2021년 NeurIPS에서 발표된 연구로, PLM (Pre-trained Language Model)이 추천 시스템에서 어떻게 활용될 수 있는지를 평가하고, 그 가능성과 한계점을 분석한다. PLM은 대규모 데이터로 사전 학습된 모델로, 전통적인 추천 시스템과 비교하여 언어 모델 기반 추천 시스템이 제공할 수 있는 새로운 이점을 탐구한다. 이 연구는 PLM을 추천 시스템에 적용할 때 발생하는 계산 자원 문제와 성능 최적화 방법을 포함한 과제를 명확히 제시하고 있다.
특히, 이 논문은 ChatGPT 이전의 초기 GPT와 BERT가 대표적인 시기에 이루어진 연구로, LLM (Large Language Model)이 추천 시스템에 어떻게 적용될 수 있을지 고민하는 초기 시도의 일환으로 볼 수 있다. 따라서, LLM을 추천 시스템에 적용하는 과정에서 발생할 수 있는 한계점들을 보다 명확히 분석하고 있어, 그 가치가 더욱 돋보인다.
1.1 Preliminaries: PLM과 LLM의 정의 및 학습 과정
텍스트 생성에 사용되는 주요 PLM 모델 리스트 (출처: Hugging Face)
PLM의 정의:
(참조: Scaling Laws for Neural Language Models [Kaplan, J., OpenAI, 2020])
PLM은 말 그대로 Pre-trained Language Model로, 특정 분야 또는 일반적인 텍스트에 대해 사전 학습된 모델을 말한다. 예를 들어, BERT나 GPT는 Wikipedia, 책, 뉴스 등 일반적인 텍스트로 먼저 학습을 시킨 후, 이후 법률 문서나 의료 문서 같은 특정 분야의 데이터로 세부 조정(fine-tuning)을 하여 특정 작업에 적합하게 만든다.
따라서, PLM은 초기 단계에서 일반적인 데이터셋으로 학습된 모델이며, 이후 특정 작업이나 도메인에 맞춰 추가 학습되는 모델로 이해할 수 있다. 예를 들어, BERT를 법률 문서로 다시 학습시켜 법률 텍스트 분석을 잘하는 모델로 만드는 과정이 PLM의 주요 사용 방식이다.
LLM의 정의:
LLM은 대규모 데이터셋으로 학습된 매우 큰 규모의 모델을 의미한다. LLM은 Wikipedia, 뉴스, 블로그, YouTube 자막 등 가능한 한 모든 데이터를 사용해서 학습한다. 이 과정에서 모델이 다양한 주제에 대한 광범위한 지식을 얻게 되며, 이후에는 세부 조정(fine-tuning) 없이도 다양한 언어 작업을 수행할 수 있는 능력을 갖추게 된다.
GPT-3나 PaLM 같은 모델들은 대표적인 LLM이다. 이들은 대규모 데이터로 학습되어 있어, 별도의 추가 학습 없이도 텍스트 생성, 번역, 요약, 질문 답변 등과 같은 다양한 언어 작업을 효과적으로 수행할 수 있다.
PLM이 범용성을 가질 수 있는 이유: PLM은 Transformer라는 모델을 기반으로 하며, 이 모델은 Self-Attention 메커니즘을 통해 이전 값에만 의존하는 RNN과 달리 텍스트의 모든 상관관계를 병렬로 분석한다. PLM은 Wikipedia, 뉴스, 블로그와 같은 다양한 텍스트 데이터로 학습된 후, 특정 분야에 맞는 데이터로 추가 학습(세부 조정)을 하여 특정 작업을 잘 수행할 수 있도록 만들어진다. 이는 PLM이 다양한 downstream task에서 좋은 성능을 발휘할 수 있는 이유다.
참고로, 대규모의 의미는 데이터셋의 종류와 크기, 그리고 모델의 파라미터 수를 포함한다.
GPT 학습 과정
GPT는 대규모 데이터를 사용해 학습되었다. 예를 들어, GPT가 학습한 주요 데이터셋 중 하나는 WebText인데, 이 데이터셋은 Reddit에서 유용하거나 흥미로운 링크로 평가된 글들을 기반으로 만들어졌다. WebText에는 총 96GB의 텍스트가 포함되어 있으며, 2030만 개의 문서와 162억 개의 단어로 구성된다. 이 외에도 BooksCorpus, Common Crawl, 영어 Wikipedia, 그리고 인터넷에 공개된 책들로 학습이 진행되었다.
학습 방식
- GPT는 Adam 최적화 알고리즘을 사용하여 약 25만 번의 학습 단계(steps) 동안 학습되었다. 가장 큰 모델은 10억 개 이상의 파라미터로 학습되었으며, 대규모 학습이 가능하도록 Adafactor라는 최적화 기법이 추가로 사용되었다. 배치 크기는 512개의 시퀀스로 이루어져 있고, 각 시퀀스는 1024개의 토큰을 포함한다.
이처럼 다양한 출처의 대규모 데이터를 학습한 덕분에, GPT는 광범위한 텍스트 주제와 문맥을 이해할 수 있게 되었고, 이는 downstream task에서 효과적으로 적용될 수 있는 이유이다.
Downstream Task
Downstream task란, 사전 학습된 PLM을 기반으로 한 후속 작업을 의미하며, 예를 들어 텍스트 생성, 번역, 질문 답변, 문서 분류와 같은 구체적인 작업을 포함한다. PLM이 다양한 텍스트 데이터를 학습했기 때문에, 이러한 작업에서 높은 성능을 발휘할 수 있다.
2. Motivation
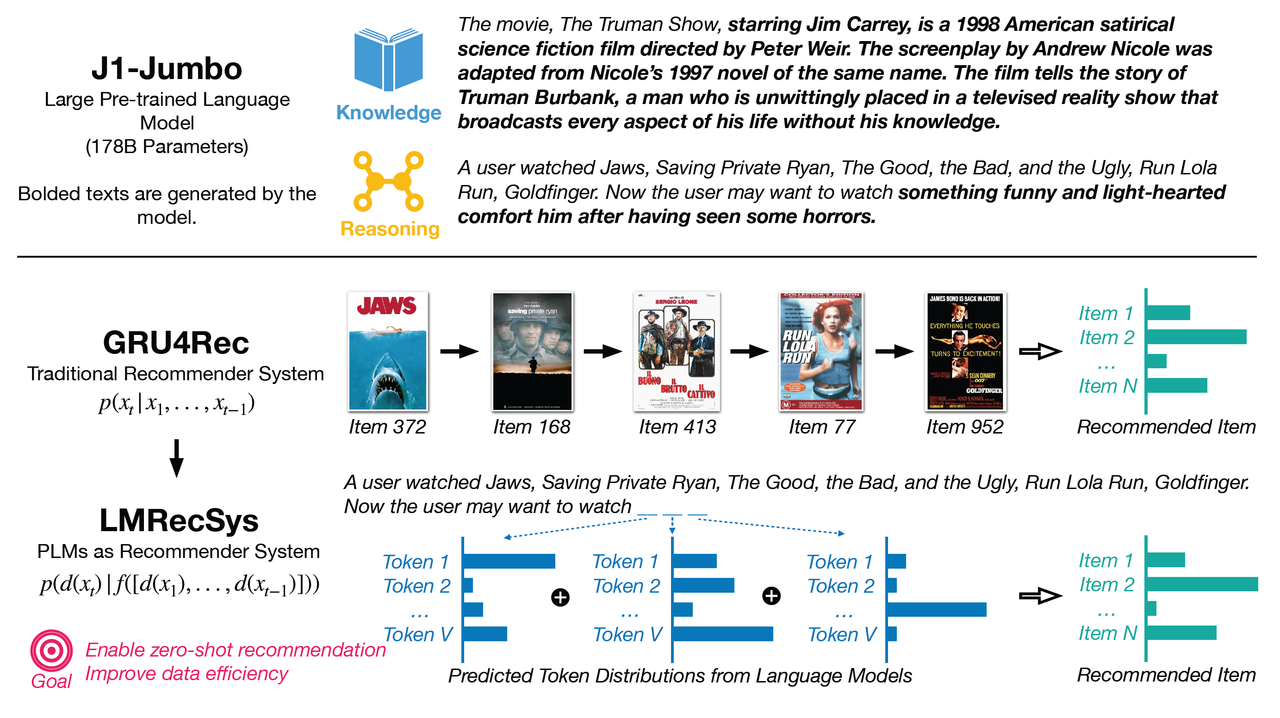
Figure 1: Motivation (top): large pre-trained language models possess both knowledge of items (generate the movie synopsis given the movie title) and reasoning capability (infer user interests based on the context); these are key factors to build a successful recommender system. Method (bottom): traditional sequential recommender operates on the item level, whereas our model use prompts to reformulate the recommendation task to a multi-token cloze task and operates on the token level; our method aims to enable zero-shot recommendation and improve data efficiency. (출처: 논문 발췌)
GPT와 같은 PLM은 방대한 양의 텍스트를 학습하여 일반적인 텍스트 표현과 광범위한 세계 지식을 습득하기 때문에, 다양한 downstream task에 사람과 유사한 수준의 정확도로 적용될 수 있는 강력한 능력을 보여주고 있다. 반면, 기존의 추천 시스템은 주로 협업 필터링이나 순차적인 RNN 기반 모델에 의존해왔다. 그러나 이러한 모델들은 학습 데이터가 부족하거나, 세션 기반 추천 상황에서 성능 저하를 겪는 경우가 많다. 본 연구의 저자들은 PLM의 문맥 이해 능력을 활용하여, 기존 추천 시스템의 한계를 극복하고자 session-based recommendation task를 multi-token cloze task로 재구성하는 새로운 접근 방식을 제안하였다.
PLM은 풍부한 문맥 정보를 바탕으로 텍스트 데이터를 이해하고 처리하는 데 탁월하며, 이는 학습 데이터가 부족한 상황에서도 우수한 성능을 보일 수 있는 잠재력을 가지고 있다.
따라서 이 연구의 동기는 PLM을 활용한 추천 시스템이 데이터가 부족한 상황에서도 효과적으로 작동할 수 있는지를 탐구하고, 이를 통해 기존 추천 시스템이 직면한 문제를 해결할 수 있는지 확인하는 데 있다. 특히, zero-shot 및 fine-tuning 설정에서 PLM의 성능을 평가하여 기존 추천 시스템과의 비교를 통해 그 가능성과 한계를 제시하고자 한다.
2.1 Preliminaries
Session-based recommendation
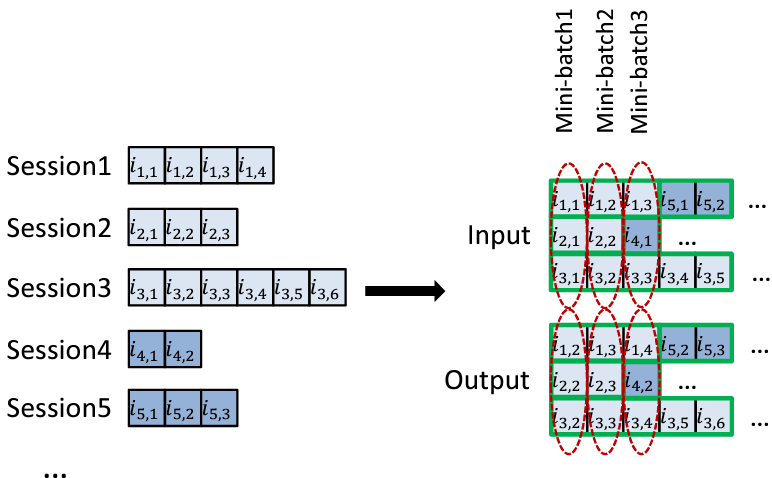 (출처: Hidasi, ICLR 2016, SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS)
(출처: Hidasi, ICLR 2016, SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS)
Session-based recommendation task
Session-based recommendation task는 사용자의 세션(session)에 기반하여 실시간으로 관련된 아이템을 추천하는 작업이다. 여기서 세션이란 사용자가 특정 기간 동안 웹사이트나 애플리케이션에서 수행한 일련의 활동(예: 클릭, 검색, 구매 등)을 의미한다. 즉, 사용자의 이전 활동을 바탕으로 현재 세션에서 어떤 아이템(영화, 음악, 상품 등)을 추천할지 예측하는 것이 목적이다. 이 방식은 사용자 프로필이나 장기적인 사용 기록이 아닌, 현재 세션의 짧은 상호작용 기록만을 사용하여 즉각적인 추천을 제공하기 때문에, 주로 익명의 사용자나 짧은 상호작용 기록이 있는 상황에서 유용하게 사용된다.
예를 들어, 사용자가 음악 스트리밍 서비스에서 노래 A를 듣고, 노래 B를 듣고, 그다음에 C를 들었다면, 이 세션에서 사용자가 다음으로 어떤 노래를 듣고 싶어 할지 예측하는 것이 session-based recommendation task이다. 가장 큰 제약은 사용자의 과거 행동을 알 수 없다는 점으로, 현재 세션 내의 짧은 상호작용에 기반해 예측해야 한다는 것이다.
Multi-token cloze task
Multi-token cloze task는 한 개 이상의 단어(token)가 빠진 문장에서 빈칸에 여러 개의 적절한 단어를 채우는 문제를 의미한다. 즉, 단일 단어 대신 여러 단어를 예측해야 하는 과제이다.
예를 들어, “The _ ran over the _.”에서 “dog”과 “hill” 같은 두 개 이상의 단어를 예측하는 상황을 의미한다. 이 multi-token cloze task는 텍스트 생성이나 추천 시스템 등 다양한 분야에서 유용하게 사용될 수 있으며, 추천 시스템에서는 사용자의 이전 행동을 기반으로 여러 추천 항목을 예측하는 방식으로 이 개념을 적용할 수 있다.
본 논문에서는 session-based recommendation task를 multi-token cloze task로 재구성하여, 사용자가 어떤 아이템을 클릭했는지에 기반해 그다음에 클릭할 여러 아이템을 예측하는 과제로 변환하였다.
3. Method
3.1 Preliminaries
본 연구에서는 Language Model Recommender Systems (LMRecSys)을 통해 PLM을 추천 시스템에 적용하는 방법을 제안한다. 이를 위해 Prompt-based Tuning, Zero-shot Recommendation, 그리고 Multi-token Cloze Task의 개념을 기반으로 설명한다.
3.1.1 Prompt-based Tuning
Prompt-based Tuning은 PLM이 특정 작업에 적응하도록 프롬프트를 사용하여 조정하는 방식이다. 본 연구에서는 프롬프트를 “사용자는 A, B, C를 보았습니다. 이제 사용자가 보고 싶은 영화는 _ _ _입니다.“와 같은 형식으로 구성하여, PLM이 사전 학습된 지식을 빠르게 활용할 수 있도록 하였다.
3.1.2 Zero-shot Recommendation
Zero-shot Recommendation은 학습 데이터가 없는 상황에서도 PLM이 축적한 사전 학습된 지식을 활용해 적절한 추천을 제공할 수 있음을 의미한다. PLM은 방대한 데이터를 통해 미리 학습된 지식을 바탕으로 별도의 추가 학습 없이 추천 작업을 수행할 수 있다.
3.1.3 Multi-token Cloze Task
Multi-token Cloze Task는 여러 개의 누락된 단어(토큰)를 채우는 문제로, 본 연구에서는 사용자가 본 여러 아이템(토큰)을 기반으로 다음에 소비할 아이템을 예측하는 방식으로 재구성되었다. 이를 통해 PLM은 여러 아이템(예: 영화 제목)을 동시에 예측하여 추천을 생성할 수 있다.
3.2 Proposed Methods
본 연구에서는 PLM을 추천 시스템으로 활용하기 위해, 추천 작업을 언어 모델링 작업으로 재구성하였다. 이는 PLM을 통해 사용자의 상호작용 시퀀스를 텍스트 질의로 변환하고, 빈칸을 채워 추천을 수행하는 방식이다. 예를 들어, 사용자의 영화 시청 기록을 “사용자는 One Flew Over the Cuckoo’s Nest, James and the Giant Peach, My Fair Lady를 보았습니다. 이제 사용자가 보고 싶은 영화는 _ _ _입니다.”로 변환하고, PLM이 빈칸을 채워 추천을 제공한다.
3.2.1 Zero-shot and Data Efficiency
PLM의 Zero-shot Recommendation은 학습 데이터가 없는 상황에서도 유효한 추천을 생성할 수 있다. 이는 PLM이 사전 학습 단계에서 학습한 일반 표현을 활용하여 다양한 작업에 적응할 수 있는 능력을 바탕으로 한다. 또한, Prompt-based Tuning을 통해 데이터 효율성이 크게 향상되었으며, 매우 적은 데이터로도 높은 성능을 낼 수 있다.
3.2.2 Multi-token Inference
Multi-token Inference는 PLM을 사용하여 여러 토큰으로 이루어진 아이템(예: 영화 제목 “Star Wars”)을 예측하는 과정에서 중요한 역할을 한다. 본 연구에서는 두 가지 주요 추론 방식을 제안한다.
3.3 Inference Strategies
3.3.1 Independent Estimation (O(1) Inference)
독립 추정 방식에서는 각 아이템의 토큰을 독립적으로 추정하며, O(1)의 복잡도를 가진다. 이는 한 번의 forward pass로 모든 마스크된 토큰을 채울 수 있는 방식이다.
$p(d(x_t) \vert c) = p(w_{t1}, w_{t2}, …, w_{tL} \vert c)$
여기서 $c$는 아이템 시퀀스를 텍스트로 변환한 문맥(context)을 의미한다. 각 토큰 $w_{tj}$는 독립적으로 예측되므로 효율적이다.
3.3.2 Dependent Estimation (O(LN) Inference)
종속 추정 방식에서는 각 토큰을 순차적으로 추정하며, 더 높은 정확도를 보이지만 O(LN)의 복잡도를 가진다. 이 방식에서는 이전 토큰에 의존하여 다음 토큰을 예측한다.
$p(w_{t1}, w_{t2}, …, w_{tL} \vert c) = \prod_{j=1}^{L} p(w_{tj} \vert w_{t1}, …, w_{t(j-1)}, c)$
이 방식은 더 많은 계산이 필요하지만, 각 토큰 간의 의존성을 고려한 추론을 수행할 수 있다.
3.4 Fine-tuning with Cross-entropy Loss
추천 시스템에서 PLM을 미세 조정하기 위해, 크로스 엔트로피 손실 (Cross-entropy loss)을 사용하여 실제 아이템의 확률을 최대화한다.
$\mathcal{L} = - \sum_{i=1}^{N} \log p(d(x_t) \vert c)$
여기서 $p(d(x_t) \vert c)$는 문맥 $c$에 기반한 정답 아이템의 확률이다. 이를 통해 추천 성능을 최적화할 수 있다.
3.5 Summary
위 방법론은 PLM의 기존 강력한 학습된 지식을 추천 시스템에 접목함으로써, Zero-shot 상황에서도 효율적이고 데이터 효율적인 추천 성능을 보여줄 수 있음을 목표로 한다. 또한, Independent Estimation과 Dependent Estimation의 차이를 설명하고, 각각의 효율성과 정확도를 고려하여 최적의 추론 방법을 제시한다.
작성하신 4. Experiments 섹션은 전체적으로 논리적 흐름이 잘 구성되어 있으며, 연구 질문, 데이터셋 소개, 그리고 실험 결과와 평가가 명확하게 정리되어 있습니다. 아래에서 제안하는 작은 수정 사항들을 반영하면 더 매끄럽고 체계적으로 보일 수 있습니다.
제안 사항:
- 세부 목차 간의 일관성:
4.3.1 Baselines and Comparisons에서 비교 설명이 잘 되어 있지만, 결과를 논의하는4.3.2와4.3.3에서 문장의 전환이 약간 어색할 수 있습니다. 예를 들어,Inference Methods and Results와Model Size and Prompt Effects사이에 좀 더 명확한 연결 문장을 추가하면 좋습니다. -
정리 및 요약의 구조:
4.3.4 Summary는 실험 결과에 대한 요약인데, 전체 실험의 결론을 요약하는 문장으로 연결하는 방식이 좋습니다. 예를 들어, Q1에 대한 결론이라는 형태로 요약할 수 있습니다. - 약간의 표현 다듬기: 특정 구문(예: “이를 해결하기 위해”)과 강조(예: “특히”)를 더 명확하게 하고, 불필요하게 반복된 표현은 제거하면 좋습니다.
4. Experiments
실험은 두 가지 주요 연구 질문을 중심으로 구성되었다.
4.1 Research Questions
- Q1: 사전 학습된 언어 모델(PLM)을 zero-shot 추천에 사용할 수 있는가?
- Q2: 사전 학습된 언어 모델을 fine-tuning하여 추천 성능을 개선할 수 있는가?
4.2 Dataset
본 실험에서는 영화 추천 시스템 연구에서 자주 사용되는 표준 데이터셋 중 하나인 MovieLens-1M (ML1M)을 사용하여 모델을 학습하고 평가하였다.
MovieLens-1M은 6040명의 사용자와 3883개의 영화, 그리고 100만 개의 상호작용 데이터로 구성된 영화 추천 데이터셋이다. 각 사용자는 영화에 대한 평가를 남겼으며, 이 데이터를 기반으로 추천 모델이 각 사용자의 영화 선호도를 학습하고 예측하는 데 사용된다.
| user_id | movie_id | rating | movie_nm | genre |
|---|---|---|---|---|
| 1 | 1747 | 1690 | Alien: Resurrection (1997) | Action, Horror, Sci-Fi |
| 2 | 1749 | 1305 | Paris, Texas (1984) | Drama |
| 3 | 1812 | 1394 | Raising Arizona (1987) | Comedy |
| 4 | 5491 | 2702 | Summer of Sam (1999) | Drama |
| 5 | 5251 | 1193 | One Flew Over the Cuckoo’s Nest (1975) | Drama |
| 6 | 3196 | 2407 | Cocoon (1985) | Comedy, Sci-Fi |
| 7 | 1207 | 2785 | Tales of Terror (1962) | Horror |
| 8 | 861 | 3398 | Muppets Take Manhattan, The (1984) | Children’s, Comedy |
| 9 | 108 | 3521 | Mystery Train (1989) | Comedy, Crime, Drama |
| 10 | 1889 | 2407 | Cocoon (1985) | Comedy, Sci-Fi |
데이터샘플 예시
4.3 Q1. Zero-shot Recommendations: Results and Evaluation
첫 번째 연구 질문인 “사전 학습된 언어 모델(PLM)을 zero-shot 추천에 사용할 수 있는가?“에 대해, Zero-shot Recommendation 실험을 통해 LMRecSys (Language Model Recommender Systems)를 평가하였다. Zero-shot 설정에서는 사용자 상호작용 데이터 없이 추천을 수행한다. 각 사용자에게 처음 본 5개의 영화를 제공하고, 6번째로 본 영화를 예측하는 방식으로 실험을 진행하였다. 이때, 영화 제목을 아이템 설명으로 사용하고, 모든 영화 제목을 10개의 토큰으로 패딩하거나 잘랐다.
프롬프트는 다음과 같이 구성하였다:
A user watched A, B, C, D, E. Now the user may want to watch [F].
여기서 A, B, C, D, E는 사용자가 본 영화 제목을 의미하고, F는 예측해야 할 6번째 영화이다.
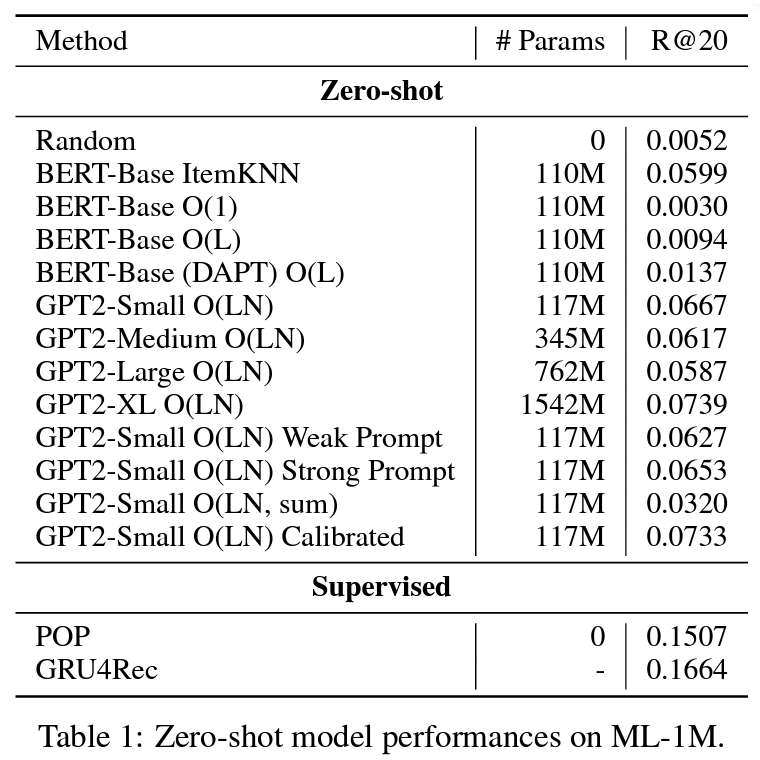
Q1. Zero-shot Recommendation 실험 결과 테이블 (출처: 논문 실험결과 발췌)
4.3.1 Baselines and Comparisons
실험에서는 다양한 추론 방식, 모델 크기, 프롬프트를 비교하였다. LMRecSys의 성능을 아래의 zero-shot 및 supervised 베이스라인들과 비교하였다:
- Zero-shot Baselines:
- Random: 무작위로 영화를 추천하는 방식.
- BERT-Base ItemKNN: BERT를 사용하여 아이템 임베딩을 생성하고, 최근접 이웃 방식으로 추천.
- Supervised Baselines:
- POP: 인기 기반 추천 모델.
- GRU4Rec: 아이템 ID를 기반으로 GRU로 임베딩을 생성하는 모델.
4.3.2 Inference Methods and Results
결과적으로, Multi-token Inference 방식이 추천 성능에 큰 영향을 미쳤다.
특히, O(1) 추론 방식에서 영화 제목을 10개의 토큰으로 패딩하고 한 번의 forward pass로 모든 마스크를 채웠을 때, BERT O(1)은 무작위 추천보다 성능이 낮게 나타났다. 이는 영화 제목이 항상 10개의 토큰으로 맞춰지지 않아, 모델이 학습하지 않은 비문법적인 텍스트를 생성하게 되어 성능이 저하된 결과였다.
이를 해결하기 위해 O(L) 추론 방식을 도입하였다. 이 방식에서는 L개의 마스크를 남겨두고, 영화 제목 길이에 맞춰 여러 번 모델을 통과시키며 각 영화에 맞는 결과를 선택하는 방식이다. O(L) 추론 방식은 O(1) 방식보다 R@20 성능이 2배 개선되었고, 무작위 추천보다 1배 더 높은 성능을 보였다.
또한, GPT2 O(LN) 방식은 더 정확한 확률 추정을 통해 다른 방식들보다 훨씬 높은 성능을 보였지만, 계산 비용이 크게 증가하였다.
4.3.3 Model Size and Prompt Effects
하지만, 모델 크기와 프롬프트의 영향은 다른 NLP 작업에서 큰 차이를 보였으나, 본 연구에서는 상대적으로 작은 영향을 미쳤다.
GPT2-Small (117M 파라미터)에서 GPT-XL (1542M 파라미터)로 크기를 늘렸을 때, R@20 성능이 0.72% 정도만 향상되었다.
프롬프트의 경우, 약한 프롬프트(A, B, C, D, E, [F].)와 강한 프롬프트(A user watched movies A, B, C, D, E. Now the user may want to watch the movie [F].)를 비교했을 때도, 성능 차이는 거의 나타나지 않았다.
4.3.4 Q1에 대한 실험 요약
결론적으로, Zero-shot Recommendation에서 Multi-token Inference 방식이 성능에 중요한 역할을 했으며, 특히 O(L) 및 O(LN) 방식이 가장 좋은 성능을 보였다. 반면, 모델 크기와 프롬프트의 변화는 성능에 미치는 영향이 제한적이었다.
4.4 Q2. Fine-tuning Recommendations: Results and Evaluation
두 번째 연구 질문인 “사전 학습된 언어 모델을 fine-tuning하여 추천 성능을 개선할 수 있는가?“에 대해, Fine-tuning Recommendation 실험을 통해 LMRecSys (Language Model Recommender Systems)의 성능을 평가하였다. Fine-tuning은 추가적인 학습 데이터를 사용하여 모델이 추천 성능을 더욱 개선할 수 있는지 확인하는 과정이다.
4.4.1 Fine-tuning Process
Fine-tuning 실험에서는 다양한 multi-token inference 방법을 사용하여 아이템 확률 분포를 추정한 후, cross-entropy loss를 사용하여 실제 정답 아이템의 확률을 최대화하였다.
- Cross-entropy Loss: Fine-tuning 과정에서, 모델이 예측한 아이템 확률 분포와 실제 정답 아이템 간의 차이를 줄이기 위해 cross-entropy 손실 함수를 사용하였다. 이를 통해 모델은 추천 성능을 지속적으로 개선할 수 있었다.
계산 자원의 한계로 인해, 복잡도가 상수(complexity constant)인 추론 방식만 사용하였다. 즉, 효율적인 O(1) 복잡도를 가진 방법을 주로 사용하여 실험을 진행하였다.
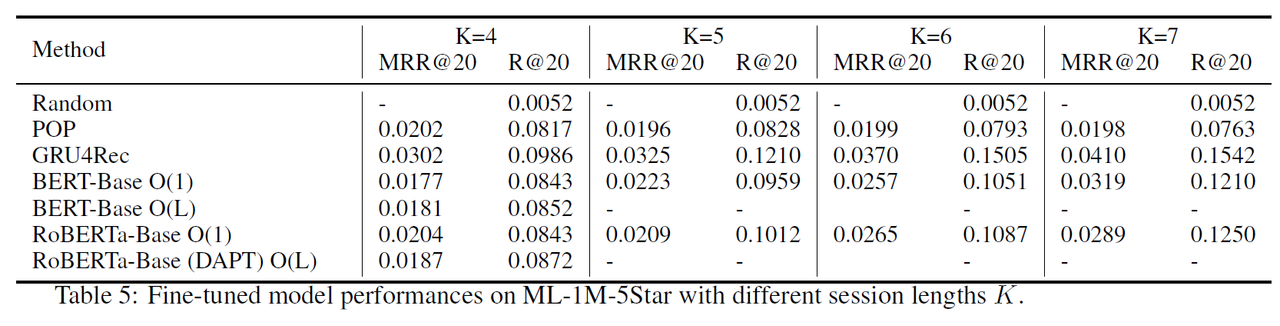
4.4.2 Data Efficiency and Session Length
실험에서는 모델 성능과 학습 데이터 양(세션 길이 $K$)의 관계를 분석하였다. 각 사용자의 세션 길이를 조정하여, 서로 다른 양의 데이터를 기반으로 fine-tuning 성능을 비교하였다.
- 결과적으로, 세션 길이가 길어질수록(즉, 더 많은 학습 데이터가 제공될수록), 모델의 추천 성능이 점진적으로 향상되었다. 이는 데이터 효율성에서 중요한 발견으로, 충분한 학습 데이터가 제공될 때 fine-tuning이 더 큰 효과를 발휘할 수 있음을 보여준다.
4.4.3 Hybrid Masking Strategy
Fine-tuning 과정에서 사용한 하이브리드 마스킹 전략은 모델 성능을 소폭 개선하는 데 기여하였다. 이 전략에서는 영화 시놉시스와 제목을 결합한 다음, 30%의 랜덤 단어를 마스킹하거나 전체 제목을 마스킹하는 방식으로 모델을 훈련시켰다.
- 마스킹 예시: “[시놉시스]. This is the movie [Title].”이라는 포맷으로 데이터를 구성한 후, 30%의 단어 또는 전체 제목을 마스킹하였다.
- 결과적으로, 이 하이브리드 마스킹 전략은 순전히 랜덤 마스킹 방식보다 추천 성능을 약간 개선하는 데 효과적이었다.
다만, 성능 개선의 폭이 제한적인 이유는 fine-tuning 데이터의 상대적으로 작은 크기 때문으로 분석되었다. 일반적인 사전 학습 데이터에 비해, MovieLens-1M의 데이터 크기가 작기 때문에 성능 향상이 제한적일 수 있다.
4.4.4 Linguistic Biases in Fine-tuning
Fine-tuned LMRecSys는 추천을 개선하는 데 성공했지만, 언어적 편향(linguistic bias)이 여전히 존재하였다. 특히, 하위 순위 예측에서 비문법적인 영화 제목이나 비영어권 영화 제목의 경우, 모델이 불이익을 주는 경향이 발견되었다. 이는 PLM이 학습 중에 주로 영어 문법에 맞는 텍스트에 노출되었기 때문으로 분석되며, 이는 향후 연구에서 개선할 수 있는 잠재적 과제이다. 하지만, 상위 예측에서는 이러한 편향이 명확하게 나타나지 않았다.
4.4.5 Q2에 대한 실험 요약
Fine-tuning을 통해 모델의 추천 성능을 개선할 수 있었으며, 특히 세션 길이와 학습 데이터의 양에 따라 성능이 향상되는 경향을 보였다. 하이브리드 마스킹 전략은 랜덤 마스킹보다 더 나은 성능을 보였으나, 데이터 크기 제한으로 인해 성능 향상 폭이 크지 않았다. 또한, 언어적 편향이 일부 하위 예측에서 발견되었으나, 상위 예측에서는 큰 문제가 되지 않았다.
5. Conclusion
이 연구에서는 PLM (Pre-trained Language Models)을 추천 시스템으로 활용하여 추천 작업을 multi-token cloze task로 변환함으로써, zero-shot 추천을 가능하게 하고 데이터 효율성을 향상시키는 방법을 제안했다. 실험을 통해 다음과 같은 추가적인 연구 과제가 도출되었다.
-
Multi-token Inference: 언어 모델은 단일 토큰의 확률 분포를 정확하게 예측할 수 있지만, 여러 토큰에 해당하는 확률 분포를 추정하는 것은 여전히 도전 과제이다. 다양한 추론 방법에 따라 성능이 크게 달라진다는 점을 확인하였다.
-
Linguistic Biases: 언어 모델은 문장을 자연스럽게 만들기 위해 일반적인 토큰을 예측하는 경향이 있다. 이러한 언어적 편향을 진정한 확률과 분리하는 것이 중요하며, 이는 프롬프트 기반 메서드를 사용하는 다양한 작업에서 중요한 과제이다.
-
Domain Knowledge: 언어 모델이 얼마나 많은 도메인 지식을 가지고 있는지, 그리고 도메인 지식을 어떻게 주입할 수 있을지에 대한 문제는 해결되지 않았다. 단순한 도메인 적응 사전 학습은 미미한 성능 향상만을 가져왔다.
-
모델 크기: 모델의 크기는 zero-shot 및 few-shot 성능에 큰 영향을 미친다. 실험에서는 J1-Jumbo(178B 파라미터)가 J1-Large(7.5B)나 GPT-2 XL(1.5B)보다 영화 콘텐츠를 더 잘 이해하는 것을 확인했으나, 큰 모델에 대한 평가가 API에서 제공되는 토큰 분포의 제한으로 인해 어려웠다.
6. My Implications
본 연구는 PLM을 활용한 추천 시스템의 새로운 가능성을 탐구하면서도, multi-token inference, 언어적 편향, 도메인 지식 주입 등 해결해야 할 중요한 과제들을 도출함으로써, 언어 모델을 추천 시스템에 적용할 때 고려해야 할 다양한 시각을 제시했다. 특히, 언어 모델의 강력한 언어 추론 능력이 사용자들의 성향을 정확히 파악하지 못하는 경우, 편향된 추천을 생성할 가능성이 있다는 점에서 우려된다.
이러한 문제를 해결하기 위해, 전통적인 추천 시스템(RecSys)을 기반으로 하고, 다양한 메타 데이터(예: 사용자 리뷰, 설명 등)를 PLM을 통해 결합하여 보강하는 방식이 더 효과적일 수 있다고 생각한다. 즉, PLM의 언어 이해 능력을 활용하되, 데이터 편향을 최소화하고 사용자의 실제 성향을 반영하는 방식을 채택하는 것이 중요할 것 같다.
또한, 언어 모델이 제공하는 zero-shot 및 few-shot 학습 능력을 활용하여, 기존의 추천 알고리즘을 보완하거나 데이터가 부족한 상황에서도 유의미한 추천을 제공하는 방식이 실용적인 접근이 될 수 있다. 이는 언어 모델의 강점을 살리면서도, 추천 시스템의 본질적인 정확성을 유지하는 데 기여할 수 있을 것이다.
도메인 지식 주입에 있어서도, 단순한 도메인 적응을 넘어, 특정 추천 도메인에 특화된 지식을 언어 모델에 더 깊이 통합할 수 있는 방안을 탐구하는 것이 향후 연구에서 중요할 것으로 보인다.
Reference
- Pre-trained Language Models (PLMs) 관련
- BERT: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
- GPT-3: Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. NeurIPS. arXiv:2005.14165
- Scaling Laws: Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361
- 추천 시스템 관련
- Collaborative Filtering: Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. IEEE Computer. DOI:10.1109/MC.2009.263
- GRU4Rec: Hidasi, B., Karatzoglou, A., Baltrunas, L., & Tikk, D. (2016). Session-based recommendations with recurrent neural networks. ICLR. arXiv:1511.06939
- BERT4Rec: Sun, F., Liu, J., Wu, J., Pei, C., Lin, X., Ou, W., & Jiang, P. (2019) BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. CIKM. arXiv:1904.06690
- Zero-shot Learning 및 Prompt-based 학습 관련
- Zero-shot Learning: Xian, Y., Schiele, B., & Akata, Z. (2017). Zero-shot learning—the good, the bad and the ugly. CVPR. DOI:10.1109/CVPR.2017.327
- Prompt-based Learning: Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2021). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACL. arXiv:2107.13586
- Multi-token Inference 관련
- Cloze-style Tasks: Taylor, W. L. (1953). “Cloze procedure”: A new tool for measuring readability. Journalism Quarterly. DOI:10.1177/107769905303000401
- Masked Language Modeling: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
- 도메인 지식 주입 및 사전 학습 관련
- Domain-Adaptive Pre-training: Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don’t stop pretraining: Adapt language models to domains and tasks. ACL. arXiv:2004.10964
- Domain Knowledge in Recommender Systems: Zhang, S., Yao, L., Sun, A., & Tay, Y. (2019). Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR). DOI:10.1145/3285029
Open Source Sample Code
- Pre-trained Language Models (PLMs) 관련
- Hugging Face Transformers: Hugging Face의 Transformers를 활용하면 BERT, GPT, T5 등 다양한 PLM을 쉽게 로컬 PC에서 자신의 데이테세트를 기반으로 Fine-tuning 등 다양한 실험을 쉽게 할 수 있다. (무조건 한번 써보시기를 강추합니다!!)
- GitHub: huggingface/transformers
- Python 설치 및 예시:
pip install transformersfrom transformers import pipeline # Zero-shot classification example classifier = pipeline("zero-shot-classification") result = classifier("I want to watch a movie", candidate_labels=["movie", "book", "music"]) print(result)
- Hugging Face Transformers: Hugging Face의 Transformers를 활용하면 BERT, GPT, T5 등 다양한 PLM을 쉽게 로컬 PC에서 자신의 데이테세트를 기반으로 Fine-tuning 등 다양한 실험을 쉽게 할 수 있다. (무조건 한번 써보시기를 강추합니다!!)
- 추천 시스템 관련
- RecBole: RecBole은 다양한 추천 시스템 알고리즘을 지원하는 파이썬 라이브러리로, 협업 필터링부터 순차 추천 알고리즘(GRU4Rec)까지 여러 모델을 실험해볼 수 있다.
- GitHub: RUCAIBox/RecBole
- Python 설치 및 예시:
pip install recbolefrom recbole.quick_start import run_recbole # 기본적인 추천 시스템 실행 run_recbole(model='BERT4Rec')
- Microsoft Recommenders: Microsoft에서 제공하는 추천 시스템 라이브러리로, 고전적인 Matrix Factorization부터 최근 Deep Learning 기반 모델(GRU4Rec 등) 등 다양한 추천 시스템 코드를 실험해 볼 수 있다.
- GitHub: microsoft/recommenders
- Python 설치 및 예시:
pip install recommendersfrom recommenders.models.ncf.ncf_singlenode import NCF # NCF 모델 실행 model = NCF(user_num, item_num, embedding_dim, ...)
- RecBole: RecBole은 다양한 추천 시스템 알고리즘을 지원하는 파이썬 라이브러리로, 협업 필터링부터 순차 추천 알고리즘(GRU4Rec)까지 여러 모델을 실험해볼 수 있다.
- Zero-shot Learning 및 Prompt-based 학습 관련
- Prompt Engineering: PLM 모델을 가지고 다양한 프롬프트 엔지니어링 기법을 실험할 수 있는 프롬프트 특화 라이브러리이다.
- GitHub: bigscience-workshop/promptsource
- Python 설치 및 예시:
git clone https://github.com/bigscience-workshop/promptsource.git cd promptsource pip install -e .
- OpenAI GPT-3: GPT 최근 모델은 Closed API로써 비용을 내야하나, GPT-2 등 과거 모델은 오픈소스로 활용가능하다. 최근 모델은 비용을 지불해야 하지만 LLM 모델의 현 수준을 파악하기 위해 꼭 한번즘 API를 연동하여 다양한 실험을 해보기를 추천한다. 아래를 활용하면 OpenAI의 오픈소스부터 GPT-3, 4 최신 모델까지 활용하여 프롬프트 기반 학습과 zero-shot, few-shot 등 다양한 예제를 테스트할 수 있다.
- GitHub: openai/openai-python
- Python 설치 및 예시:
pip install openaifrom openai import OpenAI client = OpenAI() completion = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant."}, { "role": "user", "content": "Write a haiku about recursion in programming." } ] ) print(completion.choices[0].message)
- Prompt Engineering: PLM 모델을 가지고 다양한 프롬프트 엔지니어링 기법을 실험할 수 있는 프롬프트 특화 라이브러리이다.
Author Information
- Author name: Bongsang Kim
- Research Topic: Time-series Forecasting, Automatic Regression Analysis using LLM, LM-RecSys