[RecSys 2021] Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Title
[RecSys 2021] Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
1. Problem Definition
음악 스트리밍 서비스에서의 추천 시스템
음악 스트리밍 서비스들은 사용자가 관심있는 아티스트와 유사한 아티스트의 리스트를 추천하여 사용자의 음악 체험을 강화하고 새로운 음악을 발견하는데 도움을 준다. 이러한 추천은 “Fans Also Like”이나 “Similar Artists”와 같은 명칭으로 불리며, 아티스트 간의 공유된 유저나, 아티스트에 대한 유저 선호도를 기반으로 예측되는 Collaborate Filtering 과 같은 Usage Data(스트리밍 이력, 좋아요 등)로 유사도 측정을 진행한다. 하지만, 관련한 연구들 중 기존 연구들에서는 몇 가지 문제점들이 도출될 수 있다.
-
Collaborative Filtering의 한계와 Cold Start 문제
기존의 Collaborative Filtering은 사용자의 과거 상호 작용을 기반으로 아티스트나 item들의 유사도를 계산한다. 하지만, 신규 Artist들, 특히 처음 음원을 발매한 User들은 추천시스템에 공급될 만한 충분한 Usage Data를 확보하기가 힘들다. 이러한 상호작용의 부족은 결국, 이들을 추천시스템에서 배제하게 됨을 야기하고, 이로 인해 이들은 Fans Also Like과 같은 추천 페이지에서 제외될 수 있다. 더불어 이러한 Usage Data 중심의 접근법은 최소한의 상호작용 데이터를 가진 일부 기존 Artist들조차도 추천에서 제외시킬 수 있어 공정성에 대한 문제를 야기할 수 있다.
-
Hybrid 모델과 그 한계점
이러한 문제를 극복하기 위해, 아이템 설명 및 Collaborative Filtering 기반 추천을 결합하는 하이브리드 모델이 제안되었다. 이러한 모델들은 warm 아이템의 벡터 표현을 학습하고, 이를 기반으로 cold 아이템을 프로션한다. 그러나 이러한 모델들은 그래프 정보를 사용하지 않으며, 이에 따라 복잡한 아티스트 간의 관계나 아티스트의 다양한 속성을 완전히 반영하지 못한다.
-
그래프 기반 추천의 등장 및 한계점
이러한 복잡하고 다양한 상호작용을 표현하기 위해 그래프 기반 추천 모델이 등장했다. 그래프 기반 추천은 아티스트나 음악 간의 관계를 그래프로 표현하여 추천의 정확도를 높이려는 시도이다. 하지만 기존 대부분의 연구에서 그래프 기반 추천 알고리즘은 방향성이 없는 그래프(undirected graph)를 사용하였고, 아티스트 간의 복잡한 관계를 완전히 반영하지 못했다. 또한, 기존 연구에서는 아티스트 간의 유사도만을 계산하였다. 이는 사용자에게 순위별로 아티스트를 추천하는 ranking system의 부재에 대한 문제가 있을 수 있다.
-
문제 정의
Collaborative Filtering, 하이브리드 모델, 그래프 기반 추천 모두 Cold Start 문제 및 그래프의 복잡성, 순위 기반 추천의 부재 등 여러 한계점을 가지고 있다. 이를 해결하기 위해, 방향성이 있는 그래프(directed graph)와 ranking system을 어떻게 효과적으로 결합할 수 있을지 연구한다.
주요 연구 질문: 방향성이 있는 그래프와 ranking system 결합을 통해 Cold Start 문제와 다양한 아티스트 간의 관계를 어떻게 효과적으로 반영하여 추천할 수 있을까?
2. Motivation
-
Directed Graph Autoencoder Architecture 도입: Directed Graph를 사용하여 Node Embedding Representation을 하는 방식을 고안하고, 추천 시스템 문제에 적용하여 그 효과를 분석하였다. 이 방법은 기존의 Undirected Graph 방식에 비해 양방향의 상호작용을 고려하여 더 정교한 관계 모델링을 가능하게 하며, Cold Start Similar items ranking 문제를 directed link prediction task로 변환하여 새로운 해결 방안을 제시한다.
-
Gravity-inspired mechanism 도입: Node Embedding과 함께 중력에 영감을 받은 Autoencoder와 Variational Autoencoder 구조를 활용하여, Edge(link) 예측에 활용한다. 이 접근법은 기존의 방법론과 달리 물리학적 원리를 차용하여 더욱 독창적이고 효과적인 예측 모델을 제공한다.
-
Weighted Edge & Ranking: $n \times n$ similarity Matrix $S$에서, Edge를 $S_{ij} \in [0,1]$의 가중치를 두어서 모델의 ranking까지 고려하였다. 이러한 가중치 부여 방식은 모델의 성능과 정확도를 향상시키는 데 중요한 역할을 한다.
-
Artist의 Feature Vector에 대한 임베딩 방식 제안: Genre, Country, Mood 등을 고려하여, Artist를 $d = 56$ 차원으로 임베딩하는 방식을 제안하였다. 이 임베딩 방식은 아티스트의 다양한 특성을 포괄적으로 반영하여, 더욱 정밀한 추천 시스템 구축에 기여한다.
-
다른 산업들로 확장 가능성: Cold Start 문제를 해결함으로써, Music Streaming 외의 Video 등의 Cold Start 문제가 발생하기 쉬운 산업으로 확장 가능하다. 예를 들어, 영화 추천 시스템에서도 이 방법론을 적용하여 사용자의 선호도를 더 정확하게 파악할 수 있다.
-
실제 데이터 사용 및 코드 배포: 연구실 환경이 아닌, 실제 사용자들이 Interaction하는 환경에서의 데이터셋을 활용하였고, 관련 코드를 배포하여 이후 연구에 도움이 될 수 있다. 이는 연구의 실용성을 높이고, 연구 커뮤니티에 실질적인 기여를 하는 중요한 단계이다.
3. Method
Overview
이 논문에서는 추천시스템 문제를 신규 아티스트를 new node로 가정하고, 상호작용이 없는 그 node에 대해 그래프에서 edge들이 mask 되어 있다고 가정하고, 이 edge들을 예측하는 문제로 치환하였다. 이를 모델링하기 위해, 먼저 아티스트 노드를 임베딩하는 과정을 거친 후, missing edge와 그것의 weight가 나올 확률을 예측하는 과정을 거친다. 이 과정을 수행하기 위해, 이 논문에서는 Gravity-Inspired Graph AE(Autoencoder)와 Gravity-Inspired VAE(Variational Autoencoder)을 소개한다. 이 둘은 공통적으로 Autoencoder의 구조를 사용하는데, encoder부분은 GCN, decoder 부분에서는 Gravity-inspired decoder 구조를 사용한다. 즉, 인접행렬 $A_{ij}$와 특징을 담은 행렬 $X_f$ 를 모델의 Input으로 넣고 $\tilde{z}$라는 벡터로 노드들을 임베딩 시키며 GCN Encoder 부분을 학습하고, 이를 이용하여 다시 $\hat{A}_{ij}$ 를 복원하는 과정으로 Gravity-inspired decoder 부분을 학습시킨다. 해당 수식을 다음과 같다.
$\tilde{Z} = GNN(A,X)$, then $\forall{(i,j)} \in {1, …, n}^2, \hat{A_{ij}} = \sigma(\tilde{m}_j - log\vert \vert z_i - z_j \vert \vert _2^2).$
Graph Setting
-
directed : 비대칭적인 관계를 표현하기 위해 디자인되었다. 예를 들어, 남자 댄스 신인 아이돌의 노래를 듣는 사람은 남자 댄스 인기 아이돌인 방탄소년단(BTS)의 노래를 들었을 가능성이 매우 높지만, 반대의 경우인 BTS의 노래를 듣는 사람이 그 댄스 신인 아이돌의 노래를 들었을 가능성은 매우 적다. 이로 인해, 아티스트간의 비대칭적인 관계는 표현되어야한다. 이에 따라 일반적으로 인접행렬 $A$에서 $A_{ij} \ne A_{ji}$이다.
-
weighted : 본 논문에서는 한 아티스트는 top-k의 edge를 갖고 있다고 가정하였다. 특히 k=20일때를 가정하고 모델을 디자인하였다. 이러한 top-k의 edge들에 weight를 주었고 이는 Similarity score $S_{ij} \in [0,1]$와 같다. 따라서 node $i$가 node $j$와 top-k의 관계가 있을 때 $A_{ij}=S_{ij}$ 이고, 그렇지 않다면, $A_{ij}=0$이다.
-
attributed : 각각의 node $i$ 는 $x_i \in \R^f$의 Vector로 표현된다. 특히, 이 논문에서는 f를 총 56의 dimension을 가진 feature들로 가정하였다. 이는 300개가 넘는 음악 장르를 SVD(Singular Vector Decomposition)을 통해 32개의 차원으로 줄인 32-dimensional $genre$ vector와 그 artist의 country(top 19개의 나라 및 기타)를 나타내는 20-dimensional $country$ vector, 그리고 곡의 분위기(Positive or Negative / Calm or Energetic)를 나타내는 4-dimensional $mood$ vector를 Concatenation 해서 만들어낸다.
Network : Gravity-Inspired Graph (Variational) Autoencoder
-
Node Similar Estimation
Encoder를 거친 Embedding vectors $z_i$ , $z_j$ 의 유사도를 계산하여 $\hat{A_{ij}}$를 구할 수 있다. 하지만, 현재까지의 대부분의 방식은 $\vert \vert z_ i - z_ j\vert \vert_ 2$ 혹은 $z_ i^T z_ j$ 를 사용한다. 하지만 이는 두 node의 유사도가 symettric 하다는 가정이 전제되어있고, 일반적으로 $A_ {ij} \ne A_ {ji}$ 인 상황을 고려할 수 없다. 이에 따라, 이 논문에서는 중력에서 영감을 받은 방식을 도입하여 이를 해결한다.
-
Gravity-inspired Graph Autoencoder
중력은 두 객체가 있을 때, 그것들의 질량과 거리에 의존한다. 이에 대한 식은 흔히 알고 있듯이 $a_{1\rightarrow2}=\frac{Gm_2}{r^2}$, 있듯이 $a_{2\rightarrow1}=\frac{Gm_1}{r^2}$이다. 이 논문에서 질량 $m_1$이 의미하는 바는 인기가 많은 아티스트라고 생각할 수 있다. 예를 들어, 인기 남자 아이돌인 방탄소년단(BTS)는 그 질량이 매우 커서, 다른 노드들을 훨씬 더 쉽게 끌어당길 수 있다. 반면, 신인 남자 아이돌 그룹은 다른 아티스트들을 끌어당기기에는 그 힘이 상대적으로 부족하다. 또한, 거리는 두 아티스트의 유사도와 관련이 있다. 위의 상황에서 남자 아이돌 방탄소년단과, 신인 남자 아이돌 그룹은 꽤나 비슷한 벡터로 표현이 될 수 있고, 이 때문에 둘의 유사도(본 논문에서는 유사도를 위해 $\vert \vert z_i - z_j\vert \vert _2$를 활용)는 매우 높다고 할 수 있다. 결국 이 둘을 모두 고려하여 연관성을 고려한다면, 서로의 질량에 의해 Symmetry 문제를 해결할 수 있고, 인기도(질량)과 유사도(거리)를 모두 반영하여 계산할 수 있다. $Gm_j$는 $\hat{m}_j$로 denoted 될 수 있다. 또한 $\sigma(x) = 1/(1+e^{-x}) \in (0,1)$인 sigmoid function에 해당한다. 이에 대한 식은 다음과 같다.
$\hat{A}_ {ij} = \sigma(log(a_ {ij})) = \sigma(log\frac{Gm_ j}{\vert \vert z_ i-z_ j\vert \vert_ 2^2}) = \sigma(logGm_ j - log\vert \vert z_ i-z_ j\vert \vert_ 2^2)$
log에 대한 이유는 중력(인기도)에 대한 가속도를 어느정도 제한해주기 위함이다. 또한, 이 네트워크를 설계할 때, GCN encoder 부분에서는 64-dim을 가진 2개의 hidden layer를 활용했고, 33-dim(32-dim $z_i$ + 1-dim for a mass)의 output layer를 갖는다. 또한 loss는 train session동안 Cross Entropy Loss를 활용했고, 300 epoch를 반복하며 훈련을 진행했다. Optimizer는 Adam, Learning rate는 0.05, 그리고 full-batch GD를 활용했다.
-
Gravity-inspired Graph Variational Autoencoder
Variational Autoencoder가 Autoencoder와 다른 부분은 결과값들을 고정된 값이 아닌 확률 분포로서 해석을 한다는 것이다. 본 논문에서는 Gaussian 분포를 가정하고 문제를 해결했다. 이에 따른 encoder 식은 다음과 같다. $q(\tilde{Z}\vert A,X) = \prod_{i=1}^{n}{\prod_{j=1}^{n}{p(A_{ij}\vert \tilde{z}_i, \tilde{z}_j)}}$, with $q(\tilde{z}_i\vert A,X)$ = $\mathcal{N}(\tilde{z}_i\vert \mu_i, diag(\sigma_i^2))$. 이러한 식으로 인코더 부분을 학습하고, 디코더 부분인 Acceleration Formula(Edge Prediction)은 다음 수식과 같다. 또한, 훈련 중에는 두 GNN 인코더에서는 가중치가 Gradient Descent를 사용하여 모델의 liklihood의 variational lower bound(ELBO)을 최대화함으로써 조정된다.
$p(A\vert \tilde{Z}) = \prod_ {i=1}^{n}{\prod_ {j=1}^{n}{p(A_ {ij}\vert \tilde{z}_ i, \tilde{z}_ j)}}$, with $p(A_ {ij} \vert \tilde{z}_ i, \tilde{z}_ j) = \hat{A}_ {ij} = \sigma(\tilde{m}_ j - log\vert \vert z_ i - z_ j\vert \vert_ 2^2)$
Cold Item Ranking using Gravity-Inspired Network
-
Encoding Cold Nodes with GCNs.
본 논문에서는 Encoding layer로 그래프의 구조적 특성을 반영하기 위해 GCN을 도입했다. 특히나, 그 hidden layer는 2개로 설정했다. 그에 따른 식은 다음과 같다.
For AE : $\tilde{Z} = \tilde{A}ReLU(\tilde{A}XW^{(0)})W^{(1)}$ For VAE : $\mu = \tilde{A}ReLU(\tilde{A}XW_{\mu}^{0})W_{\mu}^{(1)}, log (\sigma) = \tilde{A}ReLU(\tilde{A}XW_{\sigma}^{(0)})W_{\sigma}^{(1)}$
-
Ranking Simliar Items.
위에서 Encoding된 Cold Item에 대해 Ranking을 측정하는 방법은 다음과 같다. 먼저, cold node룰 추가한 그래프(matrix)라고 생각하고, 그 node도 warm node이지만 edge masked 되어있다고 가정하고 이것을 predict하는 작업이다. 역시나 decoder로는 gravity-inspired decoder구조를 사용한다. 그 식은 아래와 같다.
$\hat{A}_{ij}. = \sigma(\tilde{m}_j - \lambda \times log \vert \vert z_i - z_j \vert \vert _2^2)$
다만, 앞서 언급한 식과 다른 점은 hyperparameter인 $\lambda$를 사용했다는 것이다. 만약 $\lambda\rightarrow0$으로 세팅하면, 질량에만 의존해 관계를 예측하고, 그것을 통해 추천을 진행하게 된다. 이는 추천에 인기도만을 반영한다는 것과 유사하다. 반면, $\lambda$를 증가시키면 그것의 인기도에 비해, node간의 proximity를 더 많이 고려하게 된다. **이 논문에서는 NDGG@200에서 41.42%로 성능이 가장 좋게 나온 $\lambda$=5로 가정하고 진행하였다. 관련된 hyperparmeter 실험 결과는 아래와 같다.
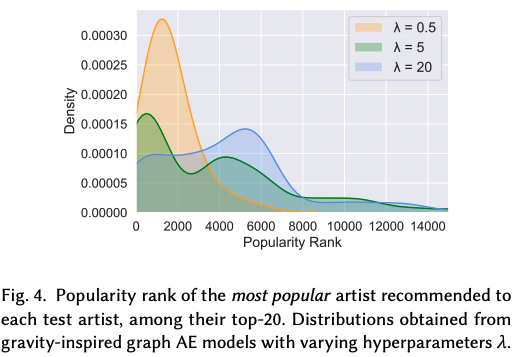
4. Experiment
Experiment setup
- Dataset
Deezer 음악 스트리밍 서비스에서 추출된 24,270명의 아티스트로 구성된 방향성 그래프이다. 아티스트는 그래프에서 𝑘 = 20명의 다른 아티스트를 향하고 있다. 이는 내부 비즈니스 규칙에 따라 동일한 그래프에서 “팬들도 좋아하는/비슷한 아티스트” 기능의 top-20 아티스트에 해당한다.
- Edge Weight 각 방향성 엣지(𝑖, 𝑗)는 [0, 1] 세트 내에서 정규화된 가중치 $A_{ij}$를 가진다. 연결되지 않은 쌍의 경우 $A_{ij}$ = 0이다. 이것은 매주 Deezer 사용자의 사용 데이터를 기반으로 계산된 아티스트 𝑗의 유사성 점수에 해당한다. 가중치는 아티스트 스트림 간의 상호 정보 점수를 기반으로 한다. 대략적으로, 사용자가 두 아티스트를 함께 들을 확률과 서비스에서의 그들의 청취 빈도를 비교하며, 아티스트 수준에서 내부 휴리스틱과 특정한 비즈니스 규칙을 통해 정규화된다.
- Other 실제 Deezer 앱에서는 아티스트의 추가적인 정보, 예를 들어 오디오나 텍스트로 된 설명 등을 수집한다. 하지만, 이러한 추가적인 정보는 이 실험에서는 사용되지 않았고 노출되지도 않았다.
- Baseline
- Directed Artist Graph를 사용한 Baseline Methods
- Standard AE/VAE Model. (Not Gravity-inspired). Gravity-inspired decoder 대신, Symmetric inner-product decoder 구조를 사용한다. 그 식은 따라서 $\hat{A}_{ij} = \sigma(z_i^T z_j)$이 되고, 이 때문에 이 그래프는 방향성을 잃고 Symmetric 해진다.
- Source-target graph VE/VAE. 본 연구에서 사용한 model과 비슷하지만, 이 모델은 32-dim vector $z_i$를 source vector $z_i^{(s)}=z_{i[1:16]}$ 과 target vector $z_i^{(t)}=z_{i[17:32]}$로 나눈 후, $\hat{A}_ {ij} = \sigma(z_ i^{(S)T} z_ j^{(t)})$와 $\hat{A}_ {ji} = \sigma(z_ j^{(S)T} z_ i^{(t)})$로 유사도를 예측한다. 따라서, 이는 방향성을 띄는 그래프를 나타낸다. 하지만 그 방식에서 gravity-inspired와는 다른 경향을 띈다.
- DEAL Model 본 연구에서 Base가 된 Model이다. 그래프에서 아직 연결되지 않은, 새로운 노드 간의 연결관계나 링크를 예측하기 위해 설계되었다. 이는 새로운 node의 특성을 반영하여 아직 연결되지 않는 새로운 edge를 예측하기 위해 설계되었다.
- Other Baselines:
- Popularity: Deezer에서 top-𝐾 아티스트를 추천한다.
- Popularity by Country: Cold 아티스트의 국가에서 top-𝐾 아티스트를 추천한다.
- In-degree: 그래프에서 가장 높은 in-degree를 가진 top-𝐾 아티스트를 추천한다.
- In-degree by Country: Cold 아티스트의 국가의 warm 아티스트에 대해 In-degree 방식을 사용한다.
- K-NN: 가장 가까운 𝑥𝑖 벡터를 가진 top-𝐾 아티스트를 추천한다.
- K-NN + Popularity & K-NN + In-degree: 가장 가까운 $x_i$ 벡터를 가진 200 아티스트를 검색하고, 인기도나 in-degree 값에 따라 그 중 top-𝐾 아티스트를 추천한다.
- SVD+DNN: “Embedding + mapping 전략”을 사용하여 SVD를 계산하고, 딥러닝을 통해 cold 아티스트를 임베딩에 투영한다.
- DropoutNet 및 STAR-GCN: 이 데이터셋에서 가장 우수한 성능을 보이는 두 가지 딥러닝 접근법이다.
- Directed Artist Graph를 사용한 Baseline Methods
-
Evaluation Metric
아티스트들은 Train/Validation/Test Set으로 나뉘며 8:1:1로 나뉜다. Train set에서 아티스트들은 warm node로 구성되고, Validation/Test Set에서는 Cold Node로 Making 된 엣지와 고립된 그 Node들을 관측한다. 평가는 모델의 Autoencoder구조를 사용한만큼, Edge 복구 능력에 대해 평가하면서, 올바른 Ranking 순서를 유지하는 지를 살펴본다.
- Metric
- Recall@K: 다양한 𝐾 값에 대해, 실제 유사한 아티스트 20명 중 어느 비율이 추정된 가중치가 가장 큰 상위 K 아티스트 중에 나타나는지 나타낸다.
- MAP@K (Mean Average Precision at 𝐾): 랭킹의 품질을 나타내는 지표로, 순위를 정할 때의 평균 정확도를 나타낸다.
- NDCG@K (Normalized Discounted Cumulative Gain at 𝐾): 랭킹의 품질을 나타내는 지표로, 상위 랭크에 대한 정보의 가치를 최적화하려고 할 때 사용된다.
Result

Perfomances
- Popularity와 In-degree는 worst baseline으로 나타났고, 이에 비해 국가기반 추천은 훨씬 좋은 성과를 내었다. (e.g. Popularity : Popularity by country = 0.44 : 12.38 in Recall@100)
- 단순히 KNN에 기반한 방법들은 다른 Usage Data(Interaction Data)를 활용한 다른 방법들에 비해 성능이 떨어졌다.
- DropoutNet과 DEAL 모델은 SVD+DNN과 STAR-GCN보다 더 좋은 결과를 보였고 Standard AE/VAE보다도 높은 성능을 보였다.
- VAE 방법은 일반적인 모델들에서는 더 좋은 성능을 보였지만, 본 연구에서 사용된 Gravity-inspired 모델에서는 그렇지 않았다.
- 궁극적으로, 본 연구에서 사용한 Gravity-inspired Graph AE/VAE가 가장 좋은 성능을 보였다.
On the mass parameter
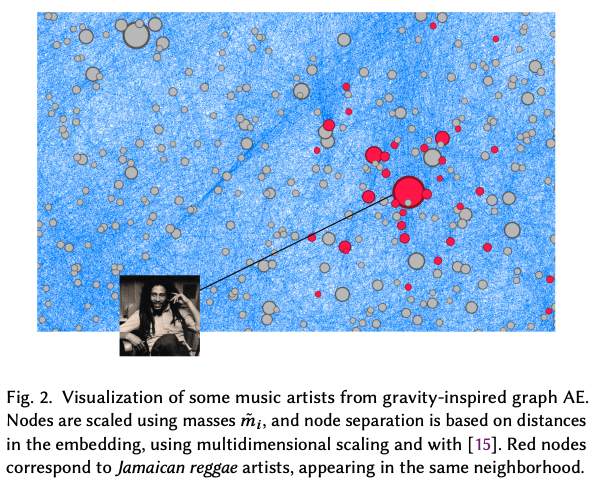
-
질량은 인기도 및 그래프 기반 노드 중요도와 양의 상관관계를 가지지만, 완벽하게 일치하지는 않는다. 이에 따라, 이 모델로 질량을 완벽하게 학습할 수는 없다는 것을 의미한다.
-
만약 $\tilde{m}_i$ 를 고정시키고, $z_i$만을 최적화해서 다시 측정을 해보면 performance가 감소한다. 이에 따라, $\tilde{m}_i$와$z_i%$ 를 함께 학습하는 것이 최적이라는 것을 알 수 있다.
-
또한, 질량의 크기는, county나 genre 등에 의한 Local influence에도 영향을 받는다. (e.g. samba/pagode Brazilian artist Thiaguinho는 Deezer에서 top-100이지만, top-5인 Ariana Grande보다 그 질량이 크다.)
Impact of Attributes
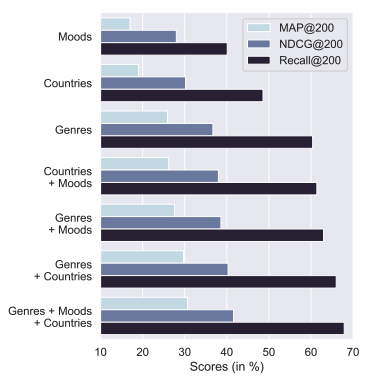
이 논문에서는 $z_i$를 최적화하기 위해 세가지의 벡터(Mood, Country, Genre)를 Concat해서 사용하였다. 이에 대한 설명력을 해석했고, 그 특징중 하나만 사용한다면 Genre를 사용했을 때가 가장 높았다. 또한, 세가지의 정보를 모두 사용하는 것이 최고의 성능을 제공함을 확인했다.
5. Conclusion
본 연구는 음악 추천에서 콜드 스타트 유사 항목 랭킹 문제를 Directed 그래프로 모델링하는 새로운 시도를 제시하였다. 또한 중력에서 영감을 받은 Gravity-inspired Graph Autoencoder의 도입은 이 연구의 핵심 구성요소라고 생각하고, 그래프 내에서 비슷한 아티스트의 랭킹을 예측하는 문제를 해결하는 데에 중요한 역할을 했다.
이 접근법의 미묘함은 추천 시스템을 그래프의 masked edge 예측 문제로 재구성하는 데에 있다고 생각한다. 특히 유사도에 중력 개념을 적용하여, 지향성 있는 그래프의 아이디어는, 아티스트 간의 관계와 그들이 서로에게 어떻게 영향을 주는 지에 대한 복잡성을 조금 더 세밀하게 포착할 데 있었다. 이는 기존의 방식보다 이러한 관계를 훨씬 구체적이고 섬세하게 나타낼 수 있게 해준 것 같다.
또한, Gravity-inspired 접근법의 도입은 추천의 복잡성에 근본적인 변화를 가져올 수 있는 미래 지향적인 접근법이 될 수 있다고 생각한다. 또한, 이 연구에서는 그 강도까지 함께 포착하여 더욱 정확한 랭킹 추천까지 가능하게 한다.
물론, 이 연구에서도 개선의 여지가 있는 부분이 있다. 특히, 사용자의 선호도가 consistent 하지 않는다는 점이다. 이를 위해 선호도 변화와 연관된 Dynamic Graph Embedding의 도입과 같은 것들을 활용할 수 있다.
더 나아가, 현재 연구에서는 아티스트의 유사도 계산에 중점을 두었지만, 사용자의 상호작용을 더 깊이 반영할 수 있다면 더욱 향상된 추천 결과를 기대할 수 있다. 예를 들어, 사용자의 검색 기록이나 ‘좋아요’ 기록 등을 활용하여 Multi-modal 형태의 추천 시스템을 제안할 수 있다. 이러한 접근은 사용자의 다양한 행동 양식을 반영하여 더욱 개인화된 추천을 가능하게 할 것이다.
마지막으로, 중력을 사용한 아티스트 모델링 방식처럼, 사용자 역시 행성과 같은 모델로 표현하는 것이 가능할지에 대한 고민은 흥미로운 접근이다. 이는 사용자와 아티스트 간의 상호작용을 물리적 현상으로 모델링하여, 보다 직관적이고 혁신적인 추천 시스템을 구축하는 데 기여할 수 있을 것이다. 그러나 이러한 접근이 실제로 효과적인지에 대해서는 추가적인 연구와 실험이 필요할 것으로 보인다.
더불어, 본 연구에서 제공하는 다양한 통찰력과 Gravity-inspired Autoencoder라는 방법론을 통해, 그래프 기반 추천시스템의 성장을 촉진하는데 큰 도움을 줄 수 있을 것 같고, 이를 통해 더욱 정교하고 개인화된 음악 추천을 가능하게 할 수 있다.
Author Information
- Author name
- 이주찬 (Juchan Lee)
- GSDS(Graduate School of Data Science) in KAIST
- Business Analytics, Computer Vision, Graph Representation Learning
- Github Link
- Authors in this paper
- GUILLAUME SALHA-GALVAN∗, Deezer Research & LIX, École Polytechnique, France
- ROMAIN HENNEQUIN, Deezer Research, France
- BENJAMIN CHAPUS, Deezer Research, France
- VIET-ANH TRAN, Deezer Research, France
- MICHALIS VAZIRGIANNIS, LIX, École Polytechnique, France
6. Reference & Additional materials
- Github Implementation
- Reference