[SIGIR-24] Diffusion Models for Generative Outfit Recommendation
1. Problem Definition
패션 도메인에서 사용자에게 맞춤형 코디를 추천하는 것은 매우 중요한 과제입니다. 기존의 코디 추천 시스템은 두 가지 접근 방식으로 나뉩니다. 첫 번째는 Pre-defined Outfit Recommendation (POR) 으로, 이미 잘 구성된 코디 세트를 사용자에게 추천하는 방식입니다. 하지만 이러한 방식은 이미 존재하는 한정된 코디 세트로만 추천이 이루어지므로, 사용자 개인의 다양하고 세부적인 패션 요구를 충족시키기에는 한계가 있습니다.
두 번째는 Personalized Outfit Composition (POC) 방식으로, 개별 패션 아이템을 검색하여 이를 조합해 사용자가 선호할 만한 코디를 구성하는 방법입니다. 이 접근 방식은 기존의 POR보다 사용자 맞춤형 추천을 제공할 수 있지만, 여전히 기존의 패션 제품들로만 코디를 구성해야 한다는 제한이 있으며, 이는 사용자가 원하는 스타일, 색상, 패턴과 완벽히 일치하지 않을 가능성이 높습니다.
본 논문에서는 이러한 한계를 극복하고자 새로운 과제인 Generative Outfit Recommendation (GOR) 을 제안합니다. GOR의 목표는 기존의 패션 아이템에만 의존하지 않고, 사용자의 취향에 맞춰 새롭게 생성된 패션 제품들을 기반으로 코디를 구성하여 추천하는 것입니다.
2. Motivation
기존의 코디 추천 시스템은 크게 두 가지 문제를 가지고 있습니다. 첫 번째로, POR은 이미 만들어진 코디 세트를 사용자에게 추천하는 방식으로, 사용자 취향에 맞춘 다양성을 제공하는 데 한계가 있습니다. 기존의 연구들은 사용자가 선호하는 스타일과 일치하는 코디를 제안하기 위해 코디 데이터베이스를 활용하거나, Content-based Filtering 또는 Collaborative Filtering 기법을 사용해왔습니다. 하지만 이러한 방식들은 데이터베이스에 이미 존재하는 패션 제품에 의존할 수밖에 없기 때문에, 사용자 맞춤형 코디를 세밀하게 제안하는 데 어려움이 있습니다.
두 번째로, POC은 개별 아이템들을 조합하여 사용자에게 맞춤형 코디를 제안하는 접근 방식입니다. 이를 통해 어느 정도의 개인화는 이루어지지만, 기존 패션 아이템들로만 제한된 조합을 제공하기 때문에 사용자가 원하는 특정 디자인이나 패턴을 충족시키기에는 부족할 수 있습니다.
본 논문에서 제안하는 DiFashion 모델은 이러한 문제를 해결하기 위해 Diffusion Models (DMs) 을 기반으로 패션 이미지를 생성하는 새로운 접근 방식을 채택했습니다. DiFashion은 기존의 패션 아이템에 국한되지 않고, 사용자 취향에 맞춰 새로운 패션 아이템을 생성하고 이들로 구성된 코디를 추천할 수 있습니다. 이를 통해 사용자의 개별적 취향을 더 정밀하게 반영한 맞춤형 코디를 제공할 수 있으며, high fidelity, comparibility, 그리고 personalized된 추천을 실현할 수 있습니다. 이는 기존의 추천 시스템들이 직면한 한계를 넘어, 패션 도메인에서 더욱 진화된 추천 경험을 제공할 수 있음을 의미합니다.
3. Preliminary
Diffusion Models (DMs) 은 이미지 합성을 위한 강력한 방법으로, 마르코프 체인을 기반으로 이미지에 점진적으로 노이즈를 추가하는 forward process와 노이즈를 제거하여 이미지를 복원하는 reverse process로 구성됩니다.
-
Forward Process: 주어진 이미지 $\mathbf{x}_ 0 \sim q(\mathbf{x}_ 0)$에 가우시안 노이즈를 단계적으로 추가하여 이미지를 점진적으로 파괴합니다. $ q(\mathbf{x}_ t \vert \mathbf{x}_ {t-1}) = \mathcal{N}(\mathbf{x}_ t; \sqrt{1 - \beta_ t} \mathbf{x}_ {t-1}, \beta_ t \mathbf{I}) $ 여기서 $\beta_ t 는 각 단계 $t$에서 추가되는 노이즈의 크기를 제어하며, $t = 1, \dots, T$ 입니다. $T$가 커질수록 이미지 $\mathbf{x}_ T$는 가우시안 노이즈로 수렴하게 됩니다.
-
Reverse Process: 시작 이미지가 순수한 노이즈 $\mathbf{x}_ T \sim \mathcal{N}(0, \mathbf{I})$일 때, 노이즈 제거 과정을 통해 원본 이미지를 복원합니다. $ p_ \theta(\mathbf{x}_ {t-1} \vert \mathbf{x}_ t) = \mathcal{N}(\mathbf{x}_ {t-1}; \mu_ \theta(\mathbf{x}_ t, t), \Sigma_ \theta(\mathbf{x}_ t, t)) $ 여기서 $\mu_ \theta$와 $\Sigma_ \theta$는 신경망으로 학습된 평균과 공분산입니다. 이 과정에서 학습 목표는 원래 이미지와 유사한 이미지를 점진적으로 생성하는 것입니다.
-
최적화: DMs는 다음 손실 함수를 통해 학습됩니다. $ L_ \theta = \mathbb{E}_ {t, \epsilon \sim \mathcal{N}(0, \mathbf{I})} \left[ \Vert \epsilon - \epsilon_ \theta(\mathbf{x}_ t, t) \Vert_ 2^2 \right] $ 여기서 $\epsilon_ \theta$는 노이즈 예측 모델이며, $t$는 무작위로 샘플링된 시점입니다.
-
이미지 생성: 학습이 완료된 후, DMs는 순수한 노이즈에서 시작하여 단계별로 노이즈를 제거하며 이미지를 생성합니다.
4.1 Task Formulation
Generative Outfit Recommendation (GOR) 는 사용자의 개인 취향에 맞는 시각적으로 호환되는 새로운 패션 제품 이미지를 생성하여 코디를 구성하는 과제입니다. 공식적으로, 주어진 사용자 정보 $\mathbf{u}$ (예: 상호작용 내역, 사용자 특징)를 기반으로 $n$개의 패션 아이템 $\mathcal{O} = { \mathbf{i}_ k }_ {k=1}^n$을 생성하는 문제로 정의됩니다. 여기서 각 아이템 $\mathbf{i}_ k$는 아래 최적화 문제를 만족해야 합니다: $ \mathbf{u},\mathbf{\emptyset} \rightarrow \mathcal{O}={\mathbf{i}_ k}_ {k=1}^n $ $ \text{s.t. } \mathbf{i}_ k = \arg\max_ {\mathbf{i}} P_ \theta(\mathbf{i} \vert \mathcal{O}_ k’, \mathbf{u}), \quad k = 1, \dots, n $ 여기서 $\mathcal{O}_ k’ = \mathcal{O} \setminus { \mathbf{i}_ k }$는 불완전한 코디이며, $P_ \theta(\cdot)$는 각 아이템의 조건부 생성 확률을 나타냅니다.
하지만 이 문제는 시작점이 명확하지 않고, 최적화 과정 중 계속 변하는 제약 조건 때문에 직접 풀기 어렵습니다. 따라서 이 문제를 해결하기 위해 순차적으로 생성하는 방식이 아닌, 여러 이미지를 병렬로 생성하는 방식으로 문제를 변환합니다. 이 과정에서 $\mathcal{O}_ T = { \mathbf{i}_ {k,T} }_ {k=1}^n$은 순수한 가우시안 노이즈에서 시작하여 각 단계 $t$에서 이미지를 생성하는 방식으로 문제를 해결할 수 있습니다.
4.2 DiFashion
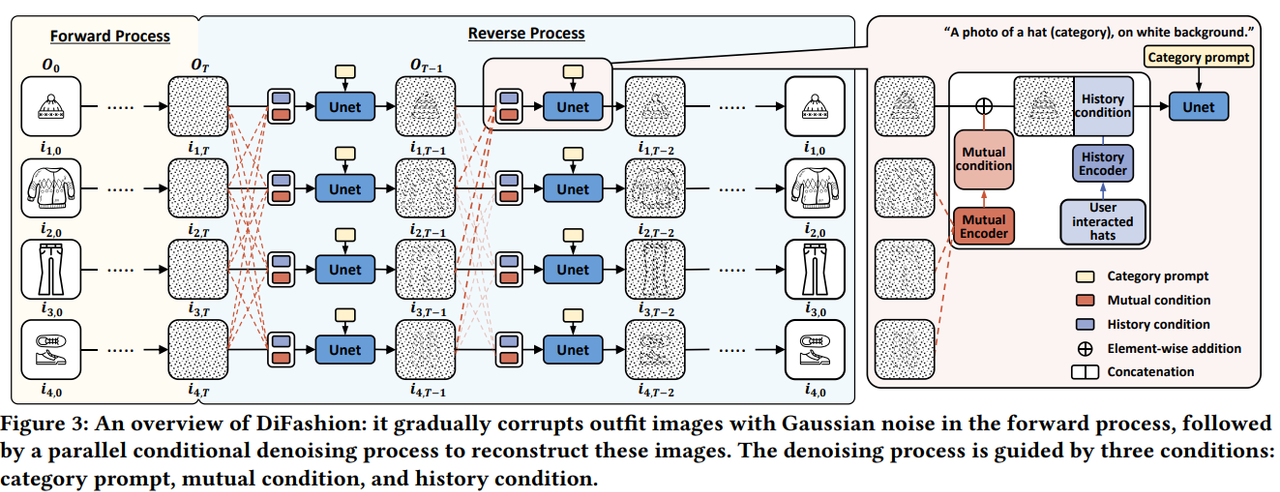
DiFashion은 사용자 정보에 기반해 다수의 패션 이미지를 병렬로 생성하여 코디를 구성하는 generative outfit recommender model입니다. 이 모델은 두 가지 중요한 과정을 포함합니다:
-
Forward Process: 코디 이미지를 가우시안 노이즈로 점진적으로 파괴합니다. 각 이미지 $\mathbf{i}_ {k,t}$는 서로 독립적으로 노이즈가 추가됩니다. $ q(\mathcal{O}_ t \vert \mathcal{O}_ {t-1}) = \prod_ {k=1}^n q(\mathbf{i}_ {k,t} \vert \mathbf{i}_ {k,t-1}) = \prod_ {k=1}^n \mathcal{N}(\mathbf{i}_ {k,t}; \sqrt{1 - \beta_ t} \mathbf{i}_ {k,t-1}, \beta_ t \mathbf{I}) $
-
Reverse Process: DiFashion의 reverse process는 순수한 노이즈 $\mathcal{O}_ T = { \mathbf{i}_ {k,T} }_ {k=1}^n$에서 시작하여, 각 패션 아이템 이미지를 병렬로 복원하는 과정입니다. U-Net을 기반으로 하는 이 과정은 각 패션 아이템이 고유의 조건들에 맞게 복원될 수 있도록 설계되었습니다. Reverse process는 다음과 같은 확률 분포로 정의됩니다:
$ p_ \theta(\mathcal{O}_ {t-1} \vert \mathcal{O}_ t) = \prod_ {k=1}^n p_ \theta(\mathbf{i}_ {k,t-1} \vert \mathcal{O}_ t) $
각 아이템에 대한 복원 과정은 다음과 같이 노이즈를 제거하는 가우시안 분포로 표현됩니다:
$ p_ \theta(\mathbf{i}_ {k,t-1} \vert \mathcal{O}_ t) = \mathcal{N}(\mathbf{i}_ {k,t-1}; \mu_ \theta(\mathcal{O}_ t, t), \Sigma_ \theta(\mathcal{O}_ t, t)) $
여기서 $\mu_ \theta$와 $\Sigma_ \theta$는 U-Net을 통해 학습된 평균과 공분산입니다. Reverse process는 $T$부터 0까지 점진적으로 진행되며, 점점 더 노이즈가 제거된 패션 아이템 이미지를 생성합니다.
Condition Encoders
DiFashion은 패션 아이템을 복원할 때 세 가지 중요한 조건을 활용합니다:
- Category Prompt: 각 아이템의 카테고리를 보장하는 텍스트 기반 조건입니다. 예를 들어 “A photo of a hat, on white background”와 같은 문장이 주어집니다.
- Mutual Condition: 동일한 코디 내 다른 아이템들과의 호환성을 보장하는 조건입니다. 복원 중인 아이템의 호환성을 유지하기 위해 다른 아이템의 정보가 사용됩니다.
- History Condition: 사용자의 과거 상호작용 데이터를 활용하여, 해당 사용자의 패션 취향을 반영한 개인화된 조건입니다.
이 세 가지 조건을 reverse process에서 동시에 적용하여 복원 과정을 효과적으로 이끌어 갑니다.
Mutual Encoder
Mutual encoder는 동일한 코디 내 다른 패션 아이템들의 호환성을 고려하여 복원 과정에 반영하는 역할을 합니다. 이를 위해 각 아이템 $\mathbf{i}_ {k,t}$는 나머지 아이템들의 평균 정보로부터 호환성 정보를 추출합니다. 이를 수식으로 표현하면 다음과 같습니다:
$ \mathcal{O}_ t’ = \mathcal{O}_ t \setminus { \mathbf{i}_ {k,t} } $
$ \mathbf{m}_ {k,t} = f_ \phi \left( \frac{1}{n-1} \sum_ {v \neq k} \mathbf{i}_ {v,t} \right) $
여기서 $f_ \phi$는 multi-layer perceptron (MLP)이며, 다른 아이템들의 평균 영향을 계산한 후 mutual condition $\mathbf{m}_ {k,t}$를 도출합니다. 이 mutual condition은 복원 중인 아이템에 다음과 같이 적용됩니다:
$ \mathbf{i}_ {k,t}^\text{mutual} = (1 - \eta) \cdot \mathbf{i}_ {k,t} + \eta \cdot \mathbf{m}_ {k,t} $
여기서 $\eta$는 mutual condition의 영향을 조절하는 가중치입니다. 이 방식으로 mutual encoder는 코디 내 아이템 간의 호환성을 높입니다.
History Encoder
History encoder는 사용자의 과거 상호작용 데이터를 바탕으로 개인화된 패션 아이템을 복원하는 역할을 합니다. 각 사용자 $u$의 상호작용 기록에서 해당 카테고리 $c_ k$에 대한 아이템들을 활용하여 history condition을 생성합니다:
$ \mathbf{u}_ {c_ k} = { \mathbf{i}_ {r}^{c_ k} }_ {r=1}^m $
이를 통해 각 상호작용 아이템을 잠재 공간으로 압축한 후 평균을 취하여 history condition $\mathbf{h}_ {c_ k}$를 계산합니다:
$ \mathbf{h}_ {c_ k} = \text{Avg}(E(\mathbf{u}_ {c_ k})) = \frac{1}{m} \sum_ {r=1}^m E(\mathbf{i}_ {r}^{c_ k}) $
여기서 $E$는 미리 학습된 인코더이며, $\mathbf{h}_ {c_ k}$는 해당 카테고리에서의 사용자 선호를 반영합니다. 이 history condition은 mutual condition과 결합되어 복원 과정에 사용됩니다:
$ [\mathbf{i}_ {k,t}^\text{mutual}, \mathbf{h}_ {c_ k}] $
이렇게 결합된 정보가 U-Net의 입력으로 사용되며, 이를 통해 사용자 취향에 맞는 맞춤형 복원이 이루어집니다.
Training
DiFashion의 학습 과정은 Stable Diffusion (SD)에서 사용하는 방식을 확장하여 세 가지 조건을 통합하는 방식으로 이루어집니다. 학습 목표는 U-Net이 각 아이템에 추가된 노이즈를 정확하게 예측하도록 하는 것입니다. 손실 함수는 다음과 같이 정의됩니다:
$ L_ {\theta, \phi} = \frac{1}{n} \sum_ {k=1}^n \mathbb{E}_ {t, \epsilon_ k \sim \mathcal{N}(0, \mathbf{I})} \left[ \vert \epsilon_ k - \epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \mathbf{m}_ {k,t}, \mathbf{h}_ {c_ k}, t) \vert_ 2^2 \right] $
여기서 $\epsilon_ {\theta, \phi}$는 노이즈 예측 모델이며, 학습 중 각 조건 (category prompt $\mathbf{t}_ {c_ k}$, mutual condition $\mathbf{m}_ {k,t}$, history condition $\mathbf{h}_ {c_ k}$)이 주어진 상황에서 노이즈를 제거하는 능력을 학습합니다. 학습 과정에서 각 조건은 무작위로 마스킹되며, 모델이 다양한 조건에 대해 잘 대응할 수 있도록 합니다.
Inference
학습이 완료된 후, DiFashion은 두 가지 주요 태스크를 수행할 수 있습니다:
- PFITB (Personalized Fill-In-The-Blank): 불완전한 코디에서 누락된 패션 아이템을 개인화된 방식으로 생성합니다. 주어진 카테고리 $c_ n$에 대한 category prompt $\mathbf{t}_ {c_ n}$, mutual condition $\mathbf{m}_ n$, history condition $\mathbf{h}_ {c_ n}$을 활용하여, 노이즈 $\mathbf{i}_ {n,T} \sim \mathcal{N}(0, \mathbf{I})$에서 시작해 아이템을 복원합니다.
- GOR (Generative Outfit Recommendation): 지정된 카테고리 ${c_ k}_ {k=1}^n$에 맞는 전체 코디를 생성합니다. 초기 노이즈 $\mathcal{O}_ T = { \mathbf{i}_ {k,T} }_ {k=1}^n$에서 시작해 mutual condition ${\mathbf{m}_ {k,T}}_ {k=1}^n$과 history condition ${\mathbf{h}_ {c_ k}}_ {k=1}^n$을 활용하여 모든 아이템을 복원합니다.
Inference 과정에서는 다음과 같은 수식을 통해 생성이 이루어집니다:
$ \tilde{\epsilon}_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \mathbf{m}_ {k,t}, \mathbf{h}_ {c_ k}, t) = \epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \emptyset, \emptyset, \emptyset, t) + s_ t \cdot [\epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \emptyset, \emptyset, t) - \epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \emptyset, \emptyset, \emptyset, t)] $
$ +s_ m \cdot [\epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \mathbf{m}_ {k,t}, \emptyset, t) - \epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \emptyset, \emptyset, t)] $
$ +s_ h \cdot [\epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \mathbf{m}_ {k,t}, \mathbf{h}_ {c_ k}, t) - \epsilon_ {\theta, \phi} (\mathbf{i}_ {k,t}, \mathbf{t}_ {c_ k}, \mathbf{m}_ {k,t}, \emptyset, t)] $
여기서 $s_ t$, $s_ m$, $s_ h$는 각 조건의 가이드 스케일이며, 이 값들은 inference 과정에서 최적화되어 각 조건이 적절히 반영된 이미지를 생성합니다. 아래의 이미지는 DiFashion의 Overall Structure입니다.
5. Experiments
DiFashion의 성능을 평가하기 위해 다양한 실험을 수행했습니다. 실험은 세 가지 주요 질문에 답하는 것을 목표로 합니다:
- RQ1: DiFashion은 PFITB (Personalized Fill-In-The-Blank)와 GOR (Generative Outfit Recommendation) 태스크에서 기존의 생성 모델 및 검색 기반 코디 추천 방법과 비교하여 어떤 성능을 보이는가?
- RQ2: DiFashion은 인간 평가 기준에서 기존 모델보다 더 나은 호환성과 개인화된 코디를 제공할 수 있는가?
- RQ3: DiFashion의 다양한 디자인 결정 (mutual influence ratio $\eta$, condition guidance scale $s_ t$, $s_ m$, $s_ h$)이 성능에 어떤 영향을 미치는가?
5.1 Experimental Settings
5.1.1 Datasets
- iFashion: 사전 정의된 코디 및 개별 패션 아이템으로 구성된 데이터셋으로, 사용자의 클릭 이력과 상호작용 내역을 포함합니다.
- Polyvore-U: Polyvore 웹사이트에서 수집된 데이터로, 다양한 코디와 사용자-코디 상호작용 데이터를 포함합니다.
두 데이터셋에서 사용자가 5개 이상의 상호작용을 한 경우만을 남겨 훈련, 검증, 테스트 세트로 나누어 사용했습니다.
5.1.2 Baselines
DiFashion의 성능을 평가하기 위해 다음과 같은 생성 모델 및 검색 기반 추천 시스템과 비교를 수행했습니다:
- Generative Models:
- OutfitGAN: 패션 이미지 생성을 위해 GAN을 사용하는 모델.
- Stable Diffusion v1.5 & v2: 텍스트 프롬프트 기반 이미지 생성을 위한 Stable Diffusion 모델.
- SD-naive: GOR 태스크에 SD를 단순하게 적용한 모델로, mutual condition 및 history condition을 활용하지만 MLP 없이 결합.
- ControlNet: 미리 학습된 DM에 공간적 조건을 추가해 패션 이미지를 생성.
- Retrieval-based Models:
- Random: 무작위로 패션 아이템을 선택하여 추천하는 단순 전략.
- HFN: 이진 코드로 사용자 및 콘텐츠 기반 추천을 수행하는 검색 기반 모델.
- HFGN: 그래프를 사용해 사용자-코디 상호작용을 모델링하여 추천하는 모델.
- BGN & BGN-Trans: LSTM 및 Transformer를 사용해 패션 아이템을 시퀀스 형태로 모델링하여 코디를 구성하는 모델.
5.1.3 Evaluation Metrics
DiFashion과 다른 모델들을 비교하기 위해 다음과 같은 정량적 평가 지표를 사용했습니다:
- Generative Metrics:
- FID (Frechet Inception Distance): 생성된 이미지와 실제 이미지 간의 거리를 측정하는 지표.
- IS (Inception Score): 이미지의 다채로움과 질을 평가.
- CLIP Score (CS): CLIP 모델을 사용하여 이미지와 텍스트 간의 일치도를 평가.
- IS-acc: 생성된 이미지의 카테고리 일치율을 나타내는 정확도.
- Fashion Metrics:
- CIS (CLIP Image Score): 생성된 이미지와 실제 이미지 간의 유사도를 평가.
- LPIPS (Learned Perceptual Image Patch Similarity): 지각적인 이미지 유사도를 평가하는 지표.
- Compatibility: OutfitGAN에서 사용된 호환성 평가기를 활용해 코디 내 아이템 간의 호환성을 평가.
- Personalization: 사용자가 상호작용한 아이템과 생성된 아이템 간의 개인화 정도를 평가.
- Retrieval Accuracy:
- PFITB 태스크에서는 생성된 아이템을 후보군에서 검색하는 정확도를 평가.
- GOR 태스크에서는 생성된 코디와 후보군 간의 유사성을 측정.
5.2 Quantitative Evaluation (RQ1)
5.2.1 Comparison with Generative Models
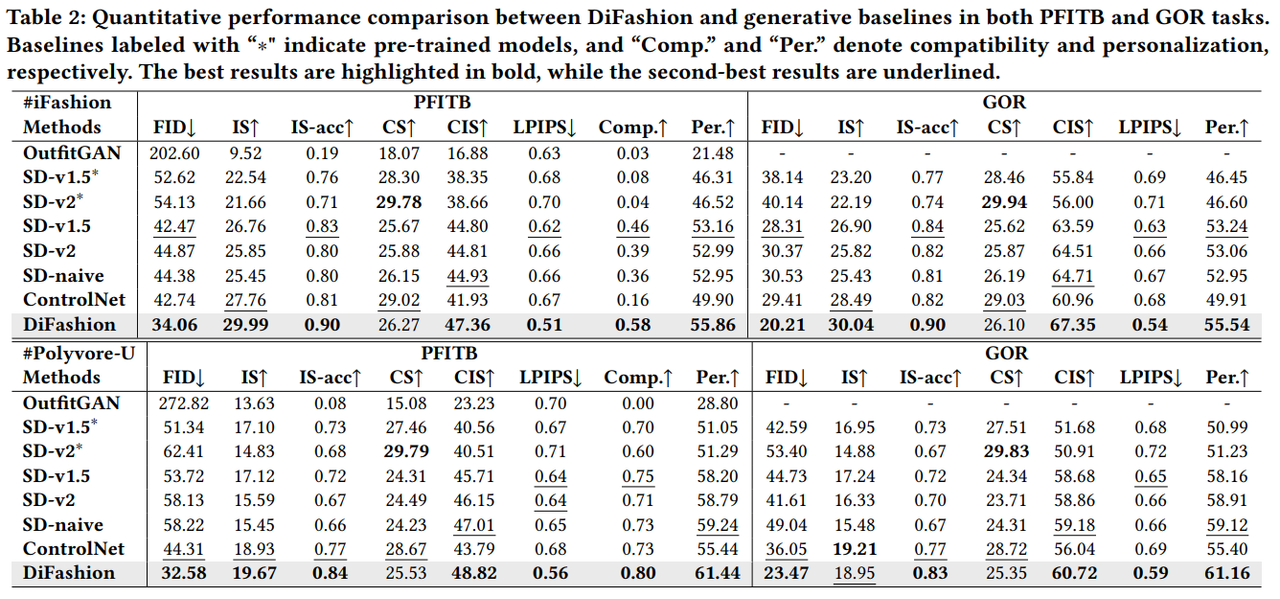
DiFashion은 PFITB와 GOR 태스크 모두에서 다른 생성 모델들과 비교했을 때 우수한 성능을 보였습니다. 다음과 같은 결과를 도출할 수 있었습니다:
- OutfitGAN은 생성된 이미지의 화질과 호환성 면에서 상대적으로 낮은 성능을 보였습니다.
- Stable Diffusion (v1.5 & v2) 는 iFashion 데이터셋에서 미세 조정 후, 더 높은 화질과 호환성을 보여줬지만, category prompt가 충분한 패션 디테일을 포함하지 못해 CLIP Score가 감소했습니다.
- SD-naive와 ControlNet은 mutual과 history 조건을 통합했지만, 성능이 DiFashion에 미치지 못했습니다. ControlNet의 경우, 사전 학습된 U-Net의 가중치를 고정하여 finetuning한 점에서 일반화 능력이 제한되었습니다.
- DiFashion은 대부분의 지표에서 우수한 성능을 기록했으며, 특히 호환성과 개인화 측면에서 가장 뛰어난 성과를 보였습니다.
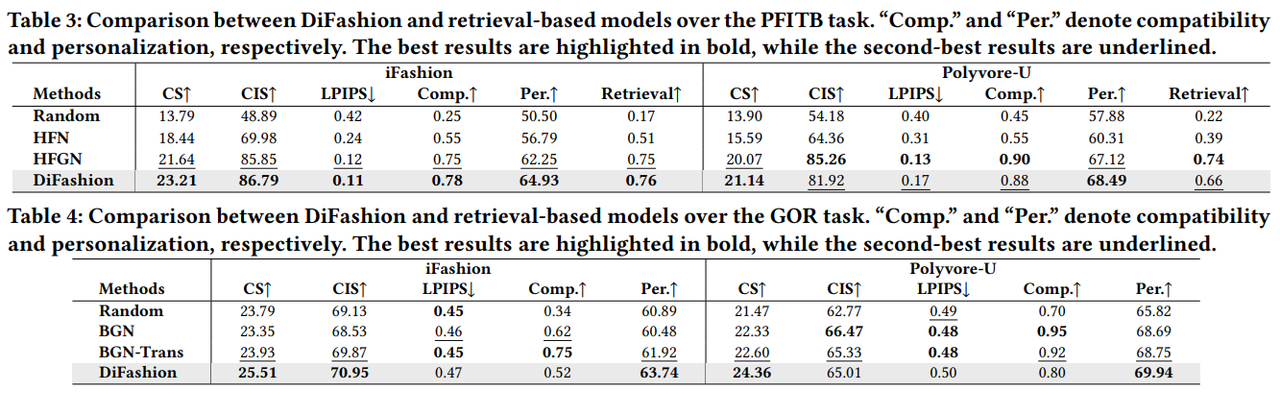
5.2.2 Comparison with Retrieval-based Models
검색 기반 모델과의 비교에서, DiFashion은 검색 태스크에서도 높은 성능을 보였습니다. PFITB 태스크에서는 검색 정확도에서 기존 모델들과 비슷하거나 더 나은 성능을 보여줬습니다. 특히 DiFashion은 개인화 및 호환성 측면에서 탁월한 성과를 나타내며, 실제 패션 제품을 생성하고 검색하는 데 실질적으로 적용 가능한 가능성을 확인했습니다.
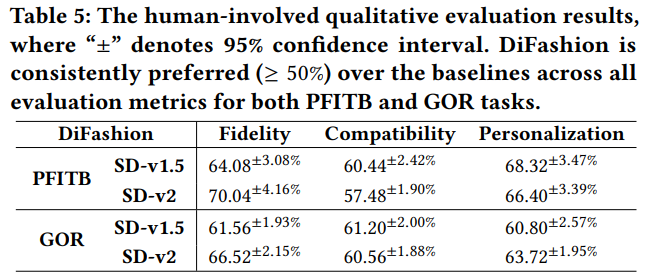
5.3 Human-involved Qualitative Evaluation (RQ2)
Human Evaluation은 DiFashion과 두 가지 Stable Diffusion 모델 (v1.5, v2)과 비교한 결과, DiFashion이 더 높은 화질, 호환성, 개인화를 제공한다고 판단했습니다. 이 평가는 Amazon Mechanical Turk에서 50개의 PFITB 및 GOR 사례를 바탕으로 수행되었으며, DiFashion은 항상 더 높은 선호도를 기록했습니다.
5.4 In-depth Analysis (RQ3)
5.4.1 Hyper-parameter Analysis
- Mutual Influence Ratio $\eta$: $\eta$ 값이 너무 작으면 호환성 지표가 저하되었으며, 너무 큰 값은 호환성이 지나치게 강조되어 다른 조건들의 영향을 감소시켰습니다.
- Guidance Scales $s_ t$, $s_ m$, $s_ h$: 세 가지 가이드 스케일을 변화시키며 성능을 분석한 결과, 각 조건의 적절한 가이드 스케일을 선택하는 것이 중요함을 확인했습니다. 특히 mutual condition의 가이드 스케일 $s_ m$은 호환성에 큰 영향을 미쳤습니다.
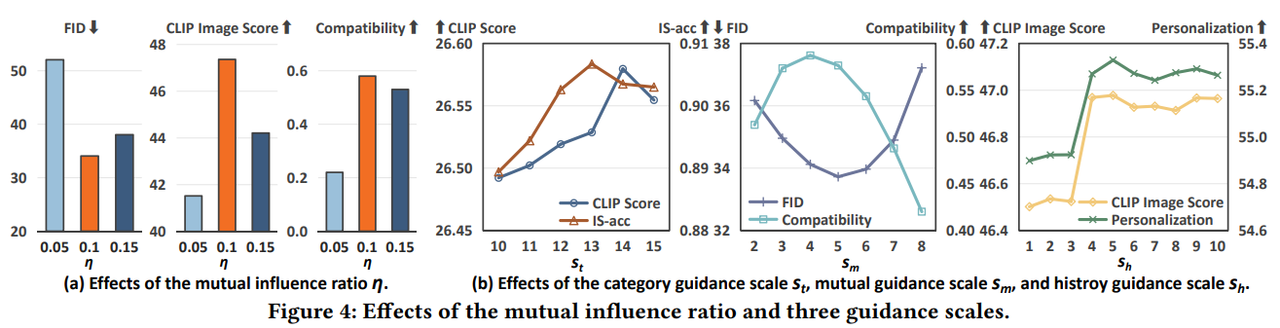
5.4.2 Ablation Study
Mutual encoder에 MLP를 사용하는 것과 그렇지 않은 경우를 비교한 결과, MLP가 없을 경우 호환성과 개인화 성능이 저하되었습니다. 또한 mutual 및 history 조건이 없을 경우, 모델의 호환성 및 개인화 성능이 크게 떨어지는 것을 확인했습니다.
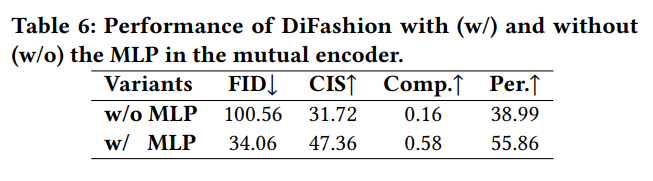
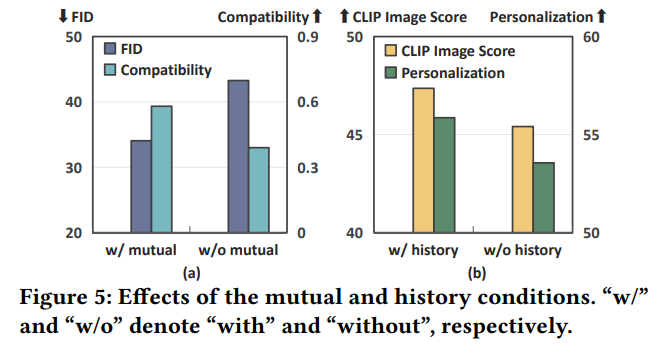
6. Conclusion
본 논문에서는 Generative Outfit Recommendation (GOR) 이라는 새로운 패션 추천 과제를 제안하였으며, 이를 해결하기 위한 DiFashion 모델을 제시했습니다. DiFashion은 Diffusion Models (DMs) 을 기반으로 하여 사용자의 패션 아이템 상호작용 기록과 카테고리 정보를 활용해 새로운 패션 이미지를 생성함으로써, 사용자에게 호환성과 개인화가 뛰어난 코디를 추천합니다.
Contributions:
-
Generative Outfit Recommendation (GOR): 기존의 검색 기반 패션 추천 방식이 아닌, 패션 아이템을 직접 생성하여 사용자에게 추천하는 새로운 추천 과제를 정의하였습니다. 이를 통해 기존의 한정된 패션 아이템 데이터베이스의 제약을 넘어서, 사용자의 취향에 맞춘 새로운 코디를 생성할 수 있는 가능성을 제시했습니다.
-
DiFashion 모델 제안: Diffusion Models (DMs) 에 기반하여, 카테고리 프롬프트, 코디 아이템 간의 호환성을 고려한 mutual condition, 사용자 상호작용 기록을 반영한 history condition을 통합하는 새로운 아키텍처를 설계했습니다. 이 아키텍처는 U-Net을 통해 복잡한 패션 이미지를 효과적으로 생성할 수 있으며, 이러한 조건들이 함께 작용하여 높은 화질, 호환성, 개인화된 추천을 가능하게 합니다.
-
실험적 검증: iFashion 및 Polyvore-U 데이터셋을 사용한 실험을 통해, DiFashion은 다른 생성 모델과 검색 기반 패션 추천 방법들에 비해 우수한 성능을 보였음을 확인했습니다. 정량적 지표뿐만 아니라, 인간 평가에서도 DiFashion이 생성하는 패션 이미지가 더 높은 선호도를 받았으며, 이를 통해 실질적인 응용 가능성을 입증했습니다.
Future Works:
-
속성 기반 제어 강화: 현재 DiFashion은 사용자의 상호작용 기록을 기반으로 전반적인 코디를 생성하지만, 향후에는 사용자가 선호하는 특정 패션 속성 (예: 색상, 패턴)을 더 세밀하게 제어할 수 있는 메커니즘을 연구할 필요가 있습니다.
-
진화하는 패션 트렌드 반영: 패션 트렌드는 지속적으로 변화하므로, DiFashion이 실시간으로 변화하는 트렌드에 적응할 수 있는 방안을 탐구하는 것이 중요합니다. 예를 들어, 소셜 미디어나 패션 잡지의 데이터를 실시간으로 반영하는 모델을 개발할 수 있습니다.
Author Information
- Yiyan Xu: University of Science and Technology of China
- Wenjie Wang: National University of Singapore
- Fuli Feng: University of Science and Technology of China
- Yunshan Ma: National University of Singapore
- Jizhi Zhang: University of Science and Technology of China
-
Xiangnan He: University of Science and Technology of China
- Research Topic:
Generative Outfit Recommendation, Recommender Systems.
7. Reference & Additional materials
- official github repository
- Xu, Yiyan, et al. “Diffusion Models for Generative Outfit Recommendation.” Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2024.
- Ho, J., Jain, A., & Abbeel, P. (2020): “Denoising Diffusion Probabilistic Models.” NeurIPS 2020.
- Ramesh, A., Dhariwal, P., Nichol, A., et al. (2022): “Hierarchical Text-Conditional Image Generation with CLIP Latents.” arXiv preprint arXiv:2204.06125.
- Reed, S., Akata, Z., Yan, X., et al. (2016): “Generative Adversarial Text to Image Synthesis.” ICML 2016.
- Zhu, X., Bain, M., Nam, H., et al. (2022): “Learning to Generate Diverse Fashion Designs from Social Media.” ICCV 2022.
- Chen, H., Ma, Y., Ma, Y., et al. (2019): “Personalized Fashion Recommendation with Neural Networks.” WWW 2019.
- Veit, A., Kovacs, B., Bell, S., et al. (2015): “Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences.” ICCV 2015.
- Kang, W.-C., Fang, C., Wang, Z., et al. (2019): “Visually-Aware Fashion Recommendation and Design with Generative Image Models.” KDD 2019.