[WSDM-24] LLMRec: Large Language Models with Graph Augmentation for Recommendation
1. Problem Definition
This paper addresses a major issue faced by recommendation systems: data sparsity. Traditional methods often struggle when there are few interactions between users and items, making it difficult to accurately predict user preferences. Additionally, relying on side information like item attributes or user profiles can be problematic. While these sources can bridge the gaps, they often come with their own set of challenges such as noise, inconsistencies, and availability issues, which can further degrade the model’s performance.
To address these challenges, the paper introduces a novel framework called LLMRec, which leverages large language models (LLMs) for graph augmentation. The key issues LLMRec aims to solve include:
Sparse Implicit Feedback Signals: When there are limited user-item interactions, collaborative filtering models struggle to effectively capture user preferences. This includes the cold-start problem, which arises when new users or items have little to no historical data, further complicating the recommendation process.
Data Quality Issues with Side Information: When side information is low-quality, inconsistent, or incomplete, it can introduce noise that negatively affects model performance
To overcome these challenges, LLMRec employs three distinct LLM-based graph augmentation strategies, enriching the interaction graph and mitigating the impact of sparse data and unreliable side information, ultimately enhancing recommendation quality.
2. Motivation
The LLMRec framework was developed to address significant challenges in recommendation systems, particularly with handling sparse user-item interactions and unreliable side information. These limitations, which have been longstanding issues in the field, motivated the authors to propose an innovative solution.
1. Challenges with Data Sparsity and Side Information Quality:
- Traditional recommendation models, such as collaborative filtering, typically rely on a large amount of user-item interaction data to predict preferences accurately. However, in most real-world scenarios, this data is often sparse, making it difficult to build robust user and item representations.
- As a result, many approaches incorporate side information like item attributes or user profiles. While this can help address sparsity, the quality of this side information is frequently inconsistent due to factors like noise, data heterogeneity, or missing information. These issues can undermine the effectiveness of the model.
2. Limitations of Current Augmentation Methods:
- Existing augmentation techniques, such as self-supervised learning or graph-based methods, typically generate additional relationships between users and items to improve recommendations. However, these approaches often fail to fully capture the subtle and complex preferences of users, particularly when it comes to understanding the rich context that can be derived from textual or other natural language-based data.
- Additionally, relying on side information assumes that all attributes are of equal value, but this is often not the case. Poor-quality or irrelevant side information can weaken a model’s ability to make accurate predictions.
3. The Role of Large Language Models (LLMs):
- Recent advances in large language models (LLMs) have shown their ability to capture deep semantic relationships and reason about user preferences more effectively than traditional ID-based methods. LLMs are equipped with extensive knowledge bases and are able to generate more insightful representations of user-item interactions based on natural language data.
- This inspired the authors to use LLMs for augmenting the recommendation process, offering a richer and more contextually aware approach than what is typically achievable with standard techniques.
4. The Unique Advantage of LLMRec:
- What sets LLMRec apart from existing methods is its use of three novel LLM-based strategies for augmenting the interaction graph. These strategies involve reinforcing user-item interaction edges, enhancing item attributes, and creating more comprehensive user profiles, all derived from natural language data.
- Unlike conventional models that rely on static or incomplete side information, LLMRec dynamically generates new relationships and attributes, leading to a more accurate and reliable representation of user preferences.
By using LLMs to address the issues of data sparsity and unreliable side information, LLMRec presents an unprecendented approach to improve recommendation systems. It strengthens the user-item interaction graph, and enhances the interpretability and the relevance of recommendations.
3. Method
The LLMRec framework proposes a methodology that utilizes large language models (LLMs) to augment the recommendation process through three primary strategies:
(i) Reinforcing user-item interaction edges (ii) Enhancing item node attributes (iii) Conducting user profiling
The framework is designed to leverage the extensive knowledge base and reasoning abilities of LLMs to overcome the challenges of data sparsity and low-quality side information.
The breakdown of the methodology, including the notation and detailed explanation of each strategy, is presented below.
3.1 Reinforcing User-Item Interaction Edges
This strategy aims to address the scarcity of user-item interactions by generating new interaction edges using LLMs.
- Notation:
- $ u $: User
- $ i $: Item
- $ C_ u = \lbrace i_ {u,1}, i_ {u,2}, \ldots, i_ {u, \vert C_u \vert} \rbrace $: Candidate item pool for user $ u $
- $ i^+_ u $: Positive item sample for user $ u $
- $ i^-_ u $: Negative item sample for user $ u $
- $ E^+ $: Original set of user-item interaction edges
- $ E_ A $: Augmented set of user-item interaction edges
-
Explanation: LLMRec uses an LLM-based Bayesian Personalized Ranking (BPR) sampling algorithm to generate positive and negative item samples ($ i^+_ u $ and $ i^-_ u $) for each user $ u $. The candidate items are selected from a pool $ C_ u $, which is generated by the base recommender for each user. LLMs predict which items the user might like or dislike based on historical interactions, textual content, and contextual knowledge. The newly generated samples are added to the augmented set $E_ A $.
The augmented set of user-item interactions is defined as:
$ E_A = \lbrace (u, i^+_ u, i^-_ u) \mid (u, i^+_ u) \in E^+_ A, (u, i^-_ u) \in E^-_ A \rbrace $ The set $E_A $ includes these newly generated interactions for each user, where each user has one pair: a positive item and a negative item.
-
Objective: To enhance the learning process, LLMRec aims to maximize the posterior probability of the embeddings $ E = \lbrace E_ u, E_ i \rbrace )$ given the original and augmented interactions:
$ E^{*} = \arg\max_ E \, p(E \mid E^+ \cup E_ A) $
This enables LLMRec to incorporate the LLM-generated interactions into the original graph, improving the model’s understanding of user preferences.
3.2 Enhancing Item Node Attributes
The goal of this strategy is to improve the quality of item representations by leveraging LLMs to generate additional attributes for items.
- Notation:
- $ A_i $: Augmented attributes for item $ i $
- $ f_{A,i} $: LLM-generated feature representation of item $ i $
- $ F_A $: Set of augmented features for all items
-
Explanation: The LLM is used to generate enriched item attributes based on existing textual content and interaction history. For example, if the item is a movie, attributes such as director, country, and language are extracted using LLM prompts. These attributes are encoded as features $ f_{A,i} $ and incorporated into the feature set $ F_A $.
The final representation of the item $ i $ is then given by:
$ f_ {A,i} = \text{LLM}(A_ i) $
where $f_ {A,i} \in \mathbb{R}^{d_ {LLM}} $.
This augmented representation is then used to refine the item’s embedding in the recommendation model.
3.3 Conducting User Profiling
This strategy involves using LLMs to construct comprehensive user profiles based on historical interactions and inferred preferences.
- Notation:
- $ A_ u $: Augmented attributes for user $ u $
- $ f_ {A,u} $: LLM-generated feature representation of user $ u $
-
Explanation: LLMRec generates user profiles using historical interaction data and side information. The LLM is used to predict missing user attributes (ex., age, gender, preferred genres) based on interaction history and other contextual information.
The final user profile representation is defined as:
$ f_ {A,u} = \text{LLM}(A_ u) $
where $ f_ {A,u} \in \mathbb{R}^{d_ {LLM}} $.
This enables LLMRec to fill in gaps in user profiles, especially when explicit user information is incomplete or missing.
3.4 Incorporating Augmented Data into the Model
The augmented interaction edges and node features are integrated into the collaborative filtering framework to form the final user and item embeddings.
-
Optimization Objective for Augmenting Side Information: To handle data sparsity and side information, the model maximizes the posterior probability of the embeddings $ \Theta = \lbrace E_u, E_i, F_ {\theta} \rbrace $ given both the original graph edges $ E^+ $ and the side information $ F $. This is formulated as:
$ \Theta^{*} = \arg\max_ \Theta \, p(\Theta \mid F, E^+) $
where $ F $ refers to the side information used in the feature graph, and the function $ f_ {\theta} $ combines the signals from both the feature set $ F $ and user-item interactions.
-
Recommendation with Data Augmentation: After augmenting both the side information and the interaction graph, the full optimization objective for LLMRec is:
$ \Theta^{*} = \arg\max_ \Theta \, p(\Theta \mid \lbrace F, F_ A \rbrace, \lbrace E^+, E_ A \rbrace ) $
where:
- $ \Theta $: Model parameters
- $ F $: Original feature set
- $ E^+ $: Original interaction set
- $ F_ A $ and $ E_ A $: Augmented feature set and interaction set generated by LLMRec
The final representation for each user $ u $ and item $ i $ is a combination of the original and augmented data, which is used to predict the likelihood of user $ u $ interacting with item $ i $.
4. Experiment
In this section, the authors present the experimental results of the proposed LLMRec framework. The authors evaluate its performance on two benchmark datasets using various evaluation metrics and compare it against state-of-the-art baselines. The study addresses the following five research questions (RQs) to comprehensively analyze the effectiveness of LLMRec:
RQ1: How does LLMRec perform compared to existing collaborative filtering and data augmentation methods? RQ2: What is the effect of LLM-based graph augmentation on the recommendation quality? RQ3: How do different components of LLMRec contribute to its overall performance? RQ4: How sensitive is LLMRec to different hyperparameter settings? RQ5: Is LLMRec’s data augmentation strategy generalizable to other recommendation models?
4.1 Experimental Setup
Datasets The authors conducted experiments using two publicly available datasets: Netflix and MovieLens-10M, each chosen to highlight the performance of LLMRec in scenarios with diverse side information. The Netflix dataset is derived from the Netflix Prize Data available on Kaggle and the MovieLens-10M dataset is derived from the ML-10M dataset. Both datasets include multi-modal side information, such as textual and visual features:
- Netflix: Contains 13,187 users, 17,366 items, and 68,933 user-item interactions. The side information includes textual attributes (ex., titles, genres) and visual features extracted using the CLIP-ViT model.
- MovieLens: Consists of 12,495 users, 10,322 items, and 57,960 interactions. The side information includes textual data (titles, genres, and release years) and visual content of movie posters, encoded using the CLIP model.
LLM-based Data Augmentation LLMRec utilizes the OpenAI GPT-3.5-turbo-0613 model for generating new user-item interactions, item attributes, and user profiles. The augmented item attributes include details such as director, country, and language, while user profiles are inferred from historical interactions and further enhanced with attributes like age, gender, liked genres, and disliked genres. Embedding generation is performed using the text-embedding-ada-002 model, allowing LLMRec to transform textual information into dense vectors suitable for integration within the graph.
Baselines The authors compared LLMRec against a diverse set of baseline models to evaluate its effectiveness:
- General Collaborative Filtering Methods:
- MF-BPR: Matrix Factorization optimized for implicit feedback.
- NGCF: Neural Graph Collaborative Filtering that captures high-order user-item interactions using GNNs.
- LightGCN: A simplified GNN model for collaborative filtering with lightweight propagation layers.
- Methods with Side Information:
- VBPR: A visual-based Bayesian personalized ranking model using visual features of items.
- MMGCN: A multi-modal GCN model incorporating both textual and visual features.
- GRCN: A GCN-based method that utilizes item-end content for high-order content-aware relationships.
- Data Augmentation Methods:
- LATTICE: Uses data augmentation by establishing item-item relationships based on content similarity.
- MICRO: A multi-modal content recommendation framework that leverages self-supervised learning for data augmentation.
- Self-supervised Methods:
- CLCRec: Contrastive learning-based collaborative filtering model using self-supervision to improve representations.
- MMSSL: A multi-modal self-supervised learning model maximizing mutual information between content-augmented views.
Implementation Details The experiments are implemented in PyTorch and run on a 24 GB Nvidia RTX 3090 GPU. The AdamW optimizer is employed for training, with learning rates set within a range of [5𝑒−5, 1𝑒−3] for Netflix and [2.5𝑒−4, 9.5𝑒−4] for MovieLens. Temperature and top-p parameters are set within ranges {0.0, 0.6, 0.8, 1} and {0.0, 0.1, 0.4, 1}, respectively, to control LLM-generated content. For comparison, the researchers use a unified embedding size of 64 for all methods.
Evaluation Metrics The authors evaluate LLMRec using three common metrics: Recall@K (R@K), Normalized Discounted Cumulative Gain@K (N@K), and Precision@K (P@K), with K set to 10, 20, and 50. The authors employ an all-ranking strategy to avoid potential biases, and results are averaged over five independent runs to ensure statistical significance.
4.2 Experimental Results
The authors address the stated research questions through a detailed analysis of the experimental results:
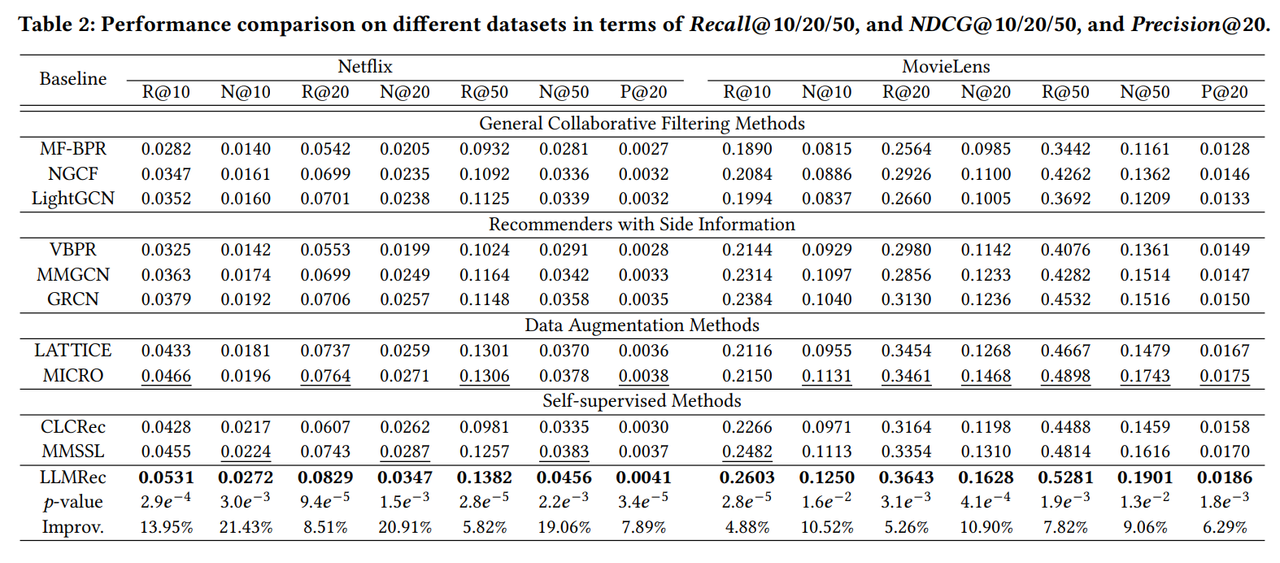
RQ1: How does LLMRec perform compared to existing collaborative filtering and data augmentation methods? LLMRec demonstrates superior performance over all baseline methods on both Netflix and MovieLens datasets, achieving the highest Recall@K, NDCG@K, and Precision@K scores. This indicates that LLMRec’s ability to generate high-quality and contextually relevant user-item interactions significantly improves recommendation accuracy. The results, summarized in Table 2, show a notable improvement over general collaborative filtering methods like NGCF and LightGCN, and over state-of-the-art data augmentation methods like LATTICE and MICRO.
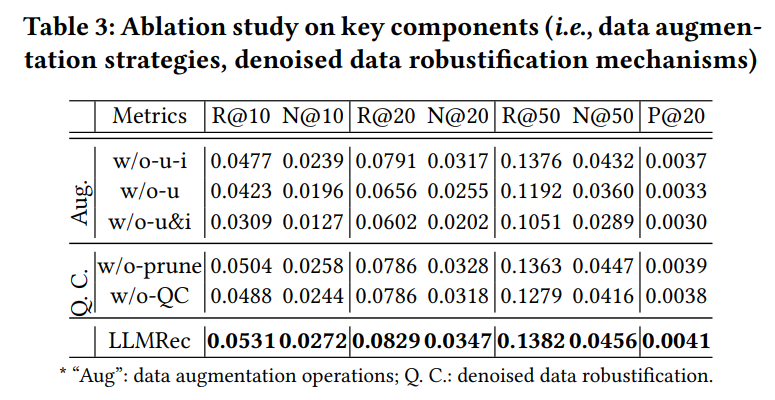
RQ2: What is the effect of LLM-based graph augmentation on the recommendation quality? The results in Table 3 show that LLM-based augmentation provides a substantial performance boost compared to models without graph augmentation. By generating new interactions and enriching side information, LLMRec effectively mitigates data sparsity and low-quality side information issues. This validates that augmenting graphs using LLMs enhances the model’s ability to capture richer patterns in user preferences and item attributes.
RQ3: How do different components of LLMRec contribute to its overall performance? Ablation study was conducted to understand the contributions of each component. As shown in Table 4, removing LLM-augmented user-item interactions causes a drastic performance drop, indicating that these interactions are crucial for capturing diverse user preferences. Similarly, removing user or item profiling results in lower accuracy, underscoring the importance of using LLMs to enhance side information.
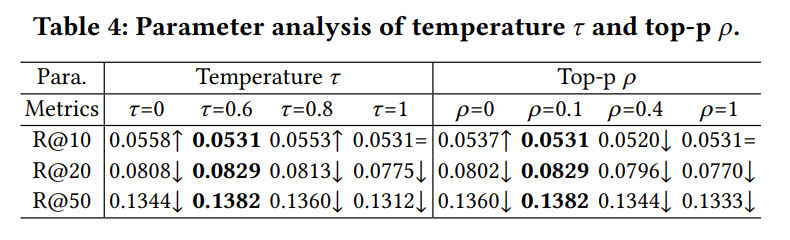
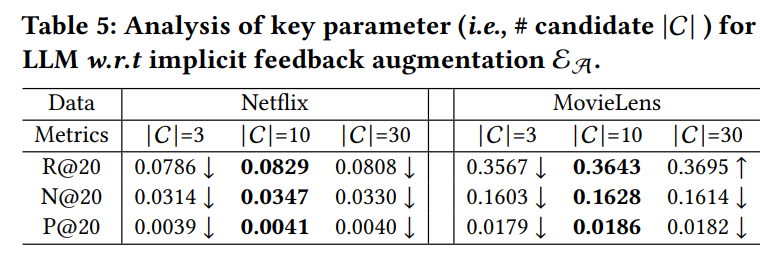
RQ4: How sensitive is LLMRec to different hyperparameter settings? The sensitivity analysis (Table 5) reveals that LLMRec’s performance is particularly sensitive to the temperature (𝜏) and top-p parameters of the GPT-3.5-turbo model. The best performance is achieved with 𝜏 = 0.6 and top-p = 0.1, indicating that a moderate level of randomness and diversity in the generated content is ideal. Additionally, the authors found that a candidate pool size of |C| = 10 balances selection diversity and computational efficiency, ensuring high-quality rankings.
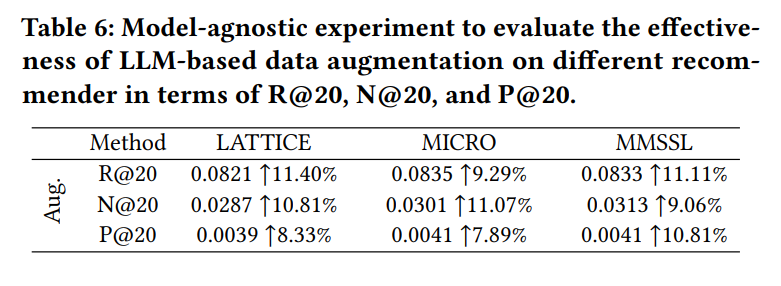
RQ5: Is LLMRec’s data augmentation strategy generalizable to other recommendation models? The research team integrated LLMRec’s augmented data into other recommendation models such as LATTICE, MICRO, and MMSSL, as shown in Table 6. All models benefit significantly from the augmented data, demonstrating that LLMRec’s data augmentation strategy is effective and generalizable across different model architectures. This highlights the potential of LLM-generated data as a versatile tool to improve recommendation quality in various contexts.
5. Conclusion
This paper presents LLMRec, a novel framework that enhances recommendation systems by leveraging Large Language Models (LLMs) for graph augmentation. Unlike traditional methods that struggle with data sparsity and low-quality side information, LLMRec enriches the interaction graph with high-quality augmented data using LLMs. What stands out to me is how the framework shifts from an ID-based recommendation paradigm to a modality-based one, leveraging natural language understanding to create new user-item interaction edges and profile users and items more comprehensively.
One key takeaway is LLMRec’s hybrid approach—utilizing LLMs as data augmentors rather than replacing conventional models. This approach retains the strengths of existing collaborative filtering methods while enriching them with the rich contextual knowledge provided by LLMs. The authors also address the challenge of noisy or incomplete data with robust augmentation strategies, including denoised data robustification and feature enhancement, ensuring the reliability of the augmented information.
Reflecting on the paper, I find the use of LLMs as enhancers rather than direct recommenders particularly interesting. It suggests that the real value of LLMs in recommendation lies in their ability to understand and augment data, not just replace models. This insight opens the door for future research to explore more sohpisticated and nuanced integration strategies between LLMs and traditional recommendation architectures.
Overall, I think that the proposed model, LLMRec, effectively bridges the gap between language models and recommendation systems, setting a precedent for future studies. By creatively using LLMs to overcome long-standing challenges, this paper provides a strong foundation for developing next-generation recommendation systems that are both effective and contextually aware. In addition, I also think that it would be interesting to explore this model with the updated versions of the LLM models from OpenAI.
Author Information
- Author name: Jeongho Kim
- Affiliation: KAIST Department of Industrial and Systems Engineering
- Research Topic: Human Behavior Modelling, Injury Prevention
6. Reference & Additional materials
- Github Implementation
https://github.com/HKUDS/LLMRec.git - Reference
[1] Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. arXiv preprint arXiv:2305.00447 (2023). [2] Chong Chen, Weizhi Ma, Min Zhang, et al. 2023. Revisiting negative sampling vs. non-sampling in implicit recommendation. TOIS 41, 1 (2023), 1–25. [3] Chong Chen, Min Zhang, Yongfeng Zhang, et al. 2020. Efficient neural matrix factorization without sampling for recommendation. TOIS 38, 2 (2020), 1–28. [4] Mengru Chen, Chao Huang, Lianghao Xia, Wei Wei, et al. 2023. Heterogeneous graph contrastive learning for recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 544–552. [5] Zheng Chen. 2023. PALR: Personalization Aware LLMs for Recommendation. arXiv preprint arXiv:2305.07622 (2023). [6] Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongxiang Sun, Xiao Zhang, and Jun Xu. 2023. Uncovering ChatGPT’s Capabilities in Recommender Systems. arXiv preprint arXiv:2305.02182 (2023). [7] Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019. Graph neural networks for social recommendation. In ACM International World Wide Web Conference. 417–426. [8] Xinyu Fu, Jiani Zhang, et al. 2020. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In ACM International World Wide Web Conference. 2331–2341. [9] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2022. Masked autoencoders are scalable vision learners. In CVPR. 16000–16009. [10] Ruining He and Julian McAuley. 2016. VBPR: visual bayesian personalized ranking from implicit feedback. In AAAI, Vol. 30. [11] Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 639–648. [12] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751 (2019). [13] Tinglin Huang, Yuxiao Dong, Ming Ding, Zhen Yang, Wenzheng Feng, Xinyu Wang, and Jie Tang. 2021. MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining. [14] Wang-Cheng Kang, Jianmo Ni, Nikhil Mehta, Maheswaran Sathiamoorthy, Lichan Hong, et al. 2023. Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. arXiv preprint arXiv:2305.06474 (2023). [15] Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. A survey of recommendation systems: recommendation models, techniques, and application fields. Electronics 11, 1 (2022), 141. [16] Dongha Lee, SeongKu Kang, Hyunjun Ju, et al. 2021. Bootstrapping user and item representations for one-class collaborative filtering. In ACM SIGIR Conference on Research and Development in Information Retrieval. 317–326. [17] Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. 2023. Text Is All You Need: Learning Language Representations for Sequential Recommendation. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining. [18] Jinming Li, Wentao Zhang, Tian Wang, Guanglei Xiong, et al. 2023. GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation. arXiv preprint arXiv:2304.03879 (2023). [19] Ke Liang, Yue Liu, Sihang Zhou, Wenxuan Tu, Yi Wen, Xihong Yang, Xiangjun Dong, and Xinwang Liu. 2023. Knowledge Graph Contrastive Learning Based on Relation-Symmetrical Structure. IEEE Transactions on Knowledge and Data Engineering (2023), 1–12. https://doi.org/10.1109/TKDE.2023.3282989 [20] Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, and Xinwang Liu. 2023. Learn from relational correlations and periodic events for temporal knowledge graph reasoning. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval Conference on Research and Development in Information Retrieval. 1559–1568. [21] Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, Xinwang Liu, and Fuchun Sun. 2022. Reasoning over different types of knowledge graphs: Static, temporal and multi-modal. arXiv preprint arXiv:2212.05767 (2022). [22] Ke Liang, Sihang Zhou, Yue Liu, Lingyuan Meng, Meng Liu, and Xinwang Liu. 2023. Structure Guided Multi-modal Pre-trained Transformer for Knowledge Graph Reasoning. arXiv preprint arXiv:2307.03591 (2023). [23] Zhiwei Liu, Yongjun Chen, Jia Li, Philip S Yu, Julian McAuley, and Caiming Xiong. 2021. Contrastive self-supervised sequential recommendation with robust augmentation. arXiv preprint arXiv:2108.06479 (2021). [24] Zhiwei Liu, Ziwei Fan, et al. 2021. Augmenting sequential recommendation with pseudo-prior items via reversely pre-training transformer. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1608–1612. [25] Ilya Loshchilov et al. 2017. Decoupled weight decay regularization. In ICLR. [26] Chang Meng, Chenhao Zhai, Yu Yang, Hengyu Zhang, and Xiu Li. 2023. Parallel Knowledge Enhancement based Framework for Multi-behavior Recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1797–1806. [27] Chang Meng, Hengyu Zhang, Wei Guo, Huifeng Guo, Haotian Liu, Yingxue Zhang, Hongkun Zheng, Ruiming Tang, Xiu Li, and Rui Zhang. 2023. Hierarchical Projection Enhanced Multi-Behavior Recommendation. In Proceedings of the 29th ACM SIGACM SIGKDD Conference on Knowledge Discovery and Data Mining Conference on Knowledge Discovery and Data Mining. 4649–4660. [28] Chang Meng, Ziqi Zhao, Wei Guo, Yingxue Zhang, Haolun Wu, Chen Gao, Dong Li, Xiu Li, and Ruiming Tang. 2023. Coarse-to-fine knowledge-enhanced multi-interest learning framework for multi-behavior recommendation. ACM Transactions on Information Systems 42, 1 (2023), 1–27. [29] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Conference on Neural Information Processing Systems 32 (2019). [30] Aleksandr Petrov and Craig Macdonald. 2022. Effective and Efficient Training for Sequential Recommendation using Recency Sampling. In Recsys. 81–91. [31] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. Learning transferable visual models from natural language supervision. In ICML. PMLR, 8748–8763. [32] Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2023. Representation Learning with Large Language Models for Recommendation. arXiv preprint arXiv:2310.15950 (2023). [33] Xubin Ren, Lianghao Xia, Yuhao Yang, Wei Wei, Tianle Wang, Xuheng Cai, and Chao Huang. 2023. SSLRec: A Self-Supervised Learning Library for Recommendation. arXiv preprint arXiv:2308.05697 (2023). [34] Steffen Rendle, Christoph Freudenthaler, et al. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012). [35] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2023. GraphGPT: Graph Instruction Tuning for Large Language Models. arXiv preprint arXiv:2310.13023 (2023). [36] Yijun Tian, Kaiwen Dong, Chunhui Zhang, Chuxu Zhang, and Nitesh V Chawla. 2023. Heterogeneous graph masked autoencoders. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 9997–10005. [37] Yijun Tian, Shichao Pei, Xiangliang Zhang, Chuxu Zhang, and Nitesh V Chawla. 2023. Knowledge Distillation on Graphs: A Survey. arXiv preprint arXiv:2302.00219 (2023). [38] Yijun Tian, Huan Song, Zichen Wang, Haozhu Wang, Ziqing Hu, Fang Wang, Nitesh V Chawla, and Panpan Xu. 2023. Graph neural prompting with large language models. arXiv preprint arXiv:2309.15427 (2023). [39] Yijun Tian, Chuxu Zhang, Zhichun Guo, Xiangliang Zhang, and Nitesh Chawla. 2022. Learning mlps on graphs: A unified view of effectiveness, robustness, and efficiency. In The Eleventh International Conference on Learning Representations. [40] Wenjie Wang, Fuli Feng, Xiangnan He, Liqiang Nie, and Tat-Seng Chua. 2021. Denoising implicit feedback for recommendation. In WSDM. 373–381. [41] Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. In ACM SIGIR Conference on Research and Development in Information Retrieval. 165–174. [42] Xiaolei Wang, Xinyu Tang, Wayne Xin Zhao, Jingyuan Wang, and Ji-Rong Wen. 2023. Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models. arXiv preprint arXiv:2305.13112 (2023). [43] Zhenlei Wang, Jingsen Zhang, Hongteng Xu, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. Counterfactual data-augmented sequential recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 347–356. [44] Wei Wei, Chao Huang, Lianghao Xia, Yong Xu, Jiashu Zhao, and Dawei Yin. 2022. Contrastive meta learning with behavior multiplicity for recommendation. In Proceedings of the fifteenth ACM international conference on web search and data mining. 1120–1128. [45] Wei Wei, Chao Huang, Lianghao Xia, and Chuxu Zhang. 2023. Multi-Modal Self-Supervised Learning for Recommendation. In ACM International World Wide Web Conference. 790–800. [46] Wei Wei, Lianghao Xia, and Chao Huang. 2023. Multi-Relational Contrastive Learning for Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems. 338–349. [47] Yinwei Wei, Xiang Wang, et al. 2021. Hierarchical user intent graph network for multimedia recommendation. Transactions on Multimedia (TMM) (2021). [48] Yinwei Wei, Xiang Wang, Qi Li, Liqiang Nie, Yan Li, et al. 2021. Contrastive learning for cold-start recommendation. In ACM MM. 5382–5390. [49] Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, and Tat-Seng Chua. 2020. Graph-refined convolutional network for multimedia recommendation with implicit feedback. In MM. 3541–3549. [50] Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In MM. 1437–1445. [51] Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, et al. 2021. Selfsupervised graph learning for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 726–735. [52] Zixuan Yi, Xi Wang, Iadh Ounis, and Craig Macdonald. 2022. Multi-modal Graph Contrastive Learning for Micro-video Recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1807–1811. [53] Yuxin Ying, Fuzhen Zhuang, Yongchun Zhu, Deqing Wang, and Hongwei Zheng. 2023. CAMUS: Attribute-Aware Counterfactual Augmentation for Minority Users in Recommendation. In ACM International World Wide Web Conference. 1396–1404. [54] Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? Simple graph contrastive learning for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1294–1303. [55] Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id-vs. modality-based recommender models revisited. In ACM SIGIR Conference on Research and Development in Information Retrieval. [56] Honglei Zhang, Fangyuan Luo, Jun Wu, Xiangnan He, and Yidong Li. 2023. LightFR: Lightweight federated recommendation with privacy-preserving matrix factorization. ACM Transactions on Information Systems 41, 4 (2023), 1–28. [57] Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2023. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001 (2023). [58] Jinghao Zhang, Yanqiao Zhu, Qiang Liu, et al. 2022. Latent structure mining with contrastive modality fusion for multimedia recommendation. TKDE (2022). [59] Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Shu Wu, et al. 2021. Mining Latent Structures for Multimedia Recommendation. In MM. 3872–3880. [60] Shengyu Zhang, Dong Yao, Zhou Zhao, et al. 2021. Causerec: Counterfactual user sequence synthesis for sequential recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 367–377. [61] Ding Zou, Wei Wei, Xian-Ling Mao, Ziyang Wang, Minghui Qiu, Feida Zhu, and Xin Cao. 2022. Multi-level cross-view contrastive learning for knowledge-aware recommender system. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1358–1368.