[WWW 2024] Can Small Language Models be Good Reasoners for Sequential Recommendation?
1. Motivation
LLM이 NLP task 뿐만 아니라 다양한 task에 대해 좋은 성능을 보여주면서 sequential recommendation에서도 LLM을 활용한 방법들이 나타났다. 지금까지 LLM을 recommendation에 적용하는 방법은 크게 2가지로 나눌 수 있다. 1) LLM을 Item Ranker로 사용하는 방법론들은 zero-shot 또는 few-shot learning을 한 상태에서만 recommendation을 해왔고 이런 상황에서는 기존의 LLM이 traditional recommendation system보다 낮은 성능을 보여주었다. 두 번째로는 LLM을 Knowledge Enhancer로 사용하는 경우인데, 이 경우에 CoT [2]를 활용하면 LLM의 Reasoning Capability를 충분히 활용하면서 좋은 성능을 얻을 가능성이 많다. 하지만 real world 세팅에서 Chat-GPT 규모의 LLM을 recommendation 목적으로 활용하는 것은 매우 많은 resource가 필요하다. 그렇기 때문에 이 논문에서는 Step-by-step Knowledge distillation Framework (SLIM)을 제안한다. 이 방법론에서는 Chat-GPT를 Teacher, 더 작은 사이즈의 LLM을 Student로 하여 Teacher의 Reasoning Capability를 Student로 Distillation 한다. 그리고 최종적으로는 Distilled Student 모델을 deploy하여 real world setting에서 recommendation 할 수 있도록 하는 것이 최종적인 목표이다.
2. Method
이 논문에서 제시하는 Framework인 SLIM은 크게 3단계로 이뤄져있습니다.
-
Knowledge Distillation for Recommendation
-
Recommendation Knowledge Encoding
-
Rationale Enhanced Recommendation
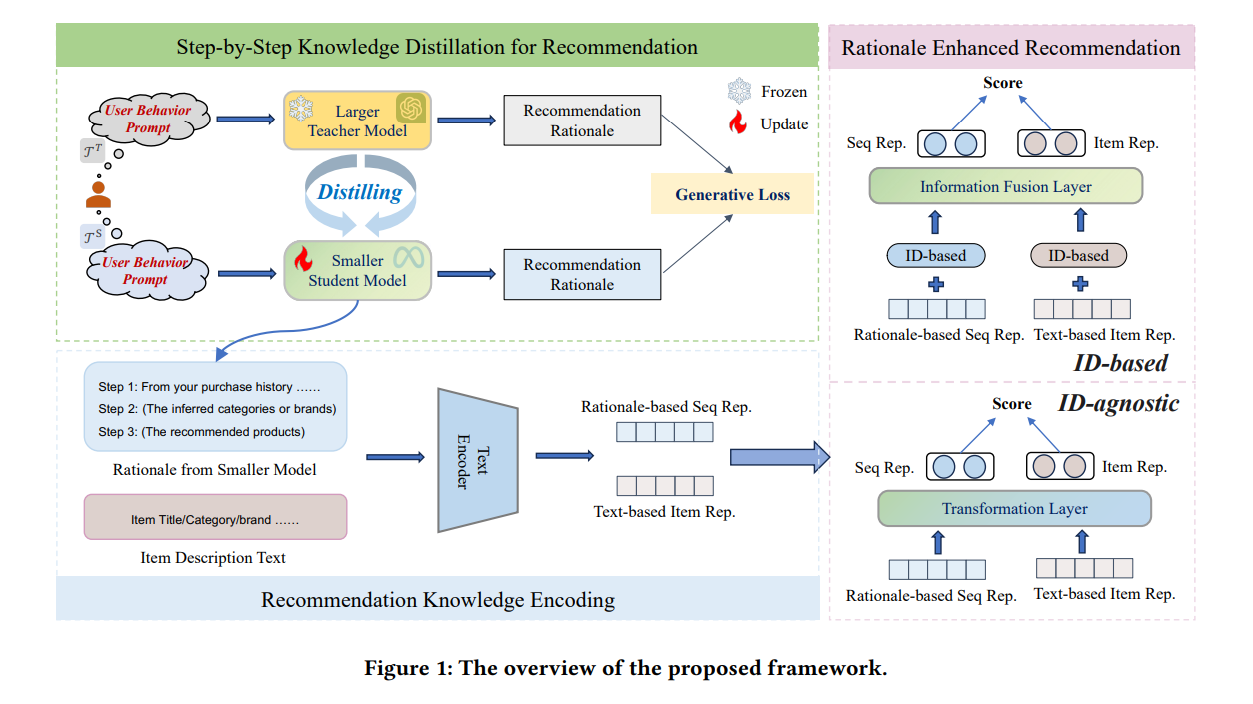
1. Knowledge Distillation for Recommendation
첫 번째 과정에서는 User의 Behavior Sequence를 CoT Prompt에 담아서 Chat-GPT를 사용해 Rationale을 얻습니다. 이 때 CoT의 Prompt는 아래와 같은 논리의 순서로 이뤄져 있습니다.
Step1. User historical sequence를 통해 user의 preference 추론.
Step2. User의 preference를 기반으로 brand와 category 추천.
Step3. brand와 category에 일치하는 item 추천.
위와 같은 Prompt를 통해 Chat-GPT로부터 1. User의 Preference, 2. Recommending Brand and Category, 3. Recommending Item을 최종적으로 얻게되고 해당 논문에서는 전체 결과를 Rationale 이라고 칭합니다. 구체적인 prompt와 그에 대한 Teacher model의 응답 예시는 Figure2를 보시면 됩니다.
Rationale을 사용하여 LLaMA 7B 모델을 Instruction Tuning을 하도록 합니다. Instruction Tuning은 language modeling을 할 때 사용하는 negative log-likelihood loss term을 사용하게 되 식은 아래와 같습니다.
$\mathcal{L}_ {\text{distill}} = \sum_ {u \in \mathcal{U}’} \sum_ {t=1}^{\vert r’_ u\vert} \log \left( P_ {\theta} \left( r’_ {u,t} \mid p’_ {u}, r’_ {u,<t} \right) \right)$
위 식에서 $\mathcal{U}’$ user 전체의 subset, $\mathcal{r’_ u}$는 Teacher에게서 얻은 user $u$에 대한 rationale 결과, $r’_ {u,t}$는 rationale 에서의 t 번째 token. 그리고 $r’_ {u,<t}$ 는 $r’_ {u,t}$ 이전의 token들을 의미합니다.
이 식에서 SLIM은 student model의 parameter인 $\theta$를 학습하게 됩니다.
추가적으로 Instruction Tuning을 할 때 Efficiency를 위해서 LLM 전체를 fine-tuning 하지 않고 PEFT(Parameter Efficient Fine-Tuning method) 중의 하나인 LoRA [3]를 사용합니다.

2. Recommendation Knowledge Encoding
두 번째 과정에서는 첫 번째 과정에서 Distillation 과정을 거친 student 모델을 사용합니다. 이 과정에서는 CoT Prompt를 student 모델에게 주어서 똑같이 User에 대한 rationale을 생성 하도록 합니다. 그리고 Rationale을 Pre-trained Bert 모델을 통해서 Encoding하여 Rationale Embedding으로 표현합니다. 그리고 이와 별개로 추천 대상에 있는 Item들의 Description(e.g., title, category, brand)을 같은 Text Encoder를 통해 Encoding하여 Item Description Embedding을 얻습니다.
$z_ i^{text}= TextEncoder(f_ i)$
$s_ u^{text} = TextEncoder(r_ u)$
$f_ i$ 는 Item i의 description을 의미합니다. $z_ i^{text}$와 $s_ u^{text}$는 각각 Item Description, Rationale의 text embedding을 의미합니다.
3. Rationale Enhanced Recommendation
세 번째 과정에서는 이전에 얻은 Rationale Embedding과 Item Description Embedding을 활용하여 Recommender System을 학습합니다. 이 때 해당 논문에서는 두 가지 구조의 Recommendation Model을 제안합니다. Item의 ID-based 모델과, ID를 사용하지 않는 ID-Agnostic인데, ID-based 경우에는 GRU4Rec, SASRec과 같은 기존 Recommendation System을 backbone으로 두어서 backbone 모델의 Item Embedding과 Item Description Embedding을 결합하고, User Embedding과 Rationale Embedding을 결합합니다. ID-Agnostic 같은 경우는 backbone 모델을 따로 사용하지는 않고 Item Description Embedding과 Rationale Embedding만을 가지고 Recommendation을 하는 형태입니다.
ID-based의 방법론은 아래의 식처럼 text embedding을 Backbone 모델의 Embedding과 결합하는 방법입니다. 결합하여 LInear Layer를 거쳐서 최종적으로 나온 $z_i$와 $s_u$를 활용하여 binary cross-entropy loss로 모델을 학습합니다.
$z_ i = g_ f([g_ l(z^{text}_ i);z^{id}_ i])$
$s_ u = g_ f([g_ l(s^{text}_ u);s^{SeqEnc}_ u])$
[;]는 concatenation operation, $z^{id}_i$는 backbone 모델에서의 Item Embedding, $s_u^{SeqEnc}는 backbone 모델에서의 얻은 User Embedding, $ $g_l$과 $g_f$ 는 LInear Layer를 의미합니다.
ID-agnostic은 Item description, rationale Embedding을 Transformer Layer에 같이 넣어서 모델을 학습합니다. 이 때도 binary cross-entropy loss로 모델을 학습하게 됩니다. ID-agnositc 모델의 경우는 Cold start와 같은 상황에서 더 잘 작동되기 때문에 추가적으로 제안하는 방법론이라고 말하고 있습니다.
$z_ i = g_ t(z_i^{text})$
$s_ u = g_ t(s_ u^{text})$
위 식에서 $g_ t$ 는 transformer layer를 의미합니다.
4. Experiment
Experiment setup
- Dataset
- Amazon Review Dataset (Video Games, Grocery and Gourmet Food, Home and Kichen)
- baseline
- $GRU4Rec$, $SASRec$, $SRGNN$ (이 모델들의 item feature extension 형태로 Item ID vector에 item description text vector를 concattenating 하는 모델들도 baseline으로 추가한다. $GRU4Rec^+$, $SASRec^+$, $SRGNN^+$)
- Ablation Study의 일종으로 $SLIM^-$는 distillation 과정을 거치지 않고 Chat-GPT의 결과를 그대로 사용한 모델이다.
- Evaluation Metric
- NDCG@10, Hit Rate@10, Hit Rate@20
- Evaulation을 할 때는 Random Negative Sample 100개를 주었고, 5번 실험을 하여 평균값과 표준편차 값을 측정하였다.
Result
이 논문에서의 실험은 SLIM의 추천 성능 관련 실험과 해당 Framework의 여러 장점들에 대해 설명하는 실험으로 구성되어 있습니다.
ID-based SLIM의 성능 실험에서는 각 Backbone recommendation system과 각 backbone 모델을 사용한 SLIM의 성능을 비교하여 얼마만큼의 Improvement가 있는지를 비교한다. 실험 결과를 보면 SLIM의 방법론이 효과적이라는 것을 알 수 있습니다. item feature extension을 포함한 backbone 모델과 비교했을 때 consistent한 성능 향상이 있습니다. 그리고 대부분의 실험 결과에서 $SLIM^-$보다 $SLIM$ 모델의 성능이 높게 나왔다. 이러한 실험 결과에 대해 논문의 저자들은 distillation 과정에서 student model이 recommendation에 관련이 높은 결과를 주도록 학습되었다고 설명합니다.

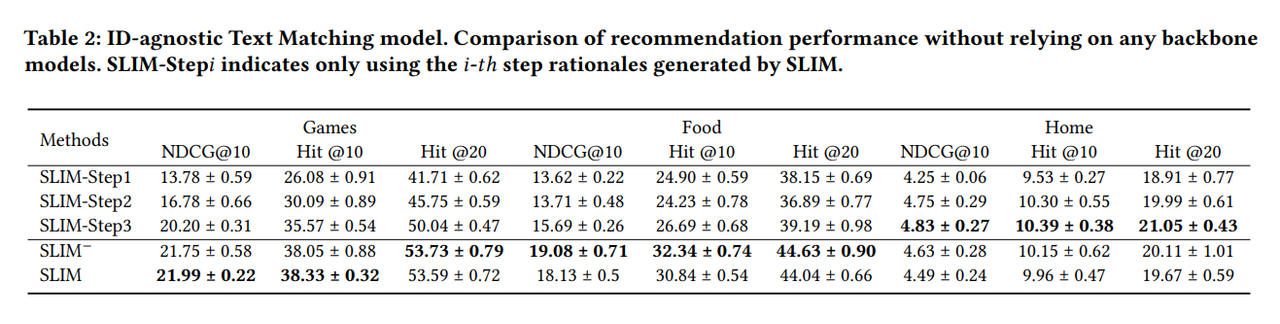
ID-agnostic SLIM의 성능 실험에서는 앞서 설명했던 것 처럼 backbone recommendation system을 사용하지 않습니다. 이 실험에서는 직접적인 baseline과의 비교는 없지만 SLIM에서 사용하는 CoT 방법에 대한 이해도를 높이기 위해 ablation model을 만들었습니다. 해당 논문에서 사용한 CoT prompt에는 3 단계의 reasoning을 거쳐 추천을 하는데 각 단계의 결과만 사용을 해서 추천하는 $SLIM-Step$ 모델과 성능을 비교하게 됩니다. 실험 결과 테이블을 보면 SLIM이 대부분의 결과에서 outperform을 하는 것을 알 수 있고 SLIM-Step 모델들은 살짝 낮은 결과를 보여줍니다. 특히 SLIM-Step1, 2 는 성능 차이가 많이 나는데 각 단계에서의 macroscopic information를 활용해서 추천 아이템을 특정하는 것은 어렵기 때문이라고 설명합니다.
위 2가지의 메인 실험 외에도 논문에서는 SLIM의 장점에 대해 explore하는 Ablation 및 추가 실험들을 제시하고 있습니다. 크게 3가지로 1) CoT 결과로 인한 Recommendation의 Interpretability, 2)Dataset Sparsity에 대한 robustness, 3) Popularity Bias Mitigation 에 대해서 SLIM이 기존 모델들보다 좋다는 것을 뒷받침 하는 실험과 결과 해석이 포함되어있습니다.
5. Conclusion
이 논문에서는 LLM에 CoT Prompting 방법을 사용해서 추천에 관련성이 높은 정보를 뽑아냈고 이를 distillation 과정을 통해서 real world 에서도 affordable한 방법론을 제시했다. 그리고 CoT로 뽑은 정보를 Recommendation System과 잘 결합하여 Sequential Recommendation 성능이 올라가는 것을 실험으로 잘 보여주었고 SLIM이 가지는 여러 장점들을 보여주는 실험 또한 제시하였다.
개인적인 의견으로는 저자들이 LLM Recommendation 방법론들의 실제 활용에서 생기는 문제점, 기존 LLM Recommenadtion 방법론이 성능이 좋아도 성능과 비용 문제로 인하여 적용하기는 어렵다 라는 것은 산업 분야에서도 중요하기 때문에 중요한 문제를 잘 잡아냈다고 생각합니다. 그리고 해당 문제를 distillation이라는 방법으로 효과적으로 해결할 수 있다는 것을 보여주어 좋은 방법론을 제시했다고 생각한다. 한 가지 조금 더 develope을 해볼 수 있는 부분도 있을 것이라고 생각한다. LLM과 CoT로 user preference, recommend category, item 등 복잡한 형태의 문장을 뽑아내고 해당 문장은 Bert를 통해 encoding을 한다. 이 과정에서 단순히 한 개의 Token Embedding으로 뽑아 압축시켜버리면 information loss가 크고 Reasoning된 결과가 효율적으로 반영되기 어려울 것 같다는 예상이다. Reasoning된 결과를 통해 단계적으로 Recommendation System과 결합하거나, Long Sentence의 Semantic 보존에 대한 추가적인 고민과 방안이 있으면 좋지 않을까 하는 생각이 있다.
Author Information
-
Author - 강홍석 (HongSeok Kang)
-
Affiliation - KAIST DSAIL
-
Research Interest - Recommendation System, Tabular Learning
6. Reference & Additional materials
[1] Wang, Y., Tian, C., Hu, B., Yu, Y., Liu, Z., Zhang, Z., … & Wang, X. (2024, May). Can Small Language Models be Good Reasoners for Sequential Recommendation?. In Proceedings of the ACM on Web Conference 2024 (pp. 3876-3887).
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
[3] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., … & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.